Clear Sky Science · tr
Multimodal duygu analizi: görüntü ve metin özellik tanımlayıcılarıyla hibrit sınıflandırma modeli
Fotoğraflarınız ve gönderileriniz neden önemli
Her gün insanlar kısa mesajlar, yemek fotoğrafları, ürün çekimleri ve tepki görselleri paylaşır. Şirketler, araştırmacılar ve uygulamalar şu soruyu sormak ister: bu içeriğin arkasındaki ruh hali olumlu mu yoksa olumsuz mu? Geleneksel duygu analizi çoğunlukla yalnızca metne bakar ve resimde gösterilene kayıtsız kalır. Bu makale, gerçek dünyadaki sosyal ve değerlendirme verilerinde daha doğru ve güvenilir duygu tespiti hedefiyle hem kelimelerden hem de görüntülerden duyguları birlikte okumaya yönelik yeni bir yöntem sunuyor.
Duygulara birçok açıdan bakmak
Çalışma, yazılı metin ve görüntü olmak üzere birden fazla sinyali kullanarak duyguları anlamayı amaçlayan multimodal duygu analizine odaklanıyor. İnsanlar nadiren yalnızca tek bir yolla kendilerini ifade eder: neşeli bir başlık kasvetli bir fotoğrafla eşleşebilir veya alaycı bir cümle eğlenceli bir emoji ile yumuşatılabilir. Mevcut sistemler bu farklı ipuçlarını birleştirmekte zorlanıyor ve sıklıkla metin veya görüntüleri ayrı ayrı ele alıyor. Yazarlar, tekrarlayan sinir ağlarına, transformer’lara veya basit özellik kombinasyonlarına dayanan önceki çalışmaları gözden geçiriyor ve bu yaklaşımların yazılan ile gösterilen arasındaki ince bağlantıları sıklıkla göz ardı ettiğini veya çok yoğun eğitim kaynakları gerektirdiğini gösteriyor.
Anlam çıkarmadan önce dağınıklığı temizlemek
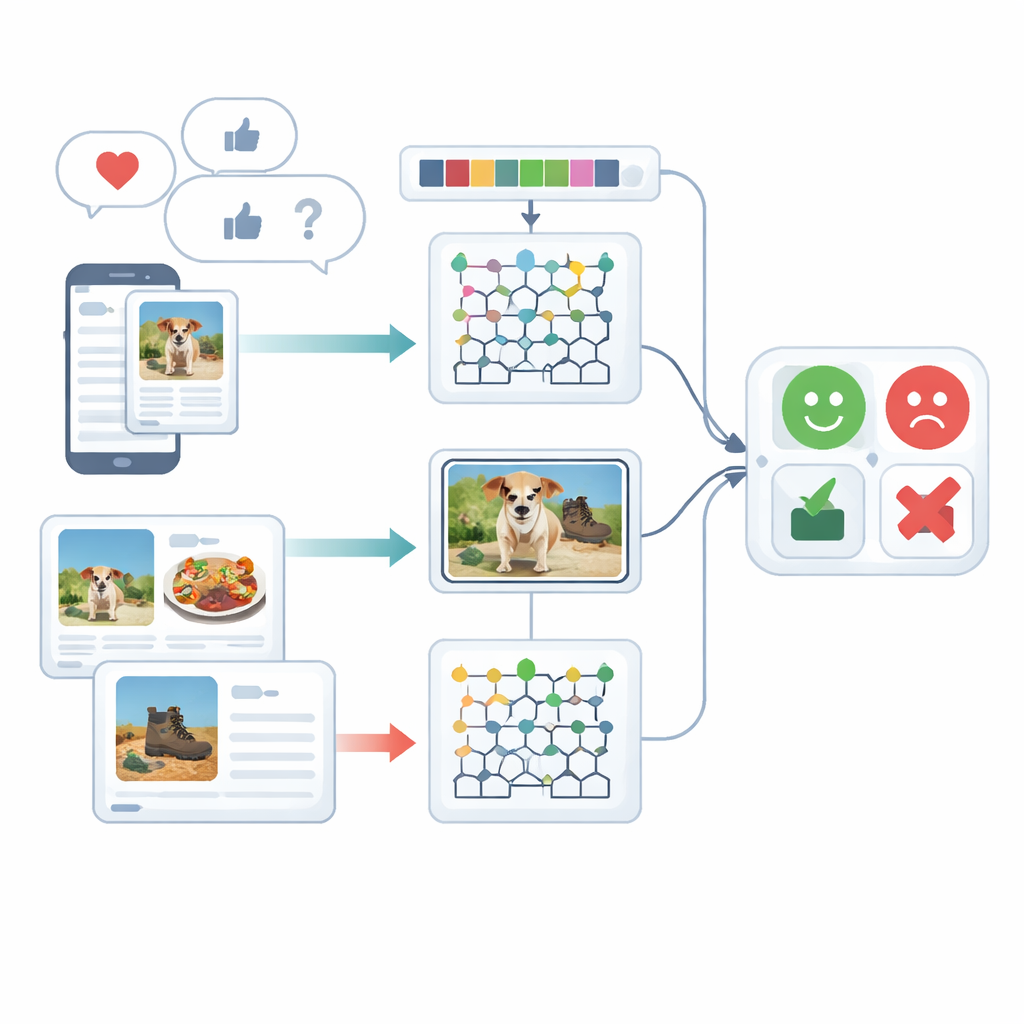
Herhangi bir görüş sınıflandırılmadan önce ham verilerin temizlenmesi gerekir. Metin için sistem cümleleri parçalara ayırır, “the” veya “and” gibi yaygın gereksiz kelimeleri kaldırır ve benzer terimlerin birlikte işlenmesi için kelimeleri köklerine indirger. Ayrıca bu küçük görsellerin güçlü duygusal ipuçları taşıması nedeniyle emojilere özel önem verir. Görüntüler için çerçeve, bir fotoğraftaki ana nesneleri—örneğin tabaktaki yemek veya masadaki bir cihaz—bulmak üzere hızlı bir nesne algılama yöntemi kullanır. Bu adım, arka plan dikkat dağıtıcı unsurlarını temizleyerek sonraki işlemenin duygu değerlendirmesi için gerçekten önemli olan görüntü parçalarına odaklanmasına olanak tanır.
Modele neye dikkat edeceğini öğretmek
Temizlemeden sonra sistem hem metin hem de görüntüleri zengin sayısal tanımlamalara dönüştürür. Metin tarafında kısa sözcük dizilerini (N-gram) sayar, emoji kullanımını izler ve klasik bir ağırlıklandırma yöntemi olan TF–IDF’nin geliştirilmiş bir sürümünü kullanır. Bu iyileştirme, farklı belge türleri arasında dengesiz görünebilecek duygusal olarak önemli kelimelerin daha net öne çıkmasını sağlar. Görüntü tarafında yöntem iki tür görsel ayrıntıyı yakalar: renk ve doku desenleri ile yerel şekiller. Bilinen bir doku tanımlayıcıyı renk ve kenar yönelimi gibi ince farkları koruyacak şekilde incelikle geliştirir ve bunu yüz veya nesne bölgelerinin şekil ve dokusunu kompakt biçimde temsil eden bir teknikle birleştirir. Birlikte bu özellikler, örneğin samimi bir restoran sahnesi ile sert ışıklandırılmış, itici bir mekanı ayırt etmeye yardımcı olur.
İki akıllı motoru tek bir kararda harmanlamak
Çerçevenin çekirdeği, metin ve görüntüleri ayrı derin öğrenme motorlarıyla işleyen ve ardından yargılarını birleştiren hibrit bir modeldir. Metin özellikleri, esnek karar sınırları öğrenen bir sinir modeli türü olan Deep Maxout ağına gönderilir; bu ağın iç ayarları beyaz balinaların avlanma ve hareket desenlerinden esinlenen özel bir optimizasyon yöntemiyle ayarlanır. Bu optimize edici, sınıflandırma hatalarını en aza indiren ağırlık kombinasyonunu verimli şekilde arar. Paralel olarak, görüntü özellikleri bir dizide her iki yönde de bilgi okuyan değiştirilmiş bir çift yönlü tekrarlayan ağa verilir. Yazarlar, iç kapılarından birini ve aktivasyon fonksiyonunu daha etkili öğrenmesi için yeniden tasarlar ve transfer öğrenimi kullanarak bir ortamda öğrenilen bilginin başka bir ortamda eğitimi hızlandırmasını sağlar. Son olarak, metin ve görüntü kollarından gelen puanlar ortalanarak tek bir duygu kararı oluşturulur.
Yaklaşımı teste sokmak
Yöntemlerinin ne kadar iyi çalıştığını görmek için araştırmacılar bunu üç tür veri üzerinde test eder: ilgili işletme özellikleriyle eşleştirilmiş restoran fotoğrafları, Apple cihazlarının ürün görüntüleri ve hem resim hem metin içeren küçük bir Twitter gönderileri koleksiyonu. Hibrit sistemlerini transformer tabanlı modeller, multimodal dikkat ağları ve birkaç mevcut optimizasyon tekniği de dahil olmak üzere modern rakiplerle karşılaştırırlar. Doğruluk, kesinlik ve F-ölçer gibi ölçülerde yaklaşımları genellikle açık bir farkla öne çıkar. Ayrıca eğitim sırasında daha hızlı yakınsar ve yapay gürültü eklendiğinde bile iyi performansı koruyarak hem verimli hem de dayanıklı olduğunu gösterir.
Günlük teknoloji için bunun anlamı
Basitçe söylemek gerekirse, bu çalışma bilgisayarların çevrimiçi duygularımızı hem söylediğimize hem de gösterdiğimize birlikte bakarak daha iyi sezebileceğini gösterir. Verileri dikkatle temizleyerek, daha zengin özellikler tasarlayarak ve iki uzmanlaşmış sinir motorunu akıllı bir optimizasyon stratejisiyle birleştirerek önerilen çerçeve yanlış anlamaları azaltır ve duygu tahminlerinin güvenilirliğini artırır. Mevcut sistem metin ve görüntüye odaklansa da aynı fikirler ses tonu veya video gibi ek modaliteleri de kapsayacak şekilde genişletilebilir; bu da insan duygularını daha doğal anlayan ve daha duyarlı, kişiselleştirilmiş dijital deneyimleri destekleyen geleceğin araçlarının yolunu açar.
Atıf: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
Anahtar kelimeler: multimodal duygu analizi, sosyal medya duyguları, görüntü ve metin füzyonu, derin öğrenme sınıflandırıcısı, özellik optimizasyonu