Clear Sky Science · ja
構造的誤りの非対称性と危害重み付け解析:ChatGPT 対 ICU 医師の酸塩基解釈に関する前向き観察研究
この研究が一般読者にとって重要な理由
病院では混雑した集中治療室で医師の意思決定を支援するために人工知能を試す動きが進んでいます。本研究は単純だが重要な問いを投げかけます:ChatGPT のようなコンピュータープログラムが命を救う治療の指標となる非常に繊細な血液検査の解釈を手伝う場合、その誤りは経験ある ICU 医師のものと同様に安全なのか、それとも重大な問題を静かに見逃す可能性があるのか?
物語の中心にある血液検査
研究は動脈血ガス検査に焦点を当てます。これは血液の酸性度や患者の呼吸・酸素化の状態を測る検査です。ICU ではこれらの結果が、人工呼吸器の調整、輸液の判断、あるいは薬剤の変更といった処置を決める手がかりになります。パターンは単純で、呼吸か代謝のどちらか一方に主問題がある場合もあれば、複数の問題が同時に起きる複雑な“混合”パターンもあります。こうした混合パターンは重症患者に多く見られ、身体が複数の面で同時に苦戦していることを示すことがあります。
どのように対決比較が行われたか
研究チームは単一病院の成人 ICU 患者 50 名からデータを収集し、各人について最初に該当した血液ガス検査だけを使用しました。各患者について、血液ガスの数値やバイタルサイン、臓器機能、呼吸補助の有無などの重要情報を含む短い臨床文を作成しました。その後、3 つのグループがそれぞれ独立に各ケースを解釈しました:患者のそばにいる ICU 医師、固定の英語プロンプトを用いた ChatGPT、そして最終的な“ゴールドスタンダード”診断を示す別の専門家パネルです。すべての解釈は後で 6 つの単純なグループに分類されました(正常、4 種類の基本的攪乱、そして複数の問題がある混合カテゴリー)。
単なる正誤を超えて見る
研究者が全体の正確さだけを見たとき、数字はかなり近かった:ICU 医師の正解率は 82%、ChatGPT は 72%でした。通常の一致指標は両者が「実質的」な範囲であることを示しました。しかしチームは頻度だけでなく、各々がどのように間違ったかをさらに詳しく調べました。単純ケースと混合ケースを分けて、呼吸性要素と代謝性要素をそれぞれどれだけ見抜けたかを確認し、いくつかの誤りをより危険と見なす「危害スコア」を作成しました。この体系では、実際には複雑なケースを「正常」と判断することが最も重い重みを持ちます。なぜならそれはスタッフを誤った安心に導きかねないからです。
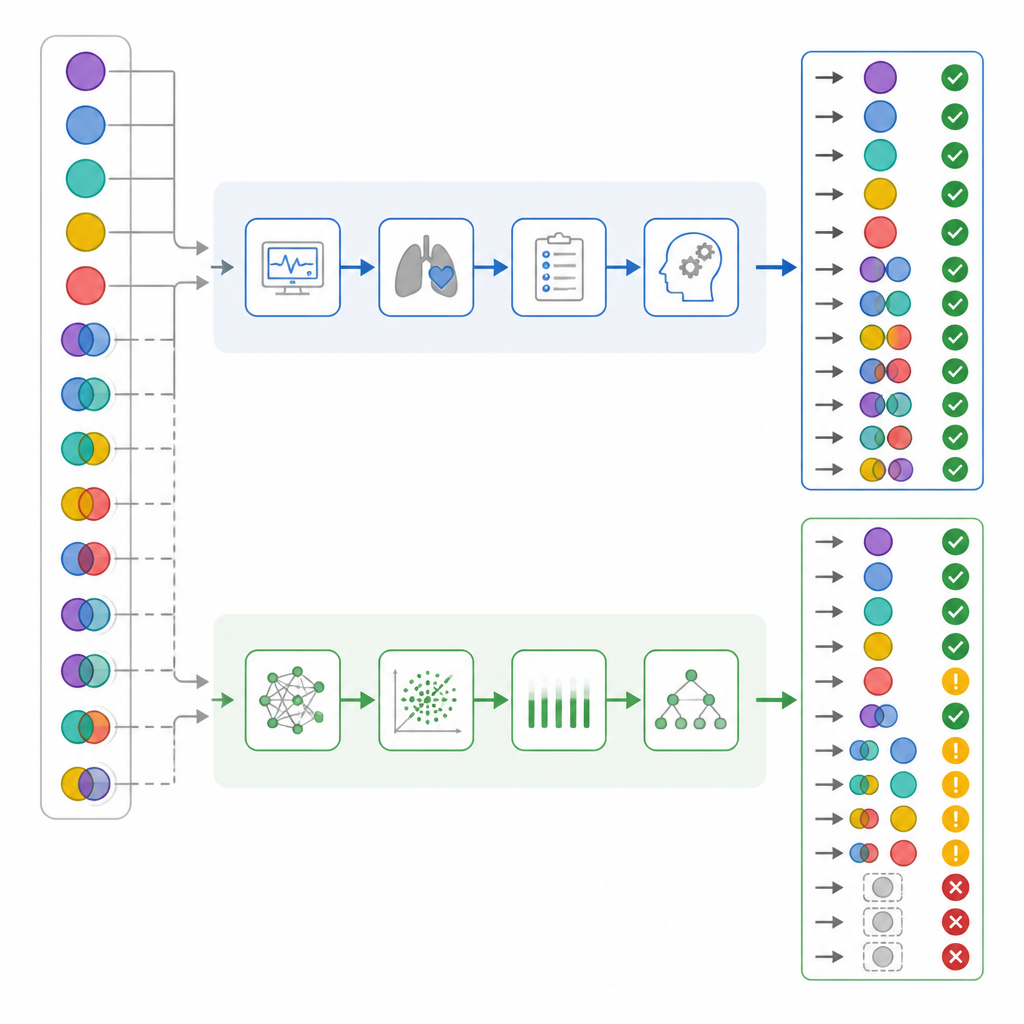
複雑で危険なケースに潜む違い
結果を複雑さごとに分けると重要な対照が明らかになりました。患者のほぼ半数が実際に混合性の酸塩基異常を持っていました。ICU 医師はこれらをほとんどの症例で正しく認識した一方、ChatGPT はそのうち 3 分の 1 以上を見逃しました。混合ケースの約 6 分の 1 では、ChatGPT は血液状態を正常と誤って示し、著者らはこれを「誤った安心(false reassurance)」と呼びましたが、医師はこのような誤りを示しませんでした。呼吸性と代謝性の要素を別々に詳しく見ると、ChatGPT は攪乱の呼吸側を見落としがちであることが示唆されました。危害スコアを適用すると、ChatGPT の誤りは ICU 医師の誤りより平均的に有意に高い危害を伴っていました。これは全体の正確さが重なるにもかかわらず成り立つ結果です。
重症ケアで AI を使うことが意味すること
一般読者への主なメッセージは、見出しを飾る類の類似した精度があっても、重要な場面で AI ツールが医師と同じ振る舞いをするとは限らないということです。この実世界の ICU サンプルでは、ChatGPT はよくあるパターンを分類することは多くの場合うまくできましたが、重篤さを示し迅速な対応を要するもつれた混合問題ではより苦戦しました。スタッフが事前にどの症例が単純でどれが複雑かを常に見分けられるわけではなく、現行の AI ツールは自信が低いときに確実に警告するわけでもないため、著者らは血液ガスの判断において ChatGPT を医師の判断に代替させるべきではないと主張します。代わりに今後の医療用 AI の検証は、総合成績表よりも、システムがどれほど危険な状況を見逃すか、複雑さをどう扱うか、そして誤りが患者にとってどれほど有害になり得るかに重点を置くべきだと提案しています。
引用: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
キーワード: 集中治療, 血液ガス解釈, 臨床用人工知能, 診断の安全性, 医学分野における ChatGPT