Clear Sky Science · pt
Análise multimodal de sentimento: modelo híbrido de classificação com descritores de recursos de imagem e texto
Por que suas fotos e publicações importam
Todo dia, pessoas compartilham opiniões por meio de mensagens curtas, fotos de refeições, imagens de produtos e imagens de reação. Empresas, pesquisadores e aplicativos querem saber: o tom por trás desse conteúdo é positivo ou negativo? A análise de sentimento tradicional costuma olhar só para o texto, ignorando o que aparece na imagem. Este artigo apresenta uma nova forma de ler emoções a partir de palavras e imagens juntas, visando uma detecção de sentimento mais precisa e confiável em dados reais de redes sociais e avaliações.
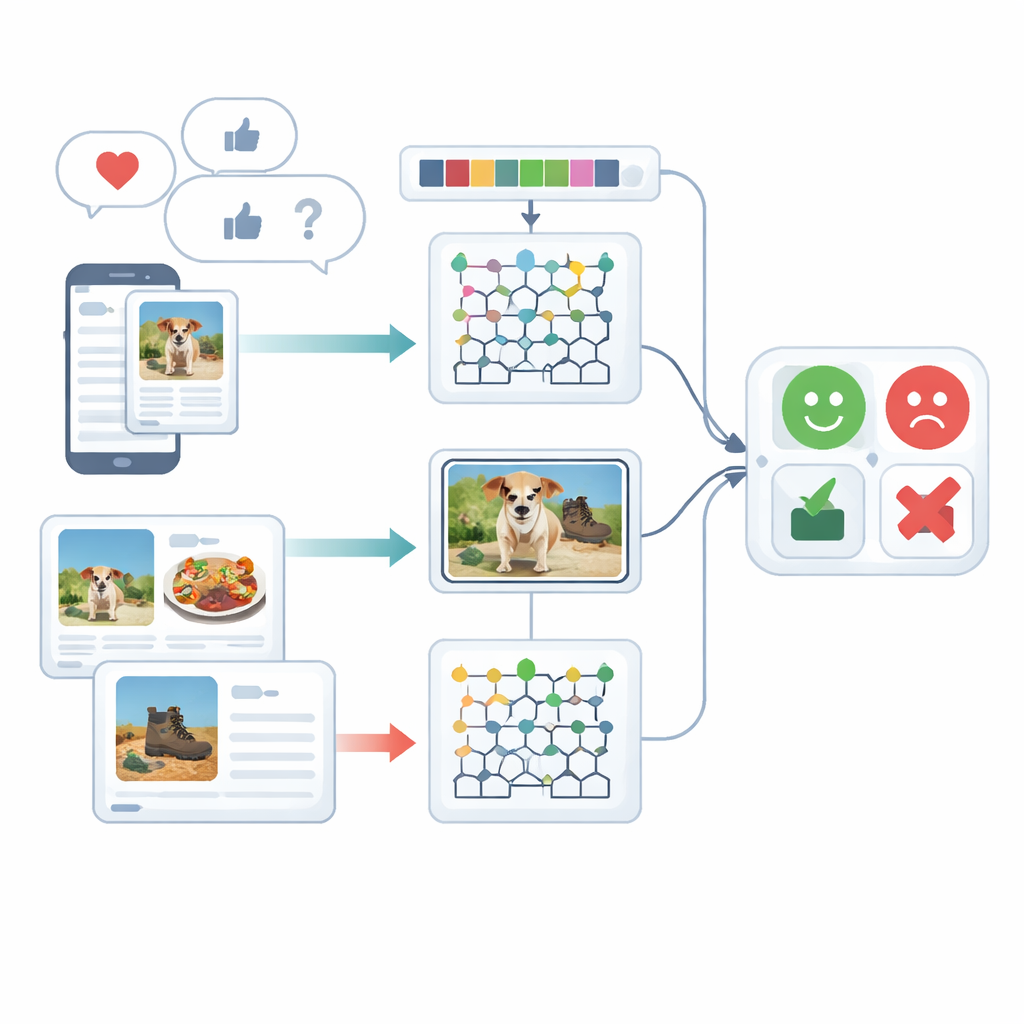
Olhando para os sentimentos por vários ângulos
O estudo se concentra em análise multimodal de sentimento, isto é, entender emoções usando mais de um tipo de sinal — neste caso, texto escrito e imagens. Pessoas raramente se expressam de apenas um modo: uma legenda alegre pode acompanhar uma foto sombria, ou uma frase sarcástica pode ser suavizada por um emoji brincalhão. Sistemas existentes têm dificuldade em fundir essas pistas diferentes e frequentemente tratam texto e imagens separadamente. Os autores revisam trabalhos anteriores que usam redes neurais recorrentes, transformers ou combinações simples de recursos, e mostram que essas abordagens muitas vezes deixam passar conexões sutis entre o que é escrito e o que é mostrado, ou exigem recursos de treinamento muito pesados.
Limpar a bagunça antes de entender
Antes que qualquer opinião possa ser classificada, os dados brutos precisam ser organizados. Para o texto, o sistema quebra sentenças em partes, remove palavras de preenchimento comuns como “o” ou “e”, e reduz palavras à sua forma básica para que termos semelhantes sejam tratados em conjunto. Também dá atenção especial a emojis, já que essas pequenas imagens carregam fortes pistas emocionais. Para imagens, o framework usa um método rápido de detecção de objetos para localizar os itens principais numa foto — como comida num prato ou um aparelho sobre uma mesa. Essa etapa remove distrações de fundo para que o processamento posterior possa focar nas partes da imagem que realmente importam para avaliar o sentimento.
Ensinar ao modelo o que observar
Depois da limpeza, o sistema converte texto e imagens em descrições numéricas ricas. No lado do texto, conta sequências curtas de palavras (N-grams), rastreia o uso de emojis e usa uma versão aprimorada de um método clássico de ponderação chamado TF–IDF. A melhoria garante que palavras emocionalmente importantes, que podem aparecer de forma desigual entre tipos diferentes de documentos, se destaquem com mais clareza. No lado da imagem, o método captura dois tipos de detalhe visual: padrões de cor e textura e formas locais. Ele refina um descritor de textura conhecido para que diferenças sutis em cor e orientação de borda sejam preservadas, e combina isso com uma técnica que representa de forma compacta as formas e texturas de regiões faciais ou de objetos. Juntos, esses recursos ajudam o sistema a distinguir, por exemplo, uma cena de restaurante acolhedora de uma cena com iluminação dura e pouco convidativa.
Combinando dois motores inteligentes numa única decisão
O coração do framework é um modelo híbrido que processa texto e imagens com motores de aprendizado profundo separados e então reúne seus julgamentos. Recursos de texto são enviados a uma rede Deep Maxout, um tipo de modelo neural que aprende limites de decisão flexíveis; seus parâmetros internos são ajustados por um procedimento de otimização personalizado inspirado nos padrões de caça e movimento das baleias beluga. Esse otimizador busca de forma eficiente a combinação de pesos que minimiza os erros de classificação. Em paralelo, os recursos de imagem são alimentados a uma rede recorrente bidirecional modificada que lê informação em ambas as direções ao longo de uma sequência. Os autores redesenham um de seus portões internos e sua função de ativação para aprender com mais eficácia, e usam aprendizado por transferência para que conhecimento obtido em um cenário acelere o treinamento em outro. Por fim, as pontuações dos ramos de texto e imagem são combinadas por média para gerar uma única decisão de sentimento.
Testando a abordagem
Para avaliar o desempenho do método, os pesquisadores testam-no em três tipos de dados: fotos de restaurantes com características comerciais associadas, imagens de produtos de dispositivos Apple e uma pequena coleção de publicações do Twitter contendo tanto imagens quanto texto. Eles comparam seu sistema híbrido com uma gama de concorrentes modernos, incluindo modelos baseados em transformers, redes de atenção multimodal e várias técnicas de otimização existentes. Em medidas como acurácia, precisão e F-measure, sua abordagem aparece consistentemente na frente, muitas vezes com margem clara. Também converge mais rápido durante o treinamento e mantém bom desempenho mesmo quando ruído artificial é adicionado, sugerindo que é eficiente e robusta.
O que isso significa para a tecnologia do dia a dia
Em termos práticos, este trabalho mostra que computadores podem perceber melhor nossas emoções online quando observam simultaneamente o que dizemos e o que mostramos. Ao limpar cuidadosamente os dados, projetar recursos mais ricos e combinar dois motores neurais especializados com uma estratégia de otimização inteligente, o framework proposto reduz leituras equivocadas de humor e melhora a confiabilidade das previsões de sentimento. Embora o sistema atual se concentre em texto e imagens, as mesmas ideias podem ser estendidas para incluir tom de voz ou vídeo, abrindo caminho para ferramentas futuras que compreendam emoções humanas de forma mais natural e apoiem experiências digitais mais responsivas e personalizadas.
Citação: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
Palavras-chave: análise multimodal de sentimento, emoções em redes sociais, fusão de imagem e texto, classificador de aprendizado profundo, otimização de recursos