Clear Sky Science · pl
Badania optymalizacyjne i porównawcze adaptacyjnego modułowego modelu BERT-SPAN do rozpoznawania nazwanych encji białek wirusa SARS-CoV-2
Dlaczego wykrywanie nazw białek w publikacjach ma znaczenie
Co tydzień w internecie pojawiają się tysiące nowych artykułów naukowych o COVID-19 i jego wirusie, SARS-CoV-2. W gęstych tekstach tych prac ukryte są kluczowe wskazówki dotyczące białek wirusa — molekularnych „maszyn”, które umożliwiają mu zakażanie komórek i które stanowią główne cele dla leków i szczepionek. Jednak nikt nie jest w stanie przeczytać wszystkiego. W tym badaniu zadano proste, ale pojemne pytanie: czy można nauczyć komputery automatycznie wykrywać i katalogować nazwy białek wirusa w tekstach na tyle szybko i dokładnie, by pomagać badaczom nadążać za literaturą?
Zamiana zatłoczonego tekstu w użyteczne dane
Gdy naukowcy piszą o SARS-CoV-2, używają mylącej mieszanki pełnych nazw, skrótów i potocznych określeń białek. To samo białko może występować jako „spike protein”, „S” lub być ukryte w frazach typu „receptor-binding domain of spike”. Aby zrozumieć taki język na dużą skalę, komputer potrzebuje najpierw korpusu — starannie oznakowanego zbioru zdań, w którym eksperci wyróżnili każde wystąpienie białka. Autorzy stworzyli takie zasoby, przejrzyście około 200 000 abstraktów koronawirusowych z PubMed i ręcznie oznaczyli każde wystąpienie białka SARS-CoV-2 w istotnych zdaniach. Po oczyszczeniu i weryfikacji powstało 7 159 zdań i 12 660 oznaczonych wystąpień białek, które służą jako zbiór odniesienia do trenowania i testowania algorytmów.
Nauczanie maszyn rozpoznawania nazw białek wirusa
Głównym zadaniem w tym badaniu jest rozpoznawanie nazwanych encji: skłonienie komputera do wyłuskania konkretnych elementów — w tym przypadku białek wirusowych — z tekstu swobodnego. Wcześniejsze podejścia opierały się na ręcznie tworzonych regułach lub listach terminów, które zawodzą, gdy nazewnictwo jest nieregularne lub się zmienia. Nowsze systemy wykorzystują uczenie głębokie, gdzie model uczy się wzorców bezpośrednio z przykładów. Zespół bazuje na BERT, modelu językowym, który czyta tekst w obie strony jednocześnie i uczy się bogatych reprezentacji słów w kontekście. Na bazie BERT zastosowano podejście „SPAN”: zamiast decydować token po tokenie, czy należy on do encji, model bezpośrednio przewiduje pozycje początku i końca każdego wystąpienia białka. Ułatwia to obsługę trudnych przypadków, takich jak nazwy zagnieżdżone lub wielowyrazowe.
Dodanie inteligentnych modułów do modelu
Aby jeszcze ulepszyć system, autorzy wprowadzają adaptacyjną modułową warstwę feedforward, którą można traktować jako kilka małych modułów‑ekspertów umieszczonych między BERT a końcowym detektorem spanów. Różne moduły specjalizują się w różnych typach wzorców — na przykład cechach powierzchniowych, takich jak łączniki i mieszane litery i cyfry, albo subtelnych wskazówkach kontekstowych sygnalizujących, kiedy krótka litera jak „S” rzeczywiście oznacza białko. Mechanizm adaptacyjnego ważenia decyduje następnie, które moduły zaufać bardziej dla każdego zdania, łącząc ich wyjścia w silniejszy sygnał przed etapem przewidywania spanów. Taka konstrukcja pozwala modelowi elastycznie koncentrować się na najbardziej informatywnych wskazówkach dla konkretnego fragmentu tekstu.
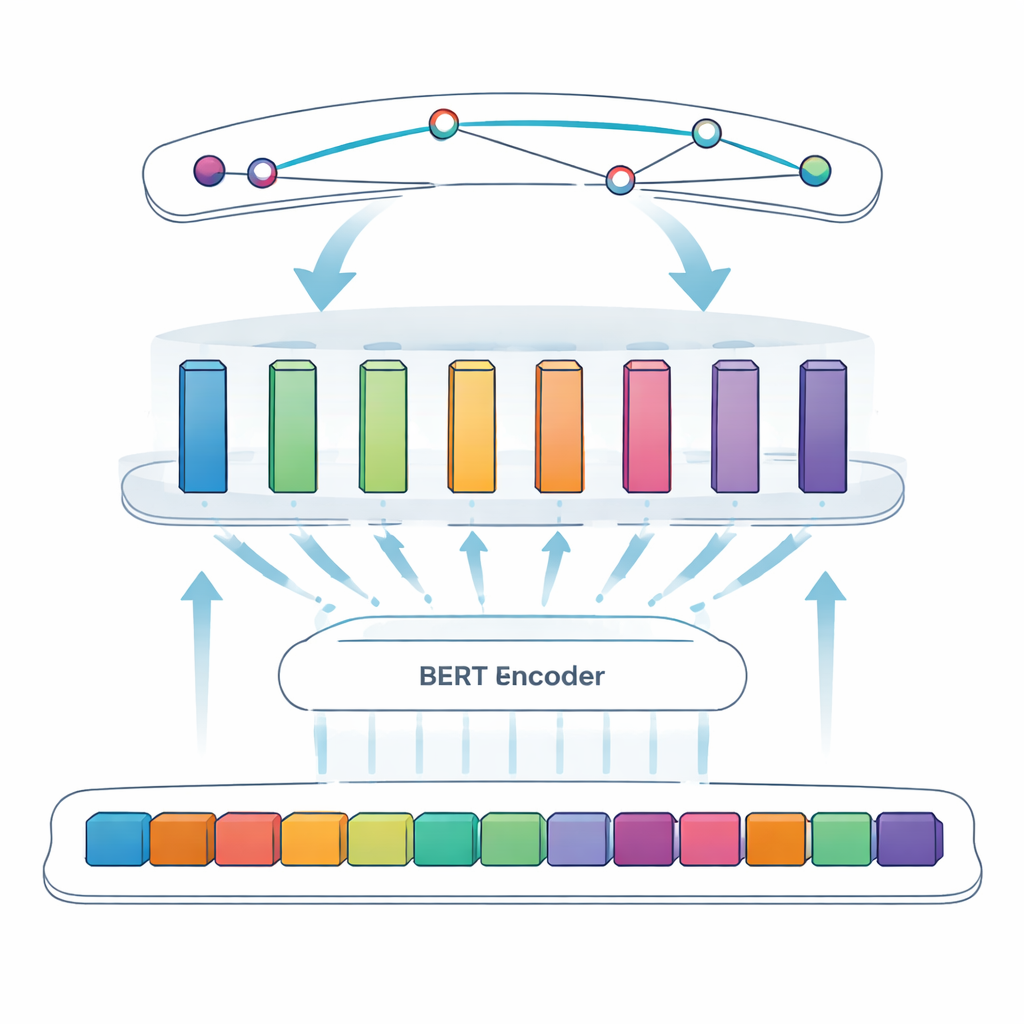
Wystawienie podejścia na próbę
Badacze rygorystycznie porównali swój adaptacyjny modułowy model BERT–SPAN z kilkoma ustalonymi systemami, w tym popularnym modelem BiLSTM–CRF oraz standardową wersją BERT–SPAN bez ulepszeń modułowych. Korzystając ze standardowych miar dokładności, stwierdzili, że tradycyjny model BiLSTM–CRF osiągnął wartość F1 (miara równowagi precyzji i czułości) na poziomie około 80,8 procent na ich zbiorze białek SARS-CoV-2. Przejście na sam BERT–SPAN podniosło wydajność do 91,85 procent. Dodanie adaptacyjnej warstwy modułowej zwiększyło wynik F1 do 93,66 procent, co jest znaczącym przyrostem w tak dojrzałej dziedzinie. Starannie przeprowadzone eksperymenty „ablacyjne” — usuwanie elementów architektury po kolei — wykazały, że zarówno modularizacja, jak i adaptacyjne ważenie przyczyniły się do poprawy, szczególnie przez zmniejszenie błędów granic i pomyłek między podobnymi skrótami.
Jak to pomaga przyszłym badaniom
Dla czytelnika niebędącego specjalistą kluczowym rezultatem jest to, że autorzy stworzyli zarówno wysokiej jakości zbiór danych, jak i inteligentniejszy silnik czytający, który niezawodnie rozpoznaje białka SARS-CoV-2 w tekstach naukowych. Przekształcając nieuporządkowany język w strukturalne listy encji, ich system znacznie ułatwia budowę grafów wiedzy, mapowanie, które białka wirusa wchodzą w interakcje z jakimi cząsteczkami gospodarza, oraz śledzenie, jak gromadzi się dowód dotyczący konkretnych celów. W praktyce oznacza to, że komputery mogą przejąć większą część żmudnej pracy związanej z wydobywaniem informacji z tekstu, uwalniając ekspertów ludzkich do interpretacji wyników i projektowania eksperymentów. Badanie pokazuje, że łączenie potężnych modeli językowych z modułowymi, adaptacyjnymi komponentami to obiecujący przepis na przeczesywanie potoku literatury biomedycznej — nie tylko w kontekście koronawirusa, lecz także wielu przyszłych wyzwań, gdy tempo nauki wyprzedza nasze możliwości lektury.
Cytowanie: Shi, X., Fei, Z., Nkhata, A. et al. Optimization and comparison research on adaptive modularization BERT-SPAN model for named entity recognition of SARS-CoV-2 virus proteins. Sci Rep 16, 14207 (2026). https://doi.org/10.1038/s41598-026-44317-7
Słowa kluczowe: białka SARS-CoV-2, rozpoznawanie nazwanych encji, wydobywanie tekstu biomedycznego, model językowy BERT, grafy wiedzy