Clear Sky Science · sv
Asymmetri i strukturella fel och skadeviktad analys av ChatGPT kontra IVA-läkare vid syra–bas‑tolkning: en prospektiv observationsstudie
Varför denna studie är viktig för vardagsläsaren
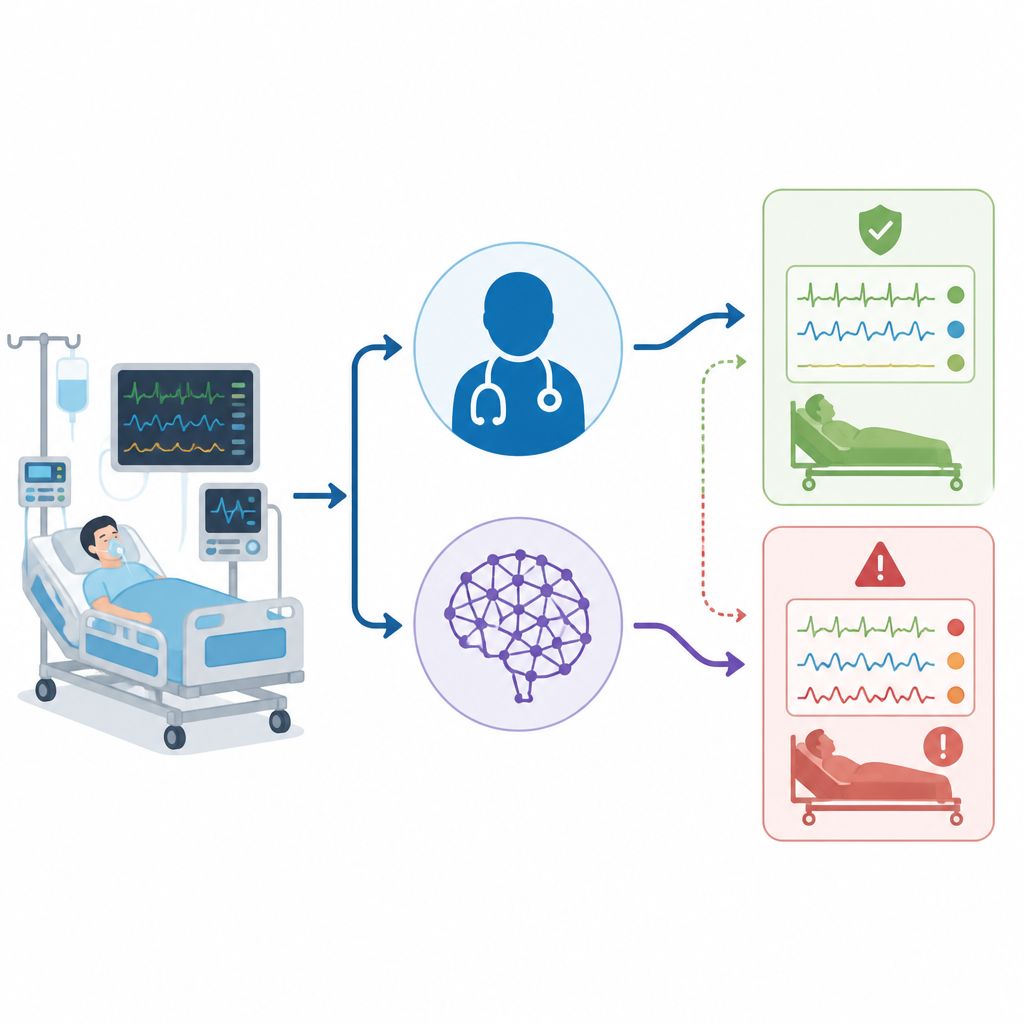
Sjukhus provar i allt högre grad artificiell intelligens för att stödja läkarnas beslut, särskilt på trånga intensivvårdsavdelningar. Denna studie ställer en enkel men avgörande fråga: när ett datorprogram som ChatGPT hjälper till att tolka ett mycket känsligt blodprov som styr livräddande behandlingar — är dess misstag lika ofarliga som de misstag erfarna IVA‑läkare gör, eller kan de tysta dölja allvarliga problem?
Blodprovet i berättelsens centrum
Forskningen fokuserar på arteriella blodgaser, som mäter hur surt blodet är och hur väl en patient andas och får syre. På intensivvården hjälper dessa resultat läkarna att avgöra om man ska justera respiratorn, ge vätska eller ändra läkemedel. Mönstren kan vara enkla, till exempel ett huvudproblem med andning eller ämnesomsättning, eller komplexa, där flera störningar förekommer samtidigt. Dessa ”blandade” mönster är vanliga hos mycket sjuka patienter och kan signalera att kroppen kämpar på flera fronter samtidigt.
Hur jämförelsen gjordes
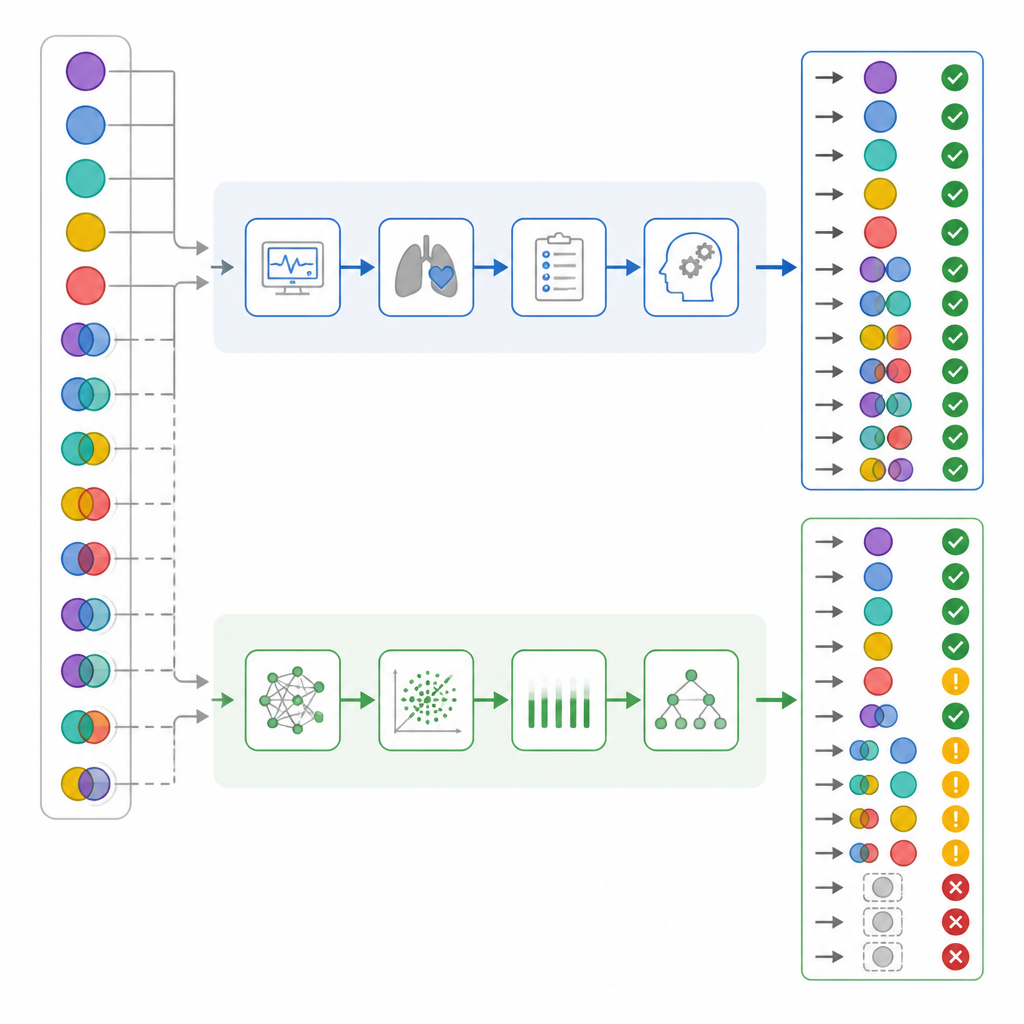
Teamet samlade data från 50 verkliga vuxna IVA‑patienter vid ett enda sjukhus och använde endast det första berättigade blodgasprovet från varje person. För varje patient skapade de en kort klinisk berättelse som inkluderade blodgasvärden och andra viktiga detaljer som vitala parametrar, organfunktion och andningsstöd. Tre grupper tolkade sedan varje fall oberoende av varandra: den första läkaren vid sängen, ChatGPT med en fast engelsk prompt, och en expertpanel som gav slutlig ”gold standard”-diagnos. Alla tolkningar sorterades senare i sex enkla grupper, inklusive normalt status, fyra grundläggande störningstyper och en blandkategori där mer än ett problem var närvarande.
Att se bortom enkelt rätt eller fel
När forskarna endast tittade på total korrekthet såg siffrorna ganska lika ut: IVA‑läkarna hade rätt i 82 procent av fallen, medan ChatGPT var rätt i 72 procent. Vanliga överensstämmelsestatistik indikerade att båda presterade i ett ”substantiellt” intervall. Men teamet grävde djupare i hur varje part felade, inte bara hur ofta. De delade upp enkla och blandade fall, kontrollerade hur väl varje tolk upptäckte respiratoriska kontra metabola komponenter, och skapade en ”skadepoäng” där vissa misstag räknades som farligare än andra. I detta system gavs högst vikt åt att kalla ett verkligt komplext fall ”normalt”, eftersom det kan få personalen att känna sig falskt trygg.
Dolda skillnader i komplexa och riskfyllda fall
När resultaten bröts ner efter komplexitet framträdde viktiga skillnader. Nästan hälften av patienterna hade faktiskt blandade syra‑bas‑problem. IVA‑läkarna identifierade dessa korrekt i nästan alla fall, medan ChatGPT missade mer än en tredjedel av dem. I ungefär en sjättedel av de blandade fallen klassificerade ChatGPT till och med blodstatus som normal — ett mönster författarna kallade ”falsk lugnande”, vilket läkarna aldrig visade. En närmare granskning av separata respiratoriska och metabola komponenter antydde att ChatGPT var mer benäget att förbise den respiratoriska delen av störningen. När skadepoängssystemet tillämpades bar ChatGPT:s fel en signifikant högre genomsnittlig skadevikt än IVA‑läkarnas, trots att deras övergripande noggrannhet överlappade.
Vad detta betyder för AI i kritisk vård
För en lekman är huvudbudskapet att liknande övergripande träffsäkerhet inte innebär att ett AI‑verktyg beter sig som en läkare där det verkligen räknas. I detta verkliga urval från IVA kunde ChatGPT ofta klassificera vanliga mönster väl, men den hade svårare för de sammanflätade, blandade problemen som signalerar allvarlig sjukdom och kräver snabba åtgärder. Eftersom personalen inte alltid kan avgöra i förväg vilka fall som är enkla och vilka som är komplexa, och nuvarande AI‑verktyg inte tillförlitligt varnar när de är osäkra, menar författarna att ChatGPT inte bör ersätta läkarbedömning för dessa blodgasbeslut. Istället föreslår de att framtida tester av medicinsk AI bör fokusera mindre på övergripande resultatlistor och mer på hur ofta systemet missar farliga situationer, hur det hanterar komplexitet och hur skadliga dess misstag kan vara för patienterna.
Citering: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
Nyckelord: intensivvård, tolkning av blodgaser, klinisk artificiell intelligens, diagnostisk säkerhet, ChatGPT i medicin