Clear Sky Science · ru
Оптимизация и сравнительное исследование адаптивной модульной модели BERT‑SPAN для распознавания именованных сущностей белков вируса SARS‑CoV‑2
Почему важно находить названия белков в статьях
Каждую неделю в сети появляется тысячи новых научных публикаций о COVID‑19 и его вирусе SARS‑CoV‑2. В этих плотных текстах скрываются критически важные сведения о белках вируса — молекулярных машинах, которые помогают ему заражать наши клетки и являются основными мишенями для лекарств и вакцин. Но никто не может прочесть всё. В этом исследовании поднимается простой, но мощный вопрос: можно ли научить компьютеры автоматически выявлять и перечислять белки вируса в тексте достаточно быстро и точно, чтобы помогать исследователям не отставать?
Преобразование перегруженного текста в пригодные данные
Когда учёные пишут о SARS‑CoV‑2, они используют путаную смесь полных названий, сокращений и прозвищ для своих белков. Один и тот же белок может встречаться как «шиповидный белок», «S» или быть скрыт в выражениях вроде «домен, связывающий рецептор шипа». Чтобы понимать такой язык в масштабе, компьютерам сначала нужен корпус — тщательно размеченная коллекция предложений, где эксперты выделили каждое упоминание белка. Авторы создали такой ресурс, просеяв около 200 000 аннотаций из PubMed и вручную размечая все упоминания белков SARS‑CoV‑2 в релевантных предложениях. После очистки и проверки они получили 7 159 предложений и 12 660 отмеченных упоминаний белков, которые служат эталоном для обучения и тестирования алгоритмов.
Обучение машин находить названия белков вируса
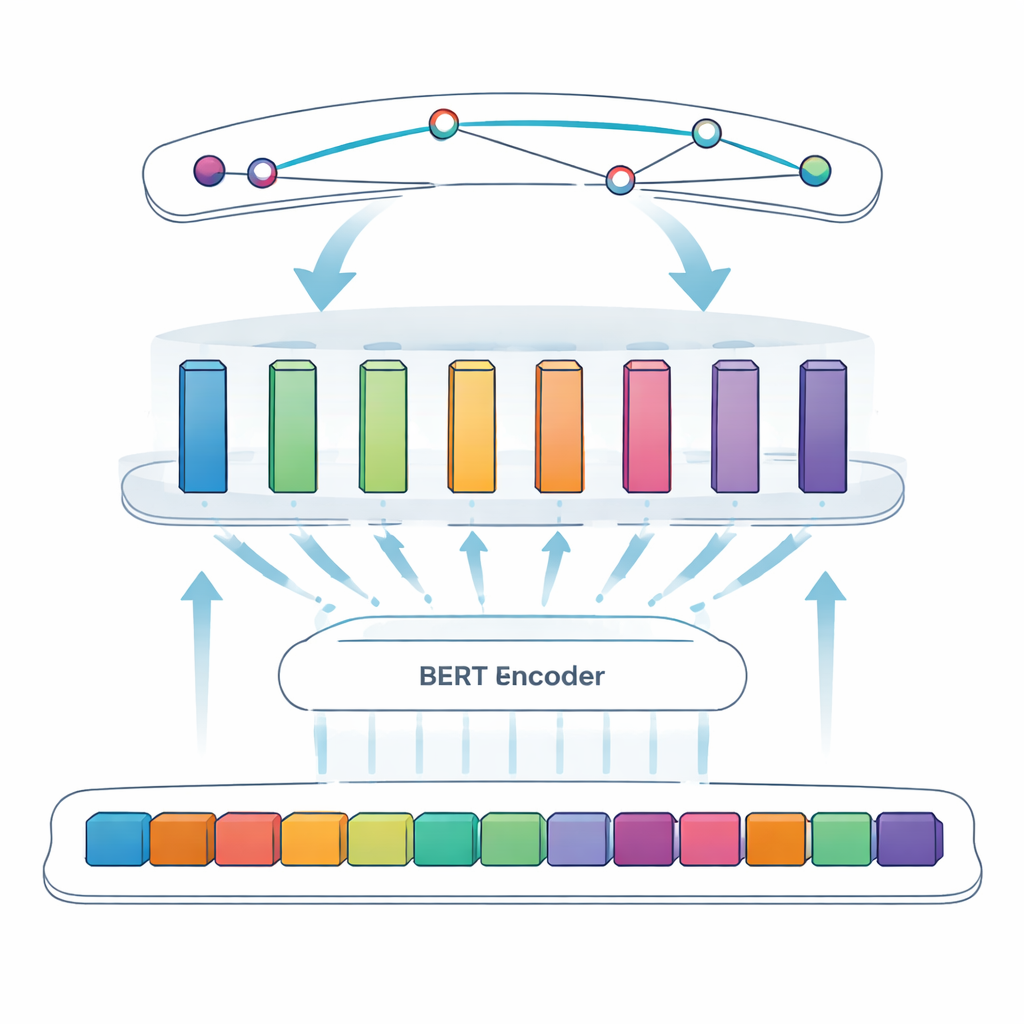
Ключевая задача в этом исследовании называется распознаванием именованных сущностей: заставить компьютер выделять определённые элементы — в данном случае вирусные белки — из свободного текста. Ранние подходы опирались на вручную составленные правила или словари известных терминов, которые даёт сбой при нерегулярных названиях или их эволюции. Новые системы используют глубокое обучение, где модель учится шаблонам напрямую по примерам. Команда опирается на BERT — языковую модель, которая читает текст в обоих направлениях и выучивает богатые представления слов на основе контекста. Поверх BERT они применяют подход «SPAN»: вместо по‑токенового решения о том, лежит ли токен внутри сущности, модель напрямую предсказывает позиции начала и конца каждого упоминания белка. Это упрощает обработку сложных случаев, таких как вложенные или многословные названия.
Добавление интеллектуальных строительных блоков в модель
Чтобы ещё больше улучшить систему, авторы вводят адаптивный модульный полносвязный слой, который можно представить как несколько небольших экспертных модулей между BERT и финальным детектором спанов. Разные модули специализируются на разных типах паттернов — например, поверхностные признаки вроде дефисов и смешанных буквенно‑цифровых строк или тонкие контекстные подсказки, указывающие, что короткая буква «S» на самом деле обозначает белок. Адаптивный механизм взвешивания затем решает для каждого предложения, каким модулям доверять больше, объединяя их выходы в более сильный сигнал перед шагом предсказания спанов. Такая архитектура позволяет модели гибко фокусироваться на наиболее информативных подсказках для каждого конкретного фрагмента текста.
Проверка подхода в деле
Исследователи строго сравнили свою адаптивную модульную модель BERT–SPAN с несколькими устоявшимися системами, включая популярную модель BiLSTM–CRF и стандартную версию BERT–SPAN без модульных улучшений. По стандартным метрикам точности они обнаружили, что традиционная модель BiLSTM–CRF достигает F1‑метрики (баланс точности и полноты) около 80,8 процента на их датасете белков SARS‑CoV‑2. Переход на BERT–SPAN сам по себе поднял производительность до 91,85 процента. Добавление адаптивного модульного слоя увеличило F1 ещё до 93,66 процента — значимый прирост в такой зрелой области. Тщательные «абляционные» эксперименты — поочерёдное удаление компонентов архитектуры — показали, что и модульная структура, и адаптивное взвешивание вносят вклад в улучшение, особенно снижая ошибки в границах сущностей и путаницу между похожими аббревиатурами.
Чем это помогает будущим исследованиям
Для непрофессионального читателя главный итог в том, что авторы создали и высококачественный набор данных, и более умную систему чтения, способную надёжно распознавать белки SARS‑CoV‑2 в научном тексте. Преобразуя небрежный язык в структурированные списки сущностей, их система упрощает создание графов знаний, картирование взаимодействий вирусных белков с молекулами хозяина и отслеживание накопления доказательной базы по конкретным мишеням. Практически это означает, что компьютеры могут взять на себя больше утомительной работы по майнингу текста, освобождая человеческих экспертов для интерпретации результатов и проектирования экспериментов. Исследование показывает, что сочетание мощных языковых моделей с модульными, адаптивными компонентами — перспективный рецепт для просеивания биомедицинской литературной лавины — не только для исследований коронавируса, но и для многих будущих задач, где наука опережает наши возможности чтения.
Цитирование: Shi, X., Fei, Z., Nkhata, A. et al. Optimization and comparison research on adaptive modularization BERT-SPAN model for named entity recognition of SARS-CoV-2 virus proteins. Sci Rep 16, 14207 (2026). https://doi.org/10.1038/s41598-026-44317-7
Ключевые слова: белки SARS‑CoV‑2, распознавание именованных сущностей, биомедицинский текстовый майнинг, языковая модель BERT, графы знаний