Clear Sky Science · es
Asimetría de errores estructurales y análisis ponderado por daño de ChatGPT frente a médicos de UCI en la interpretación ácido–base: un estudio observacional prospectivo
Por qué este estudio importa a lectores no especializados
Los hospitales experimentan cada vez más con la inteligencia artificial para ayudar a los médicos a tomar decisiones, sobre todo en unidades de cuidados intensivos saturadas. Este estudio plantea una pregunta simple pero vital: cuando un programa informático como ChatGPT ayuda a interpretar una prueba sanguínea muy delicada que guía tratamientos que salvan vidas, ¿son sus errores tan seguros como los de médicos experimentados de UCI, o podrían ocultar silenciosamente problemas graves?
La prueba sanguínea en el centro de la historia
La investigación se centra en las gasometrías arteriales, que miden cuán ácido está la sangre y qué tan bien respira y oxigena el paciente. En la UCI, estos resultados ayudan a los médicos a decidir si ajustar un ventilador, administrar fluidos o cambiar medicamentos. Los patrones pueden ser simples, por ejemplo un problema principal respiratorio o metabólico, o complejos, con varios trastornos simultáneos. Estos patrones “mixtos” son comunes en pacientes muy graves y pueden señalar que el organismo está fallando en varios frentes a la vez.
Cómo se hizo la comparación directa
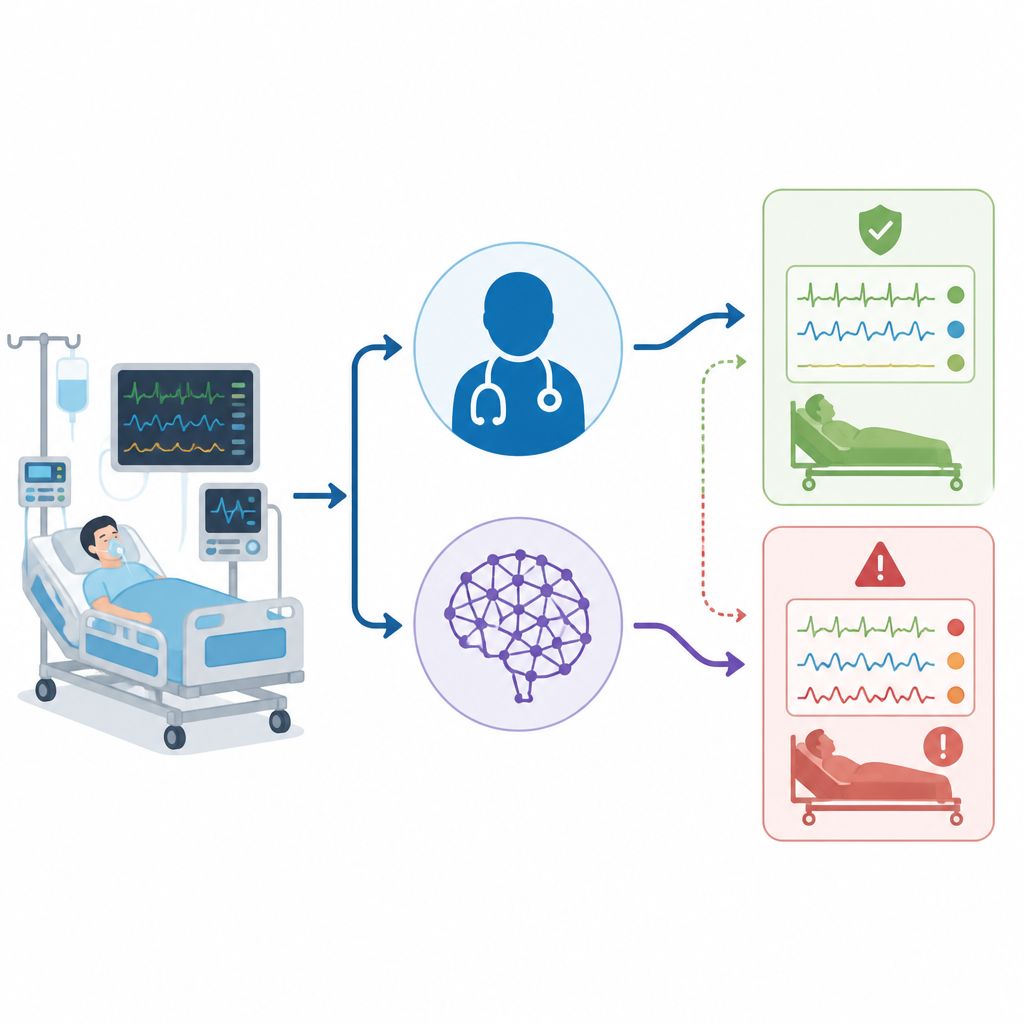
El equipo recogió datos de 50 pacientes adultos reales de una sola UCI de un hospital, usando únicamente la primera gasometría que cumplía los criterios de cada persona. Para cada paciente crearon una breve historia clínica que incluía los valores de la gasometría y otros datos clave como signos vitales, función orgánica y soporte ventilatorio. Tres grupos interpretaron cada caso de forma independiente: los médicos de UCI en la cama del paciente, ChatGPT usando un aviso fijo en inglés, y un panel experto separado que proporcionó el diagnóstico “estándar de oro”. Todas las interpretaciones se clasificaron después en seis grupos sencillos, incluyendo estado normal, cuatro tipos básicos de trastorno y una categoría mixta donde había más de un problema presente.
Mirando más allá del simple acierto o error
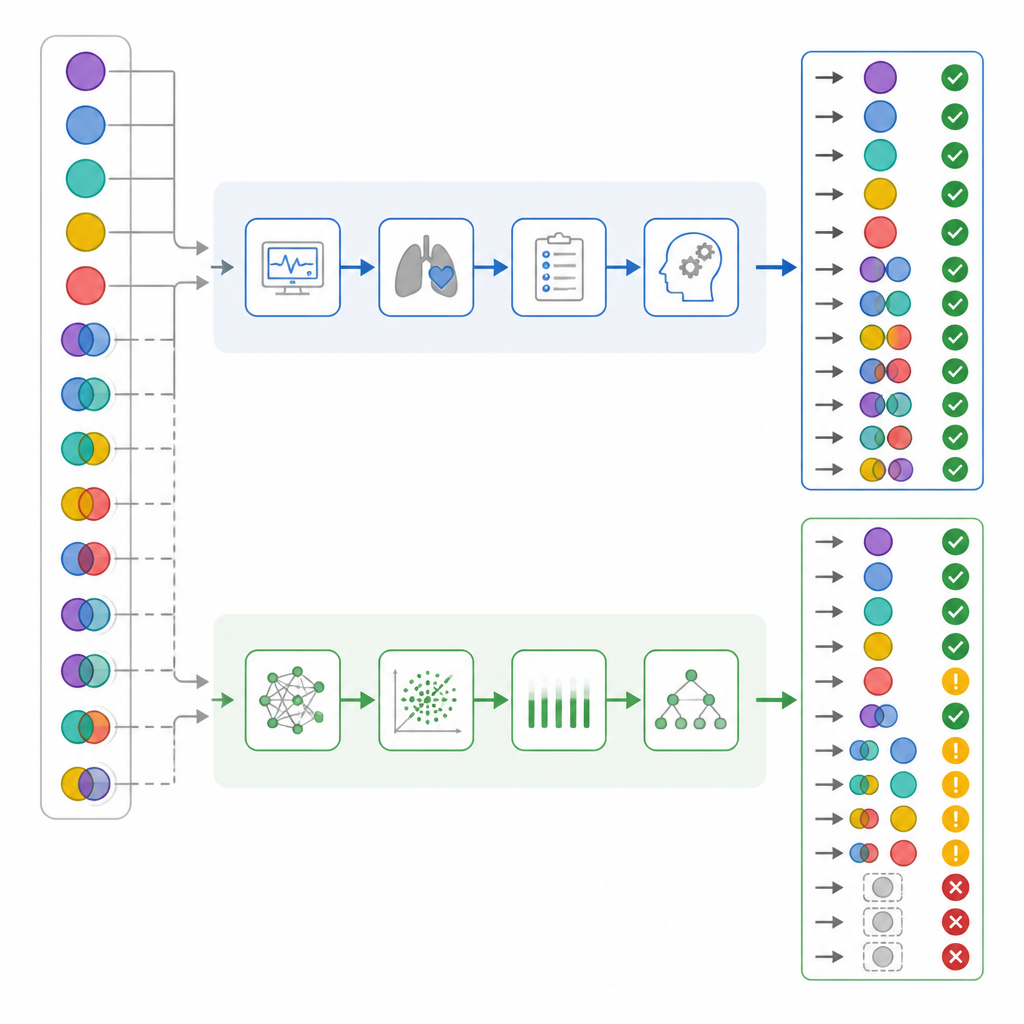
Cuando los investigadores consideraron solo la corrección global, las cifras parecieron bastante cercanas: los médicos de UCI acertaron en el 82 por ciento de los casos, mientras que ChatGPT acertó en el 72 por ciento. Las estadísticas de concordancia estándar sugirieron que ambos rendían en un rango “sustancial”. Pero el equipo profundizó en cómo fallaba cada parte, no solo en la frecuencia. Separaron casos simples de mixtos, verificaron qué tan bien cada intérprete detectaba componentes respiratorios frente a metabólicos, y crearon una “puntuación de daño” que consideraba algunos errores más peligrosos que otros. En este sistema, etiquetar como “normal” un caso realmente complejo llevaba el mayor peso, porque podría inducir a la plantilla a una falsa sensación de seguridad.
Diferencias ocultas en casos complejos y riesgosos
Una vez desglosados los resultados por complejidad, aparecieron contrastes importantes. Casi la mitad de los pacientes tenía en realidad problemas ácido–base mixtos. Los médicos de UCI reconocieron correctamente estos casos en casi todos, mientras que ChatGPT pasó por alto más de un tercio de ellos. En aproximadamente una sexta parte de los casos mixtos, ChatGPT incluso etiquetó el estado sanguíneo como normal, un patrón que los autores llamaron “falsa tranquilidad”, que los médicos nunca mostraron. Un análisis más detenido de los componentes respiratorios y metabólicos por separado sugirió que ChatGPT tendía a pasar por alto la parte respiratoria del trastorno. Cuando se aplicó la puntuación de daño, los errores de ChatGPT tuvieron un daño medio significativamente mayor que los de los médicos de UCI, aun cuando su precisión global se solapaba.
Qué significa esto para el uso de IA en cuidados críticos
Para un lector general, el mensaje principal es que una precisión similar a nivel general no implica que una herramienta de IA se comporte como un médico en lo que importa. En esta muestra real de UCI, ChatGPT pudo clasificar bien patrones comunes en muchas ocasiones, pero tuvo más dificultades con los problemas enmarañados y mixtos que señalan enfermedad grave y requieren acción rápida. Dado que el personal no siempre puede saber de antemano qué casos son simples y cuáles complejos, y las herramientas de IA actuales no advierten de forma fiable cuando están inseguras, los autores sostienen que ChatGPT no debería reemplazar el juicio del médico en estas decisiones sobre gasometría. En su lugar, sugieren que las pruebas futuras de IA médica deberían centrarse menos en resultados globales y más en con qué frecuencia el sistema pasa por alto situaciones peligrosas, cómo maneja la complejidad y cuán dañinos podrían ser sus errores para los pacientes.
Cita: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
Palabras clave: cuidados intensivos, interpretación de gases en sangre, inteligencia artificial clínica, seguridad diagnóstica, ChatGPT en medicina