Clear Sky Science · zh
多模态情感分析:结合图像与文本特征描述符的混合分类模型
你的照片和帖子为何重要
人们每天通过短消息、餐食照片、产品图片和表情反应图分享观点。公司、研究者和应用都想知道:这些内容背后的情绪是积极的还是消极的?传统的情感分析大多只看文本,忽视图片所传达的信息。本文提出了一种同时解读文字与图像情感的新方法,旨在提高在真实社交和评论数据上的情感检测准确性与可靠性。
从多视角观察情感
本研究聚焦于多模态情感分析,即利用多种信号来理解情绪——在此情形下为书面文本和图像。人们很少只用一种方式表达自己:一条欢快的说明可能配上阴郁的照片,或讽刺的句子可能被俏皮的表情符号缓和。现有系统在融合这些不同线索时常显不足,往往把文本或图像单独处理。作者回顾了基于循环神经网络、变换器或简单特征组合的既有工作,指出这些方法往往忽略书写与呈现之间的微妙关联,或需要极大的训练资源。
在理解之前先清理杂乱数据
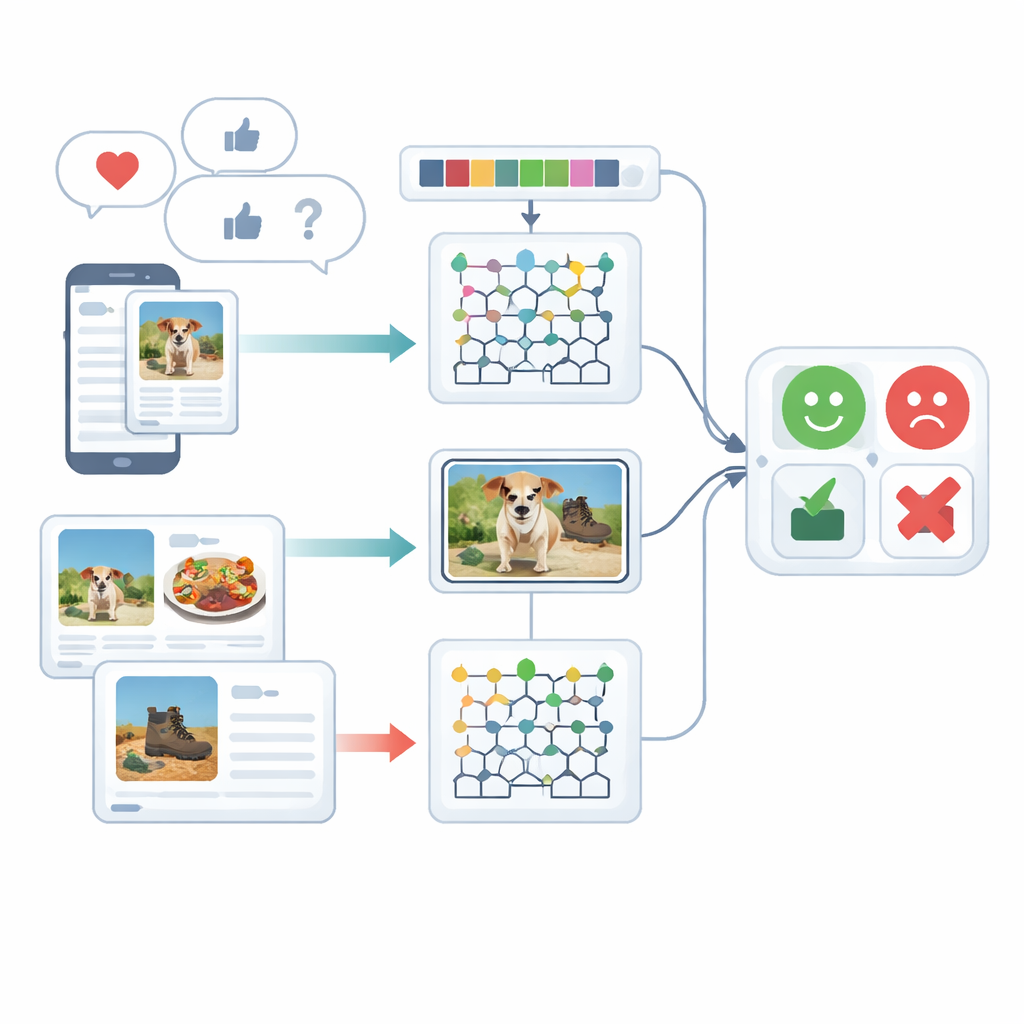
在对意见进行分类前,原始数据需要先整理。对文本,系统将句子拆分成片段,去除像“the”或“and”这类常见填充词,并将词语还原为基本形式,以便相近词汇能被统一处理。系统也特别关注表情符号,因为这些小图像携带强烈的情绪线索。对图像而言,该框架使用快速物体检测方法定位照片中的主要物体——例如盘中的食物或桌上的电子设备。这一步剔除背景干扰,使后续处理能聚焦于判断情感时真正重要的图像部分。
教模型注意什么
清理之后,系统将文本和图像都转为丰富的数值描述。文本方面,它统计短词序列(N-gram)、追踪表情符号使用情况,并采用经过改进的经典加权方法TF–IDF。该改进确保在不同类型文档中出现不均的情绪性词汇能够更突出。图像方面,方法捕捉两类视觉细节:颜色与纹理模式以及局部形状。它优化了已知的纹理描述符,以保留颜色与边缘方向的细微差异,并将其与一种能紧凑表示面部或物体区域形状与纹理的技术结合。合在一起,这些特征帮助系统区分例如温馨的餐厅场景与光线刺眼、令人不适的环境。
将两套智能引擎融合为一个决策
该框架的核心是一个混合模型,它用独立的深度学习引擎分别处理文本和图像,然后合并它们的判断。文本特征送入Deep Maxout网络,这是一种能学习灵活决策边界的神经模型;其内部参数由一种受白鲸猎食与移动模式启发的自定义优化过程进行调优。该优化器高效搜索能最小化分类错误的权重组合。与此同时,图像特征被输入到一个改进的双向循环网络中,它沿序列的两个方向读取信息。作者对其中一个内部门控和激活函数进行了重新设计以提高学习效果,并使用迁移学习使在一种设置中学到的知识能加速另一种设置的训练。最后,文本与图像分支的评分被平均合并,得到单一的情感判定。
将方法付诸检验
为评估方法效果,研究者在三类数据上进行测试:带有商家属性的餐厅照片、苹果设备的产品图像,以及一小批包含图片与文本的推特帖子。他们将混合系统与多种现代竞争方法比较,包括基于变换器的模型、多模态注意力网络和若干现有优化技术。在准确率、精确率与F值等指标上,他们的方法持续领先,且差距常明显。训练时它收敛更快,即便在加入人为噪声时也能保持良好表现,表明其既高效又鲁棒。
对日常技术的意义
简言之,这项工作表明,当计算机同时查看我们所说与所展示的内容时,能更好地感知我们在线上的情绪。通过细致清洗数据、设计更丰富的特征,以及将两套专门的神经引擎与智能优化策略结合,所提出的框架减少了情绪解读错误并提高了情感预测的可靠性。尽管当前系统侧重于文本与图像,但相同思路可扩展到语音语调或视频,为未来更自然理解人类情感并提供更及时、个性化的数字体验的工具铺路。
引用: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
关键词: 多模态情感分析, 社交媒体情绪, 图像与文本融合, 深度学习分类器, 特征优化