Clear Sky Science · zh
用于SARS-CoV-2病毒蛋白命名实体识别的自适应模块化BERT-SPAN模型的优化与比较研究
为什么在论文中找到蛋白质名称很重要
每周都有成千上万篇关于COVID-19及其病毒SARS-CoV-2的新科研论文在网上发表。这些冗长文章中隐藏着关于病毒蛋白的重要线索——这些分子机器帮助病毒感染我们的细胞,也是药物和疫苗的主要靶点。但没有人能阅读所有文献。本研究聚焦于一个简单却强大的问题:我们能否教会计算机自动从文本中快速且准确地识别并列出病毒的蛋白质,以帮助研究者跟上信息速度?
将杂乱文本转为可用数据
当科学家描述SARS-CoV-2时,会使用全称、缩写和俗称的混合形式来指代蛋白质。同一蛋白可能被写成“spike protein”、“S”,或嵌在诸如“receptor-binding domain of spike”的短语中。要在大规模语料上理解这种语言,计算机首先需要一个语料库——由专家标注、在句子中标出每个蛋白质提及的精心整理的集合。作者通过筛选PubMed上约20万篇冠状病毒摘要,找出相关句子并对其中的SARS-CoV-2蛋白提及进行人工标注,构建了这样的资源。经过清洗和交叉校验,他们得到7,159个句子和12,660个标注的蛋白提及,作为训练和测试算法的真实标注数据。
教机器识别病毒蛋白名称
本研究的核心任务是命名实体识别:让计算机从自由形式文本中挑出特定项——在这里是病毒蛋白。早期方法依赖人工制定的规则或已知术语表,但在名称不规则或不断演变时容易失效。更新的系统使用深度学习,模型直接从示例中学习模式。团队基于BERT构建——一种同时从前后文读取并基于上下文学习丰富词表示的语言模型。在BERT之上,他们采用“SPAN”方法:模型不再逐词判断每个标记是否属于实体,而是直接预测每个蛋白提及的起始和结束位置。这更便于处理嵌套或多词名称等复杂情况。
为模型添加智能构件
为了进一步提升系统,作者引入了自适应模块化前馈层,可以把它看作位于BERT与最终跨度检测器之间的若干小型专家模块。不同模块专注于不同类型的模式——例如,连字符、字母与数字混合的表面特征,或指出短字母如“S”实际上是蛋白名的细微上下文线索。自适应加权机制则为每个句子决定应更信任哪些模块,将它们的输出组合成在跨度预测步骤之前的更强信号。这种设计使模型能够灵活地聚焦于每段文本中最有信息量的线索。
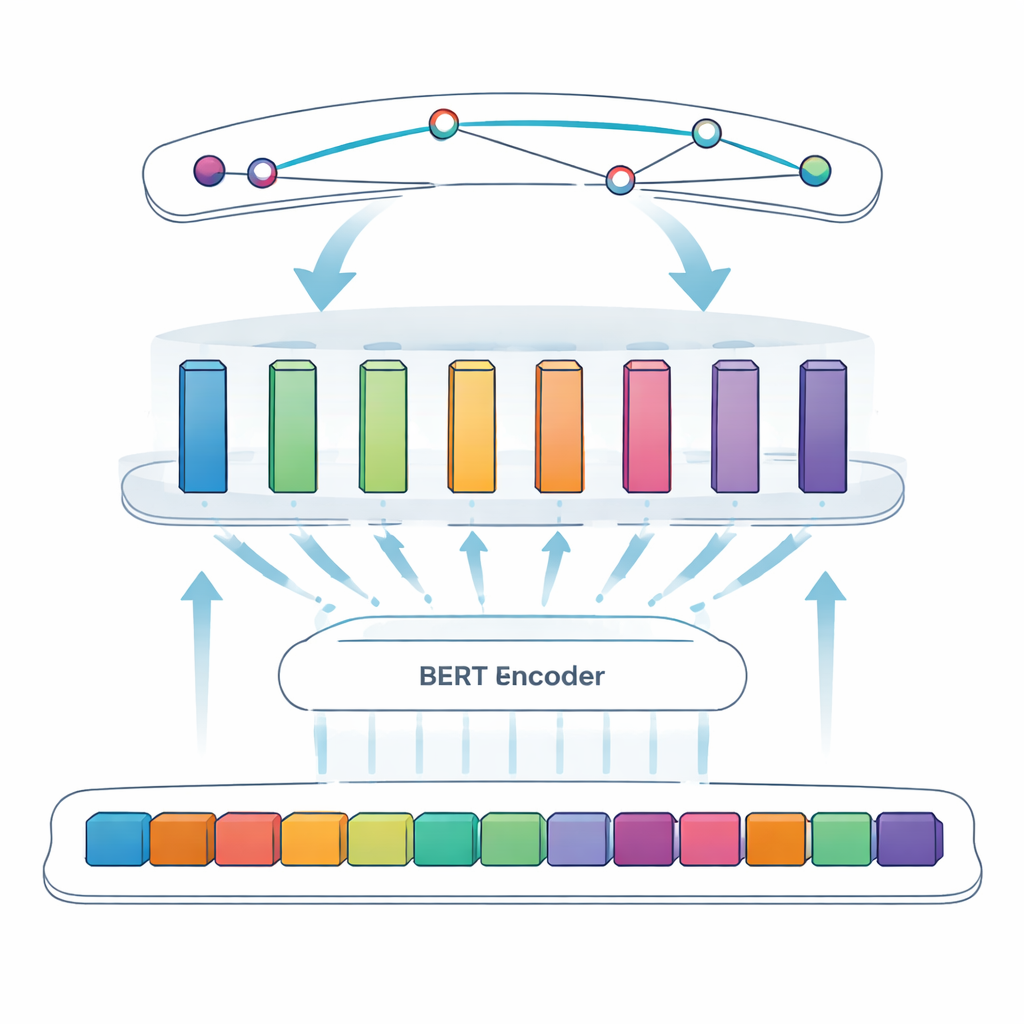
将该方法付诸测试
研究人员将他们的自适应模块化BERT–SPAN模型与若干已有系统进行了严格比较,包括流行的BiLSTM–CRF模型和未加模块化增强的标准BERT–SPAN版本。使用标准的准确性衡量指标,他们发现传统的BiLSTM–CRF模型在其SARS-CoV-2蛋白数据集上取得了约80.8%的F1分数(精确率与召回率的平衡)。仅使用BERT–SPAN即可将性能提升到91.85%。加入自适应模块化层后,F1分数进一步上升到93.66%,在如此成熟的领域中这是一个有意义的提升。通过“消融”实验——逐一移除架构的部分组件——表明模块化和自适应加权均对性能改进有贡献,尤其是在减少边界错误和区分相似缩写方面。
这对未来研究的帮助
对非专业读者来说,关键结论是作者既构建了高质量数据集,又开发了更智能的阅读引擎,能够可靠地在科学文本中识别SARS-CoV-2蛋白。通过将混乱的语言转为结构化的实体列表,他们的系统使得构建知识图谱、映射病毒蛋白与宿主分子之间的相互作用以及跟踪特定靶点证据的积累变得容易得多。实际上,这意味着计算机可以承担更多繁琐的文本挖掘工作,解放人类专家去专注于解释结果和设计实验。研究表明,将强大的语言模型与模块化、自适应组件结合,是应对生物医学文献洪流的一个有前途的方案——不仅适用于冠状病毒研究,也适用于科学发展速度超过我们阅读能力的许多未来挑战。
引用: Shi, X., Fei, Z., Nkhata, A. et al. Optimization and comparison research on adaptive modularization BERT-SPAN model for named entity recognition of SARS-CoV-2 virus proteins. Sci Rep 16, 14207 (2026). https://doi.org/10.1038/s41598-026-44317-7
关键词: SARS-CoV-2 蛋白质, 命名实体识别, 生物医学文本挖掘, BERT 语言模型, 知识图谱