Clear Sky Science · nl
Optimalisatie- en vergelijkingsonderzoek naar adaptief gemoduleerd BERT-SPAN-model voor benoemde-entiteitsherkenning van SARS-CoV-2-eiwitten
Waarom het vinden van eiwitnamen in artikelen ertoe doet
Elke week verschijnen er online duizenden nieuwe wetenschappelijke artikelen over COVID-19 en het bijbehorende virus, SARS-CoV-2. Verborgen in deze dichte teksten liggen cruciale aanwijzingen over de eiwitten van het virus—moleculaire machines die helpen bij het infecteren van cellen en belangrijke doelwitten zijn voor geneesmiddelen en vaccins. Niemand kan echter alles lezen. Deze studie pakt een eenvoudige maar krachtige vraag aan: kunnen we computers leren automatisch de eiwitten van het virus in tekst te herkennen en op te sommen, snel en nauwkeurig genoeg om onderzoekers bij te houden?
Verwarrende tekst omzetten in bruikbare data
Wanneer wetenschappers over SARS-CoV-2 schrijven, gebruiken ze vaak een verwarrende mix van volledige namen, afkortingen en bijnamen voor zijn eiwitten. Hetzelfde eiwit kan bijvoorbeeld als “spike protein”, “S” of verstopt in zinnen als “receptor-binding domain of spike” voorkomen. Om zulke taal op schaal te begrijpen, hebben computers eerst een corpus nodig – een zorgvuldig gelabelde verzameling zinnen waarin experts elk eiwitvermeld hebben gemarkeerd. De auteurs bouwden zo’n bron op door ongeveer 200.000 coronavirusabstracts uit PubMed te screenen en vervolgens elke vermelding van SARS-CoV-2-eiwitten in relevante zinnen handmatig te labelen. Na opschonen en controle kwamen ze uit op 7.159 zinnen en 12.660 gelabelde eiwitvermeldingen die dienen als grondwaarheid voor het trainen en testen van algoritmen.
Mensen lezen leren machines eiwitnamen herkennen
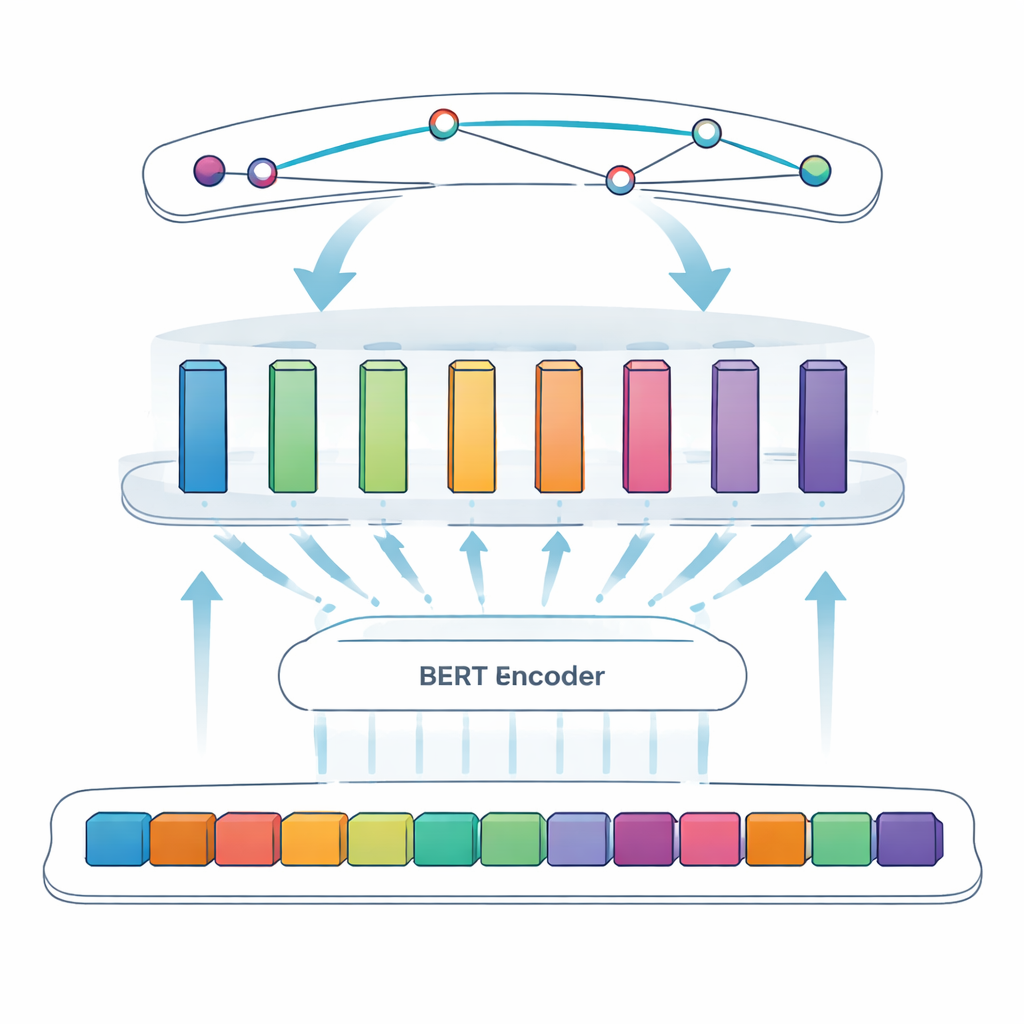
De kernopdracht in deze studie heet benoemde-entiteitsherkenning: een computer leren specifieke items—in dit geval virale eiwitten—uit vrije tekst te halen. Vroegere benaderingen leunden op handgemaakte regels of lijsten met bekende termen, wat faalt wanneer naamgeving onregelmatig is of verandert. Nieuwere systemen gebruiken deep learning, waarbij een model patronen direct uit voorbeelden leert. Het team bouwt voort op BERT, een taalmodel dat tekst in beide richtingen tegelijk leest en rijke representaties van woorden leert op basis van hun context. Bovenop BERT gebruiken ze een SPAN-benadering: in plaats van token voor token te beslissen of elk woorddeel binnen een entiteit valt, voorspelt het model rechtstreeks de start- en eindposities van elke eiwitvermelding. Dat maakt het eenvoudiger om lastige gevallen zoals geneste of meerwoordige namen af te handelen.
Slimme bouwstenen toevoegen aan het model
Om het systeem verder aan te scherpen, introduceren de auteurs een adaptieve gemoduleerde feedforward-laag, die kan worden gezien als meerdere kleine expertmodules tussen BERT en de uiteindelijke span-detector. Verschillende modules specialiseren zich in verschillende soorten patronen—bijvoorbeeld oppervlaktesignalementen zoals koppeltekens en gemengde letters en cijfers, of subtiele contextuele aanwijzingen die aangeven wanneer een korte letter zoals “S” daadwerkelijk een eiwitnaam is. Een adaptief weegmechanisme beslist dan voor elke zin welke modules meer vertrouwen verdienen en combineert hun output tot een sterker totaal signaal vóór de span-voorspelling. Dit ontwerp stelt het model in staat zich flexibel te richten op de meest informatieve aanwijzingen voor elk specifiek stuk tekst.
Het concept op de proef stellen
De onderzoekers vergeleken hun adaptief gemoduleerde BERT–SPAN-model grondig met verschillende gevestigde systemen, waaronder een veelgebruikt BiLSTM–CRF-model en een standaard BERT–SPAN-versie zonder modulaire verbeteringen. Met standaard nauwkeurigheidsmaten vonden ze dat het traditionele BiLSTM–CRF-model een F1-score (een balans tussen precisie en recall) van ongeveer 80,8 procent behaalde op hun SARS-CoV-2-eiwitdataset. Overschakelen naar alleen BERT–SPAN verhoogde de prestatie naar 91,85 procent. Het toevoegen van de adaptieve gemoduleerde laag duwde de F1-score verder naar 93,66 procent, een betekenisvolle verbetering in een rijp onderzoeksveld. Zorgvuldige ablatietests—waarbij onderdelen van de architectuur één voor één werden verwijderd—toonden aan dat zowel modularisatie als adaptieve weging bijdroegen aan de verbetering, vooral door grensfouten te verminderen en verwarring tussen vergelijkbare afkortingen te beperken.
Hoe dit toekomstig onderzoek helpt
Voor een niet-specialistische lezer is de kernuitkomst dat de auteurs zowel een dataset van hoge kwaliteit als een slimmere leesmotor hebben gebouwd die SARS-CoV-2-eiwitten betrouwbaar kan herkennen in wetenschappelijke tekst. Door rommelige taal om te zetten in gestructureerde lijsten van entiteiten, maakt hun systeem het veel eenvoudiger kennisgrafieken te bouwen, in kaart te brengen welke virale eiwitten met welke gastheer-moleculen interageren en te volgen hoe bewijslast rond specifieke doelwitten zich ophoopt. In praktische termen betekent dit dat computers een groter deel van het saaie text-miningwerk kunnen dragen, waardoor menselijke experts zich kunnen richten op het interpreteren van resultaten en het ontwerpen van experimenten. De studie toont dat het koppelen van krachtige taalmodellen aan modulaire, adaptieve componenten een veelbelovende aanpak is om de stortvloed aan biomedische literatuur te verwerken—niet alleen voor coronavirusonderzoek, maar ook voor toekomstige uitdagingen waarin de wetenschap sneller gaat dan ons vermogen om alles te lezen.
Bronvermelding: Shi, X., Fei, Z., Nkhata, A. et al. Optimization and comparison research on adaptive modularization BERT-SPAN model for named entity recognition of SARS-CoV-2 virus proteins. Sci Rep 16, 14207 (2026). https://doi.org/10.1038/s41598-026-44317-7
Trefwoorden: SARS-CoV-2-eiwitten, benoemde-entiteitsherkenning, biomedische tekstmining, BERT-taalmodel, kennisgrafieken