Clear Sky Science · sv
Multimodal sentimentsanalys: hybrid klassificeringsmodell med bild- och textfunktionsbeskrivare
Varför dina foton och inlägg spelar roll
Varje dag delar människor åsikter genom korta meddelanden, bilder på måltider, produktbilder och reaktionsbilder. Företag, forskare och appar vill alla veta: är stämningen bakom detta innehåll positiv eller negativ? Traditionell sentimentsanalys ser oftast bara på text och ignorerar vad som visas på bilden. Denna artikel presenterar ett nytt sätt att läsa känslor från både ord och bilder tillsammans, med målet att uppnå mer exakt och pålitlig sentimentdetektion i verkliga sociala och recensionsdata.
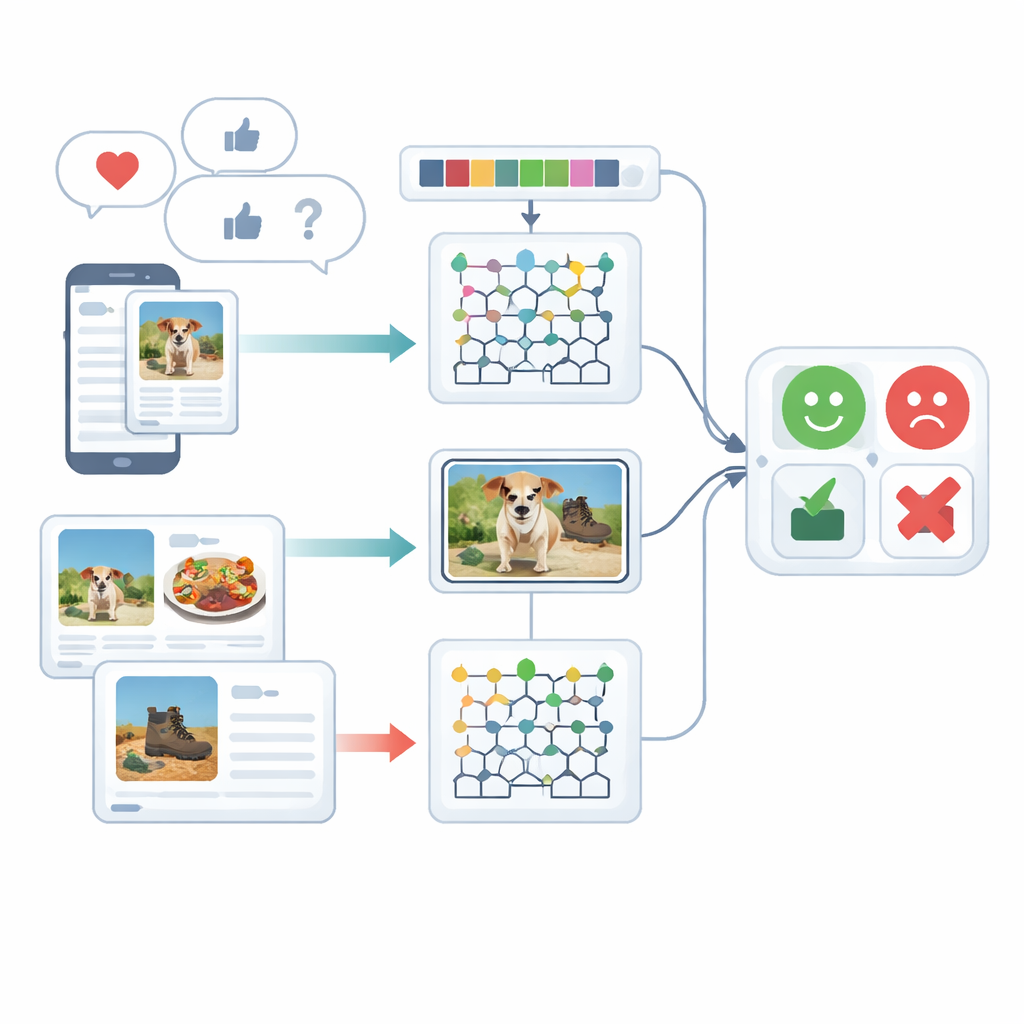
Att betrakta känslor ur flera vinklar
Studien fokuserar på multimodal sentimentsanalys, vilket innebär att förstå känslor genom mer än en typ av signal — i detta fall skriven text och bilder. Människor uttrycker sig sällan på bara ett sätt: en glad bildtext kan kombineras med ett dämpat foto, eller en ironisk mening kan mjukas upp av en lekfull emoji. Befintliga system har svårt att förena dessa olika ledtrådar och behandlar ofta text eller bilder separat. Författarna granskar tidigare arbete som bygger på rekurrenta neurala nätverk, transformermodeller eller enkla funktionskombinationer, och visar att dessa tillvägagångssätt ofta förbiser subtila kopplingar mellan vad som skrivs och vad som visas, eller kräver mycket kraftfulla träningsresurser.
Rensa upp röran innan man tolkar den
Innan någon åsikt kan klassificeras måste rådata städas. För text bryter systemet ner meningar i delar, tar bort vanliga stoppord som ”the” eller ”and” och reducerar ord till deras grundform så att liknande termer hanteras tillsammans. Det ägnas också särskild uppmärksamhet åt emojis, eftersom dessa små bilder bär starka emotionella signaler. För bilder använder ramverket en snabb objektdetekteringsmetod för att lokalisera huvudobjekten i ett foto — exempelvis mat på en tallrik eller en pryl på ett bord. Detta steg tar bort bakgrundsstörningar så att senare bearbetning kan fokusera på de delar av en bild som faktiskt är viktiga för att bedöma sentiment.
Lära modellen vad den ska uppmärksamma
Efter rensning omvandlar systemet både text och bilder till rika numeriska beskrivningar. På textsidan räknar det korta ordsekvenser (n-gram), spårar emoji-användning och använder en förbättrad version av den klassiska viktmetoden TF–IDF. Förbättringen säkerställer att känslomässigt viktiga ord, som kan förekomma ojämnt i olika dokumenttyper, framträder tydligare. På bildsidan fångar metoden två typer av visuella detaljer: färg- och texturmönster samt lokala former. Den förfinar en välkänd texturbeskrivare så att subtila skillnader i färg och kantorientering bevaras, och kombinerar detta med en teknik som komprimerat representerar former och texturer i ansikts- eller objektregioner. Tillsammans hjälper dessa funktioner systemet att skilja till exempel en mysig restaurangscen från en hårt belyst, oinbjudande miljö.
Blenda två smarta motorer till ett beslut
Kärnan i ramverket är en hybridmodell som bearbetar text och bilder med separata djuplärande-motorer och sedan sammanför deras bedömningar. Textfunktioner skickas till ett Deep Maxout-nätverk, en typ av neuralt modell som lär sig flexibla beslutgränser; dess interna inställningar justeras av en specialanpassad optimeringsprocedur inspirerad av belugavalars jakt- och rörelsemönster. Denna optimizer söker effektivt efter kombinationen av vikter som minimerar klassificeringsfel. Parallellt matas bildfunktioner in i ett modifierat bidirektionellt rekurrent nätverk som läser information i båda riktningarna längs en sekvens. Författarna omdesignar en av dess interna grindar och dess aktiveringsfunktion för att lära mer effektivt, och de använder transferinlärning så att kunskap inhämtad i ett sammanhang kan påskynda träningen i ett annat. Slutligen medelvärdesbildas poängen från text- och bildgrenarna för att ge ett enda sentimentbeslut.
Sätta metoden på prov
För att se hur väl deras metod fungerar testar forskarna den på tre typer av data: restaurangbilder med associerade företagsattribut, produktbilder av Apple-enheter och en liten samling Twitter-inlägg som innehåller både bilder och text. De jämför sitt hybrida system med en rad moderna konkurrenter, inklusive transformerbaserade modeller, multimodala attention-nätverk och flera befintliga optimeringstekniker. Över mått som noggrannhet, precision och F-mått kommer deras tillvägagångssätt konsekvent bättre ut, ofta med en tydlig marginal. Det konvergerar också snabbare under träning och behåller god prestanda även när artificiellt brus tillförs, vilket tyder på att det både är effektivt och robust.
Vad detta innebär för vardagsteknik
Kort sagt visar detta arbete att datorer bättre kan uppfatta våra känslor online när de tittar på vad vi säger och vad vi visar samtidigt. Genom att noggrant rensa data, designa rikare funktioner och kombinera två specialiserade neurala motorer med en smart optimeringsstrategi minskar det föreslagna ramverket feltolkningar av stämning och förbättrar tillförlitligheten i sentimentsförutsägelser. Medan det nuvarande systemet fokuserar på text och bilder kan samma idéer utvidgas till att omfatta röstton eller video, vilket banar väg för framtida verktyg som förstår mänskliga känslor mer naturligt och stödjer mer lyhörda, personliga digitala upplevelser.
Citering: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
Nyckelord: multimodal sentimentsanalys, känslor på sociala medier, förening av bild och text, djuplärandeklassificerare, funktionsoptimering