Clear Sky Science · nl
Asymmetrie in structurele fouten en schadewaardige analyse van ChatGPT versus IC-artsen bij zuur-base-interpretatie: een prospectieve observationele studie
Waarom deze studie ertoe doet voor gewone lezers
Ziekenhuizen experimenteren steeds vaker met kunstmatige intelligentie om artsen te helpen beslissingen te nemen, vooral op drukke intensivecare-afdelingen. Deze studie stelt een eenvoudige maar cruciale vraag: wanneer een computerprogramma zoals ChatGPT helpt bij de interpretatie van een zeer delicate bloedtest die levensreddende behandelingen stuurt, zijn zijn fouten dan even veilig als die van ervaren IC-artsen, of kunnen ze stilletjes ernstige problemen verhullen?
De bloedtest in het hart van het verhaal
Het onderzoek richt zich op arteriële bloedgasanalyse, die meet hoe zuur het bloed is en hoe goed een patiënt ademt en zuurstof krijgt. In de IC helpen deze resultaten artsen beslissen of ze een beademingsmachine moeten bijstellen, vocht moeten toedienen of medicijnen moeten veranderen. De patronen kunnen eenvoudig zijn, bijvoorbeeld één hoofdprobleem met ademhaling of stofwisseling, of complex, met meerdere problemen tegelijk. Deze “gemengde” patronen komen veel voor bij zeer zieke patiënten en kunnen aangeven dat het lichaam op meerdere fronten moeite heeft.
Hoe de rechtstreekse vergelijking werd uitgevoerd
Het team verzamelde gegevens van 50 echte volwassen IC-patiënten in één ziekenhuis, en gebruikte alleen de eerste in aanmerking komende bloedgastest van elke persoon. Voor elke patiënt maakten ze een korte klinische casus met de bloedgaswaarden en andere belangrijke gegevens zoals vitale functies, orgaanfunctie en ademhalingsondersteuning. Drie groepen interpreteerden elk geval onafhankelijk: de artsen aan het bed, ChatGPT met een vaste Engelse prompt, en een apart expertpanel dat de definitieve “gouden standaard”-diagnose gaf. Alle interpretaties werden later ingedeeld in zes eenvoudige categorieën, waaronder normale status, vier basale stoornistypen, en een gemengde categorie waar meer dan één probleem aanwezig was.
Verder kijken dan simpel goed of fout
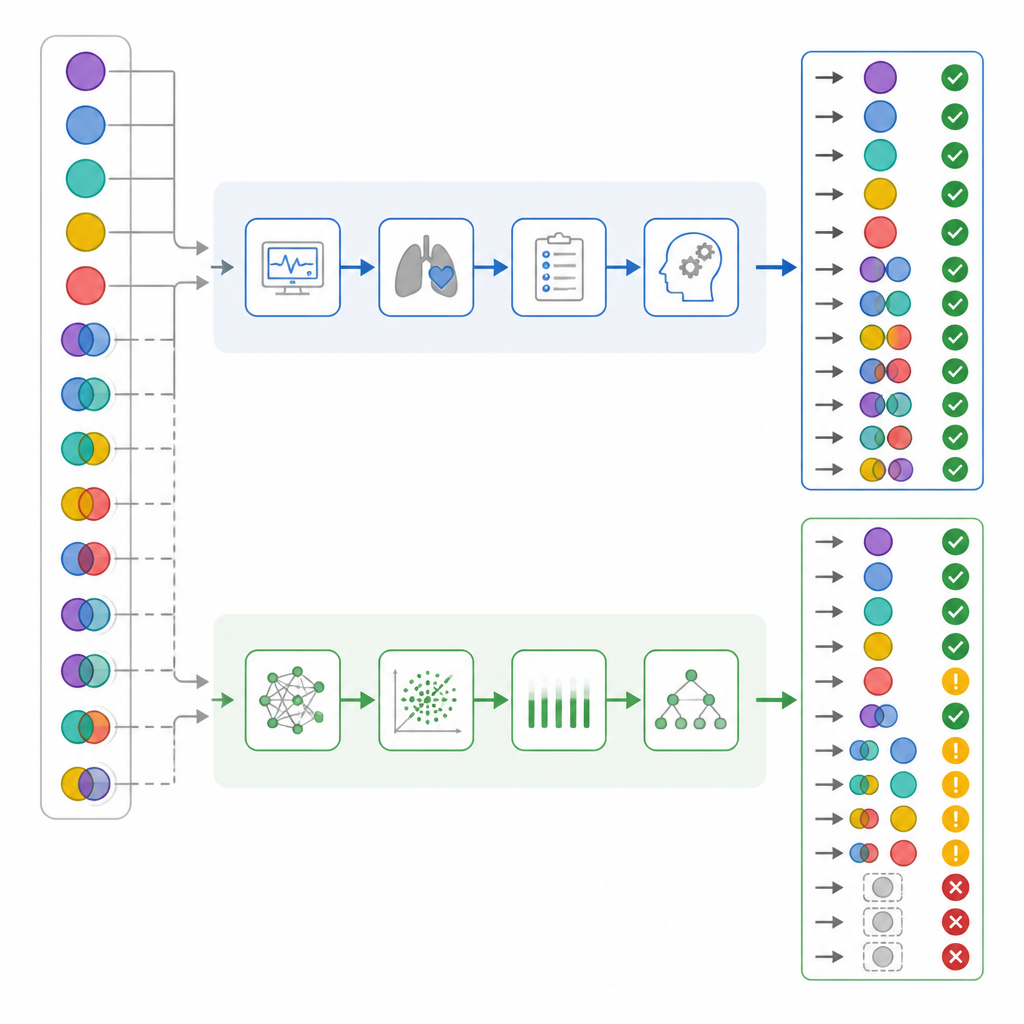
Wanneer de onderzoekers alleen naar de algemene juistheid keken, leken de cijfers redelijk dicht bij elkaar te liggen: IC-artsen hadden in 82 procent van de gevallen gelijk, terwijl ChatGPT in 72 procent van de gevallen correct was. Standaard overeenstemmingsstatistieken suggereerden dat beide in een “substantiële” range presteerden. Maar het team dook dieper in hoe elke partij fout zat, niet alleen hoe vaak. Ze splitsten eenvoudige en gemengde gevallen, controleerden hoe goed elk van hen ademhalings- versus metabole componenten opmerkte, en creëerden een “schadewaarde”-score die sommige fouten als gevaarlijker telde dan andere. In dit systeem droeg het noemen van een werkelijk complex geval als “normaal” het zwaarst, omdat dat het personeel in een vals gevoel van veiligheid kan wiegen.
Verborgen verschillen in complexe en risicovolle gevallen
Zodra de resultaten werden uitgesplitst naar complexiteit, werden belangrijke contrasten zichtbaar. Bij bijna de helft van de patiënten waren er daadwerkelijk gemengde zuur-baseproblemen. IC-artsen herkenden deze in bijna alle gevallen correct, terwijl ChatGPT meer dan een derde ervan miste. In ongeveer één zesde van de gemengde gevallen labelde ChatGPT de bloedstatus zelfs als normaal, een patroon dat de auteurs “valse geruststelling” noemden, iets wat de artsen nooit lieten zien. Een nadere blik op afzonderlijke ademhalings- en metabole componenten suggereerde dat ChatGPT waarschijnlijker het ademhalingsgedeelte van de stoornis over het hoofd zag. Toen het schadewaardesysteem werd toegepast, hadden de fouten van ChatGPT een significant hogere gemiddelde schadewaarde dan die van de IC-artsen, ondanks dat hun algehele nauwkeurigheid overlapt.
Wat dit betekent voor het gebruik van AI in de kritieke zorg
Voor een niet-specialistische lezer is de hoofdboodschap dat vergelijkbare kopnauwkeurigheid niet betekent dat een AI-hulpmiddel zich gedraagt als een arts waar het echt telt. In dit real-world IC-voorbeeld kon ChatGPT vaak veelvoorkomende patronen goed classificeren, maar het had meer moeite met de verwarde, gemengde problemen die ernstige ziekte signaleren en snelle actie vereisen. Omdat personeel niet altijd van tevoren kan weten welke gevallen eenvoudig en welke complex zijn, en huidige AI-tools niet betrouwbaar waarschuwen wanneer ze onzeker zijn, betogen de auteurs dat ChatGPT het oordeel van een arts niet moet vervangen voor deze bloedgasbeslissingen. In plaats daarvan stellen zij dat toekomstige tests van medische AI minder op algemene scorekaarten moeten focussen en meer op hoe vaak het systeem gevaarlijke situaties mist, hoe het met complexiteit omgaat, en hoe schadelijk zijn fouten voor patiënten zouden kunnen zijn.
Bronvermelding: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
Trefwoorden: intensive care, interpretatie van bloedgassen, klinische kunstmatige intelligentie, diagnostische veiligheid, ChatGPT in de geneeskunde