Clear Sky Science · ar
بحث في تحسين ومقارنة نموذج BERT-SPAN المُجزَّأ التكيفي للتعرّف على الكيانات المسماة لبروتينات فيروس SARS-CoV-2
لماذا يهم العثور على أسماء البروتينات في الأوراق العلمية
كل أسبوع تظهر آلاف الأوراق العلمية الجديدة حول كوفيد-19 وفيروسه SARS-CoV-2 على الإنترنت. داخل هذه المقالات المكدّسة تكمن دلائل حاسمة حول بروتينات الفيروس — آلات جزيئية تساعده على إصابة خلايانا وتشكل أهدافًا رئيسية للأدوية واللقاحات. لكن لا يمكن لأي إنسان قراءة كل شيء. تواجه هذه الدراسة سؤالًا بسيطًا لكنه قوي: هل يمكننا تعليم الحواسيب لتحدد تلقائيًا وتدرج بروتينات الفيروس في النصوص بسرعة ودقّة تكفي لمساعدة الباحثين على المواكبة؟
تحويل النص المزدحم إلى بيانات قابلة للاستخدام
عندما يكتب العلماء عن SARS-CoV-2، يستخدمون مزيجًا محيرًا من الأسماء الكاملة والاختصارات والألقاب لبروتيناته. قد يظهر نفس البروتين كـ «spike protein» أو «S» أو مدفونًا داخل عبارات مثل «receptor-binding domain of spike». لفهم مثل هذه اللغة على نطاق واسع، تحتاج الحواسيب أولًا إلى «مجمّع نصوص» — مجموعة من الجمل المعلّمة بعناية حيث أشارت الخبراء إلى كل ظهور لبروتين. بنى المؤلفون مثل هذا المورد عن طريق فحص نحو 200,000 ملخّص عن فيروس كورونا من PubMed ثم وسم كل إشارة لبروتين SARS-CoV-2 يدويًا في الجمل ذات الصلة. بعد التنقية والتحقق المتبادل، حصلوا على 7,159 جملة و12,660 إشارة لبروتين معنونة تُستخدم كحقيقة مرجعية لتدريب واختبار الخوارزميات.
تعليم الآلات قراءة أسماء بروتينات الفيروس
المهمة الأساسية في هذه الدراسة تُسمّى التعرّف على الكيانات المسماة: جعل الحاسوب يلتقط عناصر محددة — في هذه الحالة بروتينات فيروسية — من النص الحر. كانت الطرق السابقة تعتمد على قواعد مصمّمة يدويًا أو قوائم مصطلحات معروفة، وهو نهج يفشل عندما تكون التسمية غير منتظمة أو تتغير. تستخدم الأنظمة الحديثة التعلم العميق، حيث يتعلم النموذج الأنماط مباشرة من الأمثلة. يبني الفريق على BERT، نموذج لغوي يقرأ النص في كلا الاتجاهين ويتعلّم تمثيلات غنية للكلمات بناءً على سياقها. وفوق BERT، يستخدمون نهج «SPAN»: بدلًا من تقرير، كلمة بكلمة، ما إذا كان كل رمز داخل كيان، يتنبأ النموذج مباشرة بمواقع البداية والنهاية لكل إشارة لبروتين. هذا يُسهّل التعامل مع حالات معقّدة مثل الأسماء المتداخلة أو متعددة الكلمات.
إضافة كتل بناء ذكية إلى النموذج
لتعزيز النظام أكثر، قدّم المؤلفون طبقة تغذية أمامية مُجزّأة تكيفية، التي يمكن تصورها على أنها عدة وحدات خبراء صغيرة تقع بين BERT وكاشف الفواصل النهائي. تتخصّص وحدات مختلفة بأنماط مختلفة — على سبيل المثال، ميزات السطح مثل الشرطات والحروف والأرقام المختلطة، أو دلائل سياقية دقيقة تشير إلى متى تكون حرفًا قصيرًا مثل «S» فعليًا اسم بروتين. ثم تقرر آلية وزن تكيفية، لكل جملة على حدة، أي الوحدات يجب الوثوق بها أكثر، وتجمع مخرجاتها إلى إشارة إجمالية أقوى قبل خطوة التنبؤ بالفواصل. يتيح هذا التصميم للنموذج التركيز بمرونة على الدلالات الأكثر إفادة لكل قطعة نصية معينة.
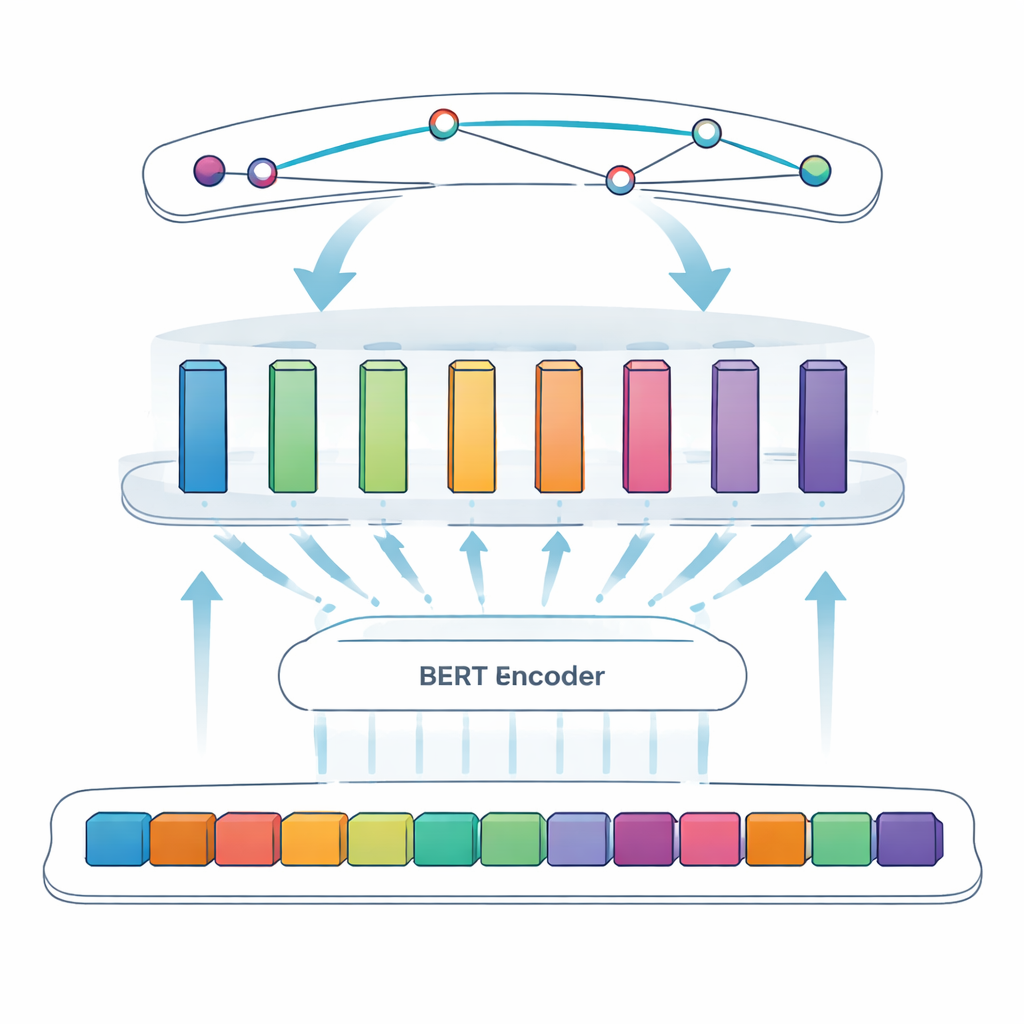
اختبار النهج
قارن الباحثون بدقّة نموذج BERT–SPAN المُجزَّأ التكيفي بعدد من الأنظمة المعروفة، بما في ذلك نموذج BiLSTM–CRF الشائع وإصدار قياسي من BERT–SPAN بدون تحسينات التجزئة. باستخدام مقاييس الدقة المعيارية، وجدوا أن نموذج BiLSTM–CRF التقليدي حقق قيمة F1 (توازن الدقّة والاستدعاء) تقارب 80.8 في المئة على مجموعة بيانات بروتينات SARS-CoV-2 الخاصة بهم. الانتقال إلى BERT–SPAN وحده رفع الأداء إلى 91.85 في المئة. إضافة الطبقة المجزّأة التكيفية دفعت قيمة F1 إلى 93.66 في المئة، وهو تحسّن معنوي في مجال وصل إلى مرحلة نضج. أظهرت تجارب «الإزالة» الدقيقة — حذف أجزاء من البنية واحدة تلو الأخرى — أن كلًا من التجزئة والوزن التكيفي ساهمَا في هذا التحسّن، خاصة بتقليل أخطاء الحدود والارتباك بين الاختصارات المماثلة.
كيف يساعد هذا البحث الأعمال المستقبلية
للقارئ العام، النتيجة الأساسية هي أن المؤلفين بنوا كلًا من مجموعة بيانات عالية الجودة ومحرك قراءة أذكى يمكنه التعرف بموثوقية على بروتينات SARS-CoV-2 في النص العلمي. من خلال تحويل اللغة الفوضوية إلى قوائم منظمة من الكيانات، يجعل نظامهم بناء الرسوم البيانية المعرفية، وتتبع أي البروتينات الفيروسية تتفاعل مع أي جزيئات مضيفة، ورصد تراكم الأدلة حول أهداف معينة، أمرًا أسهل بكثير. عمليًا، يعني هذا أن الحواسيب يمكنها أن تتولى جزءًا أكبر من العمل المرهق في تنقيب النصوص، مما يحرر الخبراء البشريين للتركيز على تفسير النتائج وتصميم التجارب. توضح الدراسة أن دمج نماذج لغوية قوية مع مكونات مجزأة وتكيفية هو وصفة واعدة للتعامل مع فيض الأدبيات الطبية الحيوية — ليس فقط لبحوث فيروس كورونا، بل للعديد من التحديات المستقبلية حيث تتجاوز وتيرة الاكتشاف قدرتنا على القراءة.
الاستشهاد: Shi, X., Fei, Z., Nkhata, A. et al. Optimization and comparison research on adaptive modularization BERT-SPAN model for named entity recognition of SARS-CoV-2 virus proteins. Sci Rep 16, 14207 (2026). https://doi.org/10.1038/s41598-026-44317-7
الكلمات المفتاحية: بروتينات SARS-CoV-2, التعرّف على الكيانات المسماة, تنقيب النصوص الطبية الحيوية, نموذج اللغة BERT, رسوم بيانية معرفية