Clear Sky Science · he
אופטימיזציה והשוואת מחקר על מודוליות אדפטיבית במודל BERT-SPAN לזיהוי ישויות של חלבוני נגיף SARS-CoV-2
מדוע חשוב למצוא שמות חלבונים במאמרים
כל שבוע מתפרסמות ברשת אלפי מאמרים מדעיים חדשים על COVID-19 והנגיף שלו, SARS-CoV-2. טמונים במאמרים הצפופים האלה רמזים חיוניים על חלבוני הנגיף — מכונות מולקולריות המסייעות לו להדביק תאים ומהוות מטרות מרכזיות לתרופות ולחיסונים. אך איש אינו יכול לקרוא הכול. המחקר הזה עוסק בשאלה פשוטה אך חזקה: האם נוכל ללמד מחשבים לזהות ולרשום אוטומטית את חלבוני הנגיף בטקסט, במהירות ובדיוק שיסייעו לחוקרים לעמוד בקצב?
הפיכת טקסט צפוף לנתונים ניתנים לשימוש
כשמדענים כותבים על SARS-CoV-2 הם משתמשים בתערובת מבלבלת של שמות מלאים, קיצורים וכינויים לחלבוניו. אותו חלבון עשוי להופיע כ"חלבון הספייק", "S" או כחלק ממבנים כגון "תחום קשר-לקולטן של הספייק". כדי להבין שפה כזו בקנה מידה גדול, מחשבים צריכים תחילה "קורפוס" — אוסף משפטים מתויג בקפידה שבו מומחים הדגישו כל אזכור חלבון. המחברים בנו משאב כזה על ידי סינון בערך 200,000 תקצירים של קורונה מ‑PubMed ולאחר מכן תיוג ידני של כל אזכור חלבוני SARS-CoV-2 במשפטים הרלוונטיים. לאחר ניקוי ובדיקות צולבות, נותרו 7,159 משפטים ו‑12,660 אזכורים מתוייגים של חלבונים שמשמשים כאמת-אדמה לאימון ובדיקה של האלגוריתמים.
ללמד מכונות לקרוא שמות חלבוני נגיף
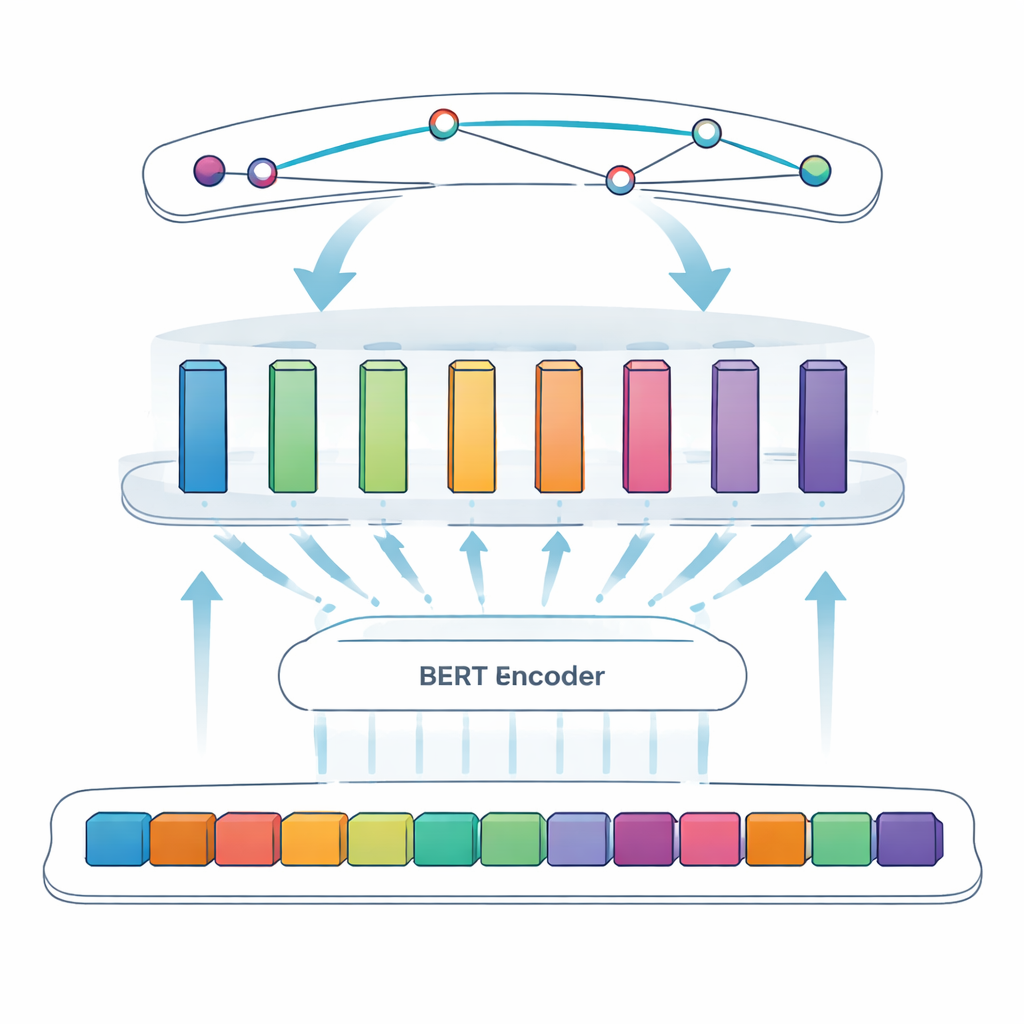
המשימה המרכזית במחקר זה נקראת זיהוי ישויות בשם: לגרום למחשב לזהות פריטים מסוימים — במקרה זה, חלבוני נגיף — מתוך טקסט חופשי. גישות מוקדמות הסתמכו על חוקים שנכתבו ידנית או על רשימות של מונחים ידועים, שקרסות כששמות אינם סדירים או משתנים. מערכות חדשות משתמשות בלמידה עמוקה, שבה המודל לומד דפוסים ישירות מדוגמאות. הצוות בונה על BERT, מודל שפה שקורא טקסט בשני הכיוונים ומייצר ייצוגים עשירים של מילים על בסיס ההקשר שלהן. מעל BERT הם משתמשים בגישה בשם "SPAN": במקום להחליט מילה־מילה האם כל טוקן נמצא בתוך ישות, המודל חוזה ישירות את מיקומי ההתחלה והסיום של כל אזכור חלבון. זה מקל על טיפול במקרים מסובכים כמו שמות מקוננים או מרובי מילים.
הוספת רכיבי בניין חכמים למודל
כדי לשפר עוד יותר את המערכת, המחברים מציגים שכבת פידפורוורד מודולרית אדפטיבית, שניתן לראות בה כמה מודולים מומחים קטנים המתווספים בין BERT לגלאי ה‑span הסופי. מודולים שונים מתמחים בסוגים שונים של דפוסים — למשל תכונות שטחיות כגון מקפים ותערובות של אותיות ומספרים, או רמזים הקשריים עדינים שמצביעים על כך שאות קצרה כמו "S" היא בפועל שם חלבון. מנגנון משקלול אדפטיבי מחליט אז, עבור כל משפט, באילו מודולים לסמוך יותר, ומשלב את תוצריהם לאות משולב וחזק יותר לפני שלב חיזוי ה‑span. עיצוב זה מאפשר למודל להתמקד באופן גמיש ברמזים המידעיים ביותר עבור כל מקטע טקסט ספציפי.
בחינת הגישה במבחן
החוקרים השוו בקפדנות את מודל ה‑BERT–SPAN המודולרי האדפטיבי שלהם למספר מערכות מבוססות, כולל מודל BiLSTM–CRF נפוץ וגרסת BERT–SPAN סטנדרטית ללא שיפורים מודולריים. באמצעות מדדי דיוק סטנדרטיים הם מצאו שמודל ה‑BiLSTM–CRF המסורתי הגיע לציון F1 (איזון בין דיוק לכיסוי) של כ‑80.8 אחוזים על מאגר הנתונים שלהם של חלבוני SARS-CoV-2. המעבר ל‑BERT–SPAN בלבד העלה את הביצועים ל‑91.85 אחוזים. הוספת השכבה המודולרית האדפטיבית הדחפה את ציון ה‑F1 ל‑93.66 אחוזים — שיפור משמעותי בתחום בוגר זה. ניסויי "אבלאציה" מדודים — הסרת חלקים מהארכיטקטורה אחד אחד — הראו ששני המהלכים, המודולריזציה והמשקלול האדפטיבי, תרמו לשיפור, במיוחד על ידי הקטנת טעויות גבול ובלבול בין קיצורים דומים.
כיצד זה מסייע למחקר עתידי
בעבור קורא לא מקצועי, המסקנה המרכזית היא שהמחברים בנו גם מאגר נתונים באיכות גבוהה וגם מנוע קריאה חכם יותר שיכול לזהות באופן אמין חלבוני SARS‑CoV‑2 בטקסט מדעי. בהפיכת שפה מבולגנת לרשימות ישויות ממוסדות, המערכת שלהם מקלה מאוד על בניית גרפי ידע, מיפוי אילו חלבונים ויראליים מתקשרים עם אילו מולקולות מארחות וגם מעקב אחרי האיכויות העולות של העדויות לגבי מטרות ספציפיות. במונחים מעשיים, המשמעות היא שמחשבים יכולים לשאת בחלק ניכר מעבודת הכרייה הטרחנית של טקסט, ולשחרר מומחים אנושיים להתמקד בפרשנות התוצאות ובעיצוב ניסויים. המחקר מדגים כי שילוב מודלי שפה חזקים עם רכיבים מודולריים אדפטיביים הוא מתכון מבטיח לנף את הצפה של הספרות הביומדית — לא רק למחקר על קורונה, אלא גם לאתגרים עתידיים שבהם המדע מציף את יכולת הקריאה שלנו.
ציטוט: Shi, X., Fei, Z., Nkhata, A. et al. Optimization and comparison research on adaptive modularization BERT-SPAN model for named entity recognition of SARS-CoV-2 virus proteins. Sci Rep 16, 14207 (2026). https://doi.org/10.1038/s41598-026-44317-7
מילות מפתח: חלבוני SARS-CoV-2, זיהוי ישויות בשם, כריית טקסט ביומדית, מודל השפה BERT, גרפי ידע