Clear Sky Science · de
Asymmetrie struktureller Fehler und schadensgewichtete Analyse von ChatGPT gegenüber Intensivmedizinern in der Interpretation von Säure-Basen-Störungen: eine prospektive Beobachtungsstudie
Warum diese Studie für Leserinnen und Leser wichtig ist
Krankenhäuser experimentieren zunehmend mit künstlicher Intelligenz, um Ärztinnen und Ärzte bei Entscheidungen zu unterstützen, besonders auf überfüllten Intensivstationen. Diese Studie stellt eine einfache, aber entscheidende Frage: Wenn ein Computerprogramm wie ChatGPT hilft, einen sehr empfindlichen Bluttest zu interpretieren, der lebensrettende Maßnahmen steuert — sind seine Fehler genauso unproblematisch wie die von erfahrenen Intensivmedizinern, oder können sie schwerwiegende Probleme unbemerkt lassen?
Der Bluttest im Mittelpunkt
Die Untersuchung konzentriert sich auf arterielle Blutgasanalysen, die messen, wie sauer das Blut ist und wie gut ein Patient atmet und Sauerstoff aufnimmt. Auf der Intensivstation helfen diese Werte den Ärztinnen und Ärzten zu entscheiden, ob ein Beatmungsgerät angepasst, Flüssigkeit verabreicht oder Medikamente verändert werden sollten. Die Muster können einfach sein, etwa ein dominierendes respiratorisches oder metabolisches Problem, oder komplex, mit mehreren gleichzeitig auftretenden Störungen. Solche „gemischten“ Muster sind bei sehr kranken Patientinnen und Patienten häufig und können darauf hinweisen, dass der Körper auf mehreren Ebenen gleichzeitig kämpft.
Wie der direkte Vergleich durchgeführt wurde
Das Team sammelte Daten von 50 realen erwachsenen Intensivpatientinnen und -patienten in einem einzelnen Krankenhaus und nutzte jeweils nur die erste passende Blutgasanalyse pro Person. Für jeden Fall erstellten sie eine kurze klinische Fallbeschreibung mit den Blutgaswerten und weiteren wichtigen Details wie Vitalzeichen, Organfunktion und Beatmungsunterstützung. Drei Gruppen interpretierten dann jeden Fall unabhängig voneinander: die behandelnden Intensivärzte am Krankenbett, ChatGPT mit einem festen englischen Prompt und ein separates Expertengremium, das die endgültige „Goldstandard“-Diagnose stellte. Alle Interpretationen wurden anschließend in sechs einfache Kategorien eingeteilt, darunter Normalbefund, vier grundlegende Störungsarten und eine gemischte Kategorie, in der mehr als ein Problem vorlag.
Weiter blicken als nur richtig oder falsch
Wenn die Forschenden nur die Gesamtgenauigkeit betrachteten, wirkten die Zahlen relativ nah beieinander: Intensivärzte lagen in 82 Prozent der Fälle richtig, ChatGPT in 72 Prozent. Übliche Übereinstimmungsstatistiken deuteten darauf hin, dass beide im Bereich „substanziell“ arbeiteten. Das Team untersuchte jedoch tiefer, auf welche Weise die Fehler auftraten, nicht nur wie häufig. Sie trennten einfache von gemischten Fällen, prüften, wie gut jede Instanz respiratorische gegenüber metabolischen Komponenten erkannte, und entwickelten einen „Schadensscore“, der einige Fehler als gefährlicher bewertete als andere. In diesem System trug die Klassifikation eines tatsächlich komplexen Falls als „normal“ das höchste Gewicht, weil sie das Personal in falscher Sicherheit wiegen könnte.
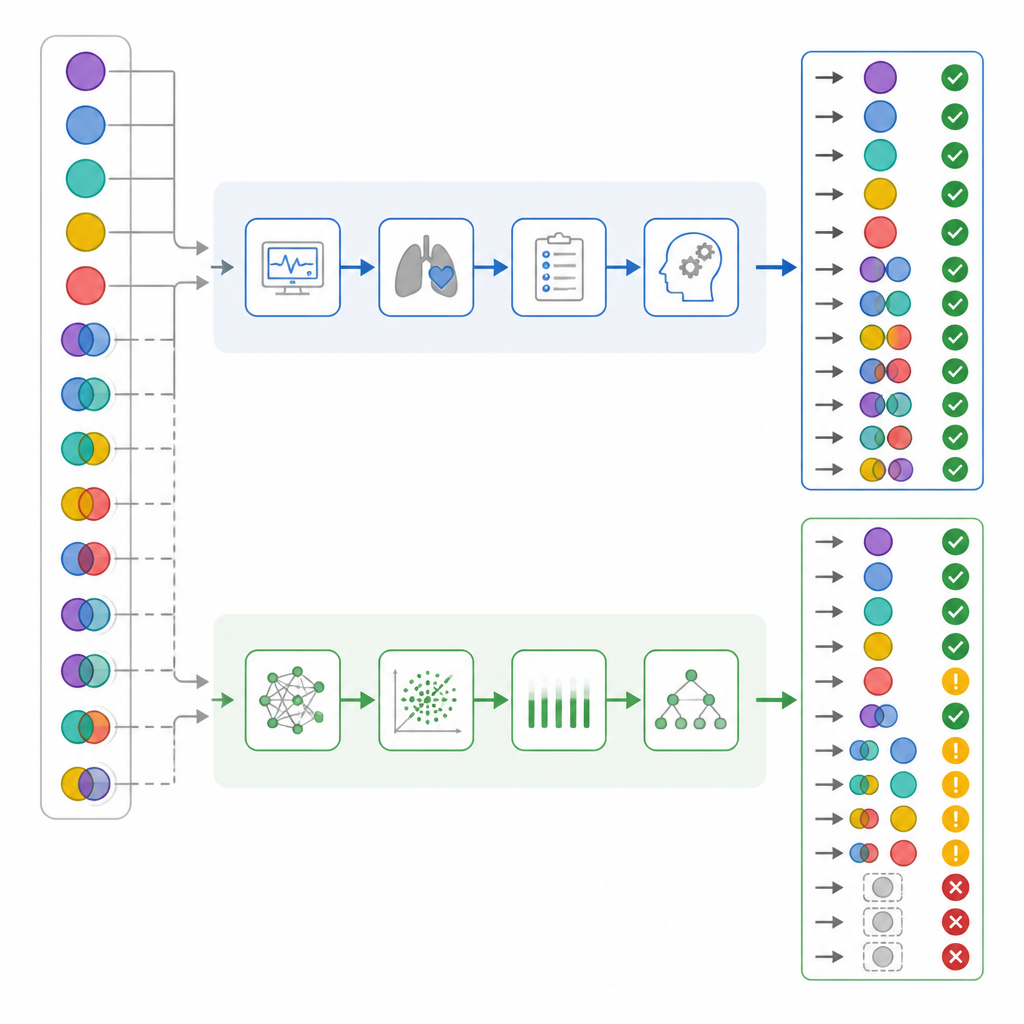
Verborgene Unterschiede bei komplexen und riskanten Fällen
Als die Ergebnisse nach Komplexität aufgeschlüsselt wurden, traten wichtige Unterschiede zutage. Fast die Hälfte der Patientinnen und Patienten hatte tatsächlich gemischte Säure-Basen-Störungen. Intensivärzte erkannten diese in nahezu allen Fällen korrekt, während ChatGPT mehr als ein Drittel davon übersah. In etwa einem Sechstel der gemischten Fälle bewertete ChatGPT den Blutstatus sogar als normal — ein Muster, das die Autorinnen und Autoren als „falsche Beruhigung“ bezeichneten, die die Ärztinnen und Ärzte nie zeigten. Ein genauerer Blick auf die getrennten respiratorischen und metabolischen Komponenten deutete darauf hin, dass ChatGPT eher dazu neigte, den respiratorischen Anteil der Störung zu übersehen. Wurde das Schadensbewertungssystem angewendet, gingen die Fehler von ChatGPT mit einem deutlich höheren durchschnittlichen Schadensscore einher als die der Intensivärzte, trotz sich überschneidender Gesamtgenauigkeit.
Was das für den Einsatz von KI in der Intensivmedizin bedeutet
Für Laien lautet die Kernbotschaft: Ähnliche Schlagzeilen-Genauigkeit bedeutet nicht, dass ein KI-Tool dort wie ein Arzt reagiert, wo es am wichtigsten ist. In dieser realen Intensivprobe konnte ChatGPT häufig gängige Muster korrekt einordnen, hatte jedoch größere Schwierigkeiten mit den verstrickten, gemischten Problemen, die auf schwere Erkrankung hinweisen und schnelles Handeln erfordern. Da das Personal nicht immer im Voraus erkennen kann, welche Fälle einfach und welche komplex sind, und aktuelle KI-Werkzeuge nicht zuverlässig zeigen, wenn sie unsicher sind, plädieren die Autorinnen und Autoren dafür, ChatGPT nicht als Ersatz ärztlicher Beurteilung für diese Blutgasanalysen zu verwenden. Stattdessen schlagen sie vor, dass künftige Tests medizinischer KI weniger auf Gesamtpunktzahlen achten und mehr darauf, wie oft das System gefährliche Situationen übersieht, wie es mit Komplexität umgeht und wie schädlich seine Fehler für Patientinnen und Patienten sein könnten.
Zitation: Gulen, D., Gözden, H.E., Ekin, S. et al. Structural error asymmetry and harm-weighted analysis of ChatGPT versus ICU Physicians in acid–base interpretation: a prospective observational study. Sci Rep 16, 15184 (2026). https://doi.org/10.1038/s41598-026-44576-4
Schlüsselwörter: Intensivmedizin, Blutgasinterpretation, klinische künstliche Intelligenz, Diagnosesicherheit, ChatGPT in der Medizin