Clear Sky Science · he
אי-סימטריה בשגיאות מבניות וניתוח משוקלל נזק של ChatGPT לעומת רופאי טיפול נמרץ בפרשנות חומצה–בסיס: מחקר תצפיתי פרוספקטיבי
למה המחקר הזה חשוב לקוראים היומיומיים
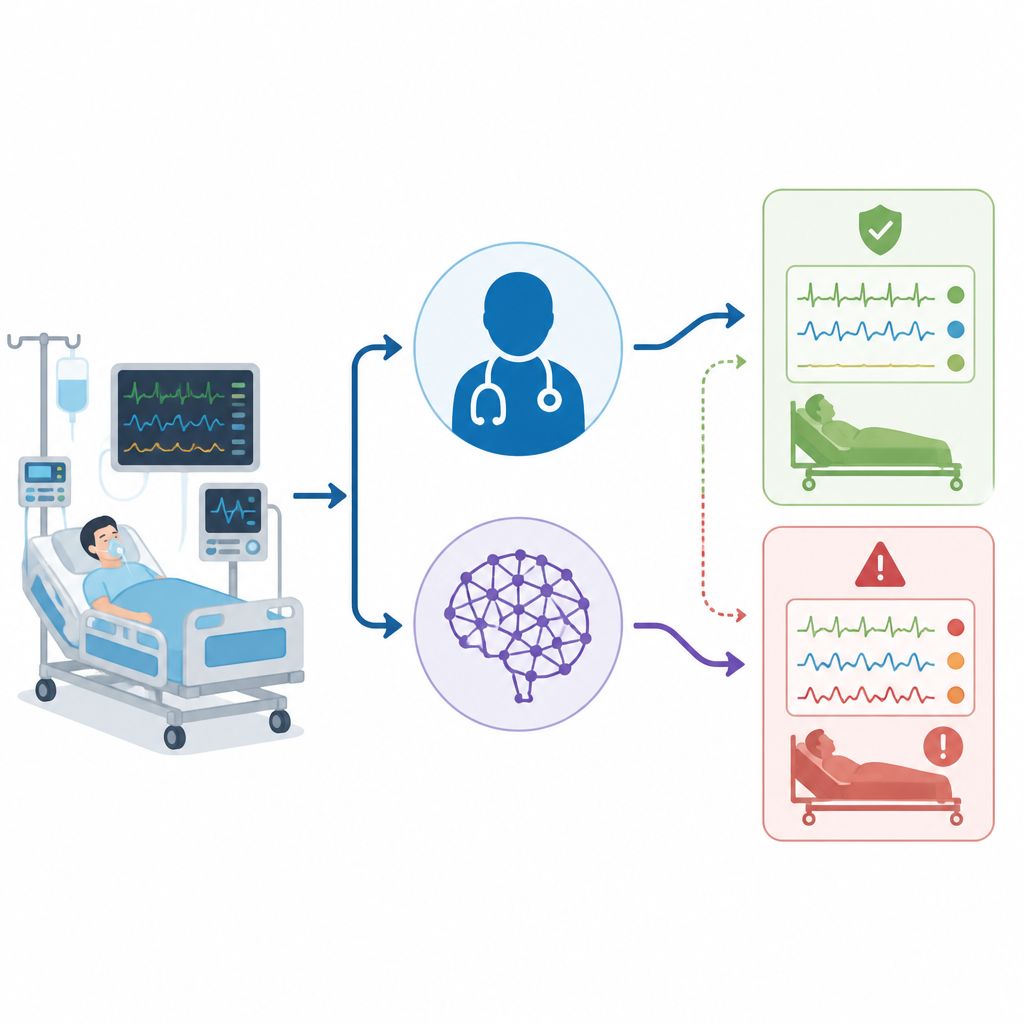
בתי חולים מנסים יותר ויותר בינה מלאכותית כדי לסייע לרופאים בקבלת החלטות, במיוחד ביחידות טיפול נמרץ צפופות. המחקר שואל שאלה פשוטה אך חיונית: כאשר תוכנה כמו ChatGPT מסייעת לפרש בדיקת דם עדינה שמנחה טיפול מציל חיים, האם שגיאותיה בטוחות כמו אלו של רופאי טיפול נמרץ מנוסים, או שמא הן עלולות להסתיר בעדינות סכנה משמעותית?
בדיקת הדם שבמרכז הסיפור
המחקר מתמקד בבדיקות גז עורקי בדם, המודדות עד כמה הדם חומצי וכמה המטופל נושם ומקבל חמצן. ב-ICU התוצאות האלה מסייעות לרופאים להחליט האם לכוונן מכונת הנשמה, לתת נוזלים או לשנות תרופות. התבניות יכולות להיות פשוטות, כמו בעיה עיקרית אחת בנשימה או במטבוליזם, או מורכבות, עם מספר בעיות המתרחשות בו-זמנית. דפוסי "מעורבבים" אלה שכיחים בחולים קשים מאוד ועלולים להעיד שהגוף נאבק בכמה מישורים במקביל.
איך בוצעה ההשוואה של ראש מול ראש
הצוות אסף נתונים מ-50 מטופלים מבוגרים אמיתיים ב-ICU בבית חולים אחד, כשהשתמשו רק בבדיקת גז הדם הראשונה שעומדת בקריטריונים מכל מטופל. לכל מטופל יצרו סיפור קליני קצר שכלל את ערכי גזי הדם ופרטים מרכזיים נוספים כמו מדדי חיים, תפקוד איברים ותמיכה בנשימה. אחר כך שלוש קבוצות פירשו כל מקרה באופן בלתי תלוי: רופאי ה-ICU במיטה, ChatGPT בעזרת פרומפט קבוע באנגלית, ופאנל מומחים נפרד שסיפק את אבחנת ה"סטנדרט זהב". כל הפרשנויות מוינו לאחר מכן לשש קבוצות פשוטות, כולל מצב תקין, ארבעה סוגי הפרעות בסיסיות וקטגוריית מעורבבת שבה נוכחות יותר מבעיה אחת.
מסתכלים מעבר נכונה או לא נכונה פשוטה
כאשר החוקרים הסתכלו רק על נכונות כוללת, המספרים נראו די קרובים: רופאי ה-ICU היו נכונים ב-82 אחוז מהמקרים, בעוד ChatGPT היה נכון ב-72 אחוז. סטטיסטיקות הסכמה סטנדרטיות הצביעו על כך ששני הצדדים פעלו בטווח "משמעותי". אך הצוות חקר לעומק כיצד כל צד טעה, ולא רק כמה פעמים. הם הפרידו מקרים פשוטים ממעורבבים, בדקו עד כמה כל מפרש זיהה את מרכיבי הנשימה לעומת המטבוליזם, ויצרו "ציון נזק" שסווג חלק מהשגיאות כמסוכנות יותר מאחרות. במערכת זו, תיאור מקרה מורכב באמת כ"תקין" נשא את המשקל הגבוה ביותר, כי זה עלול להכניס צוות לבטחון שווא.
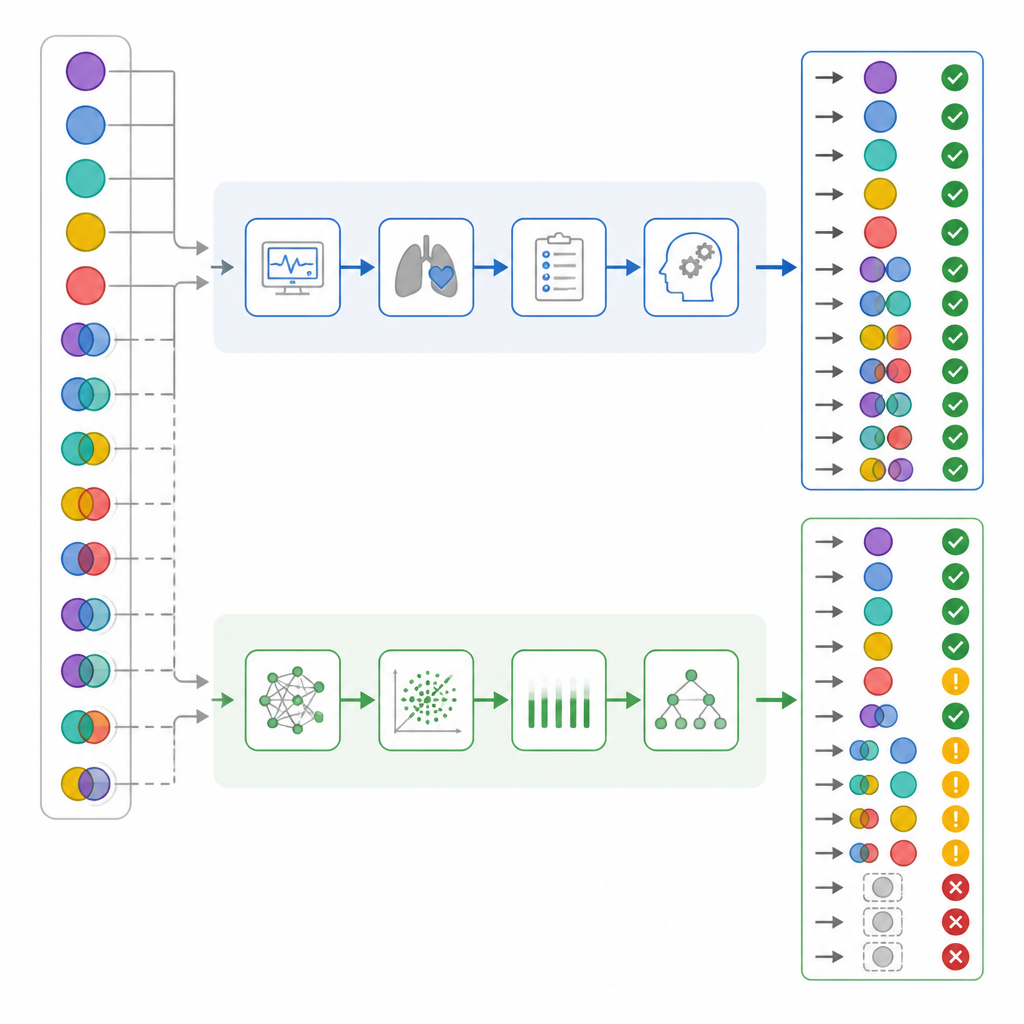
הבדלים חבויים במקרים מורכבים ומסוכנים
כאשר התוצאות פורקו לפי מורכבות, הופיעו הבדלים חשובים. כמעט מחצית מהמטופלים אכן סבלו מבעיות חומצה–בסיס מעורבות. רופאי ה-ICU זיהו זאת נכון בכמעט כל המקרים, בעוד ChatGPT החמיץ יותר משליש מהם. בכעשירית עד שישית מהמקרים המעורבבים, ChatGPT אף תיאר את מצב הדם כתקין — דפוס שהמחברים כינו "התחממות שווא" (false reassurance), שלא הופיע אצל הרופאים. מבט מעמיק בנפרד על מרכיבי הנשימה והמטבוליזם הציע ש-ChatGPT נוטה יותר להתעלם מהרכיב הנשימתי של ההפרעה. כשיושם מערכת ציון הנזק, לשגיאות של ChatGPT היה משקל נזק ממוצע גבוה בהרבה מזה של רופאי ה-ICU, למרות שהדיוק הכולל שלהם חופף במידה מסוימת.
מה המשמעות של זה לשימוש בבינה מלאכותית בטיפול קריטי
לקורא שאינו מומחה, המסר המרכזי הוא שדיוק דומה בכותרות אינו אומר שכלי בינה מלאכותית מתנהג כמו רופא כשזה חשוב באמת. במדגם זה מעולם ה-ICU, ChatGPT לעתים סיווג תבניות נפוצות היטב, אך נאבק יותר עם הבעיות המעורבות המורכבות שמצביעות על מחלה קשה ודורשות פעולה מהירה. מכיוון שהצוות לא תמיד יכול לדעת מראש אילו מקרים פשוטים ואילו מורכבים, וכלי ה-AI הנוכחיים אינם מזהירים בצורה אמינה כאשר הם לא בטוחים, המחברים טוענים ש-ChatGPT לא אמור להחליף את שיקול הדעת הרפואי בהחלטות אלו של גזי דם. במקום זאת הם מציעים שמבחנים עתידיים של AI רפואי יתמקדו פחות בטבלאות דירוג כוללות ויותר בתדירות שבה המערכת מחמיצה מצבים מסוכנים, כיצד היא מתמודדת עם מורכבות, ומה חומרת השגיאות שלה לגבי המטופלים.
ציטוט: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
מילות מפתח: טיפול נמרץ, פרשנות גזי דם, בינה מלאכותית קלינית, בטיחות אבחנתית, ChatGPT ברפואה