Clear Sky Science · it
Analisi del sentimento multimodale: modello di classificazione ibrido con descrittori di caratteristiche per immagini e testo
Perché contano le tue foto e i tuoi post
Ogni giorno le persone condividono opinioni tramite brevi messaggi, foto di piatti, immagini di prodotti e immagini di reazione. Aziende, ricercatori e applicazioni vogliono sapere: qual è il tono emotivo di questi contenuti, positivo o negativo? L’analisi del sentimento tradizionale si concentra soprattutto sul testo, ignorando ciò che viene mostrato nell’immagine. Questo articolo presenta un nuovo modo di leggere le emozioni combinando parole e immagini, con l’obiettivo di ottenere una rilevazione del sentimento più accurata e affidabile su dati reali di social e recensioni.
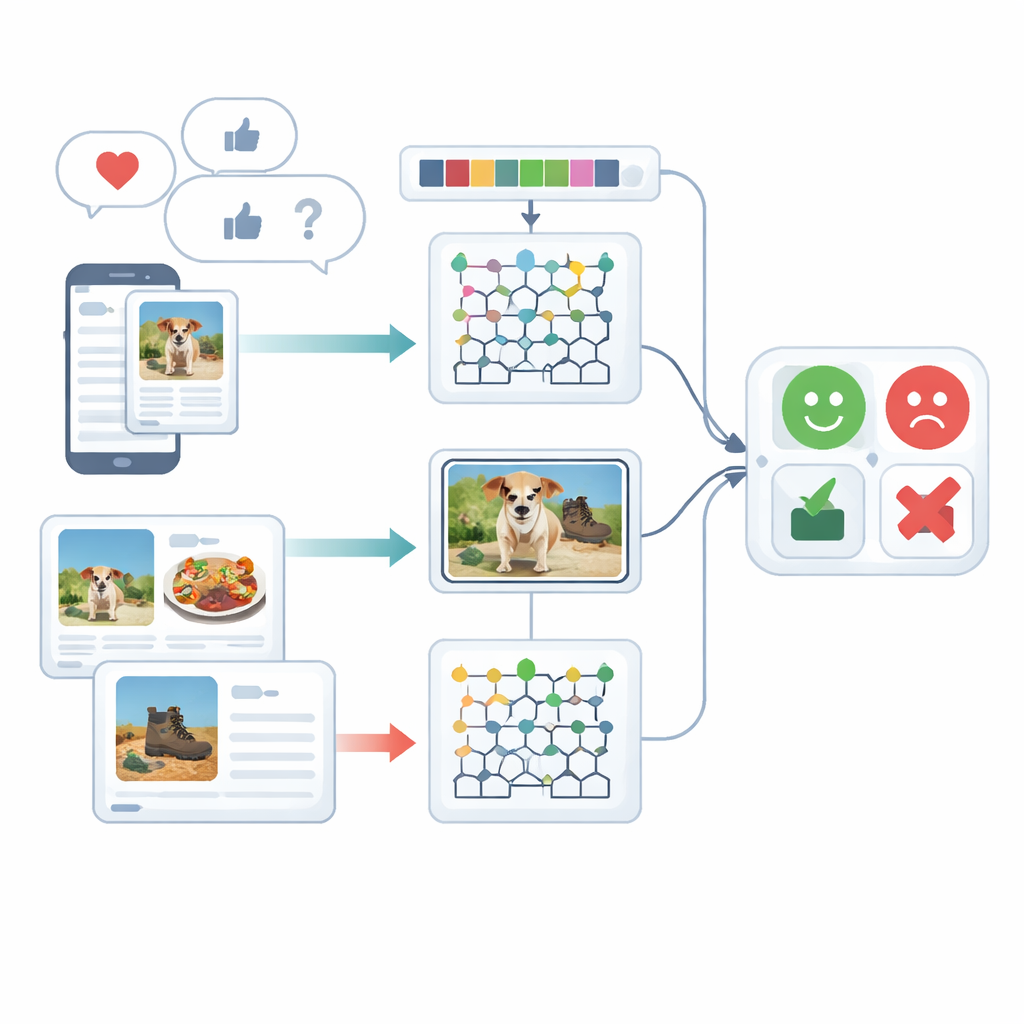
Osservare i sentimenti da più angolazioni
Lo studio si concentra sull’analisi del sentimento multimodale, cioè sulla comprensione delle emozioni usando più tipi di segnali — in questo caso testo scritto e immagini. Le persone raramente si esprimono in un solo modo: una didascalia allegra può accompagnare una foto cupa, o una frase sarcastica può essere attenuata da un’emoji giocosa. I sistemi esistenti faticano a fondere questi indizi diversi e spesso trattano testo e immagini separatamente. Gli autori rivedono lavori precedenti basati su reti ricorrenti, transformer o semplici combinazioni di caratteristiche, mostrando che tali approcci spesso trascurano i legami sottili tra ciò che è scritto e ciò che è mostrato, oppure richiedono risorse di addestramento molto pesanti.
Mettere ordine prima di interpretare
Prima di poter classificare un’opinione, i dati grezzi devono essere ripuliti. Per il testo, il sistema spezza le frasi in parti, rimuove parole di riempimento comuni come “il” o “e” e riduce le parole alla loro forma base in modo che termini simili siano trattati insieme. Presta anche particolare attenzione alle emoji, poiché queste piccole immagini veicolano forti indizi emotivi. Per le immagini, il framework utilizza un metodo rapido di rilevamento degli oggetti per individuare gli elementi principali in una foto — come cibo su un piatto o un dispositivo su un tavolo. Questo passaggio elimina le distrazioni di sfondo in modo che l’elaborazione successiva possa concentrarsi sulle parti dell’immagine che contano davvero per giudicare il sentimento.
Insegnare al modello cosa notare
Dopo la pulizia, il sistema trasforma sia il testo sia le immagini in descrizioni numeriche ricche. Sul fronte testuale conta brevi sequenze di parole (N-grammi), monitora l’uso delle emoji e utilizza una versione migliorata di un metodo classico di pesatura chiamato TF–IDF. Il miglioramento garantisce che le parole emotivamente rilevanti, che possono apparire in modo non uniforme tra diversi tipi di documenti, risaltino più chiaramente. Sul fronte delle immagini, il metodo cattura due tipi di dettaglio visivo: pattern di colore e texture e forme locali. Affina un noto descrittore di texture in modo da preservare differenze sottili di colore e orientamento dei bordi, e combina questo con una tecnica che rappresenta in modo compatto le forme e le texture di regioni facciali o oggettuali. Insieme, queste caratteristiche aiutano il sistema a distinguere, per esempio, una scena di ristorante accogliente da una illuminata in modo crudo e poco invitante.
Fondere due motori intelligenti in una sola decisione
Il cuore del framework è un modello ibrido che elabora testo e immagini con motori deep-learning separati e poi fonde i loro giudizi. Le caratteristiche testuali sono inviate a una rete Deep Maxout, un tipo di modello neurale che apprende confini decisionali flessibili; i suoi parametri interni sono ottimizzati da una procedura personalizzata ispirata ai modelli di caccia e movimento delle belughe. Questo ottimizzatore cerca in modo efficiente la combinazione di pesi che minimizza gli errori di classificazione. In parallelo, le caratteristiche delle immagini vengono alimentate in una rete ricorrente bidirezionale modificata che legge le informazioni in entrambe le direzioni lungo una sequenza. Gli autori ridisegnano una delle sue porte interne e la sua funzione di attivazione per apprendere in modo più efficace, e utilizzano il transfer learning in modo che la conoscenza acquisita in un contesto possa accelerare l’addestramento in un altro. Infine, i punteggi dei rami testuale e visivo vengono mediati per produrre una singola decisione sul sentimento.
Mettere alla prova l’approccio
Per valutare le prestazioni del metodo, i ricercatori lo testano su tre tipi di dati: foto di ristoranti con caratteristiche aziendali associate, immagini di prodotti di dispositivi Apple e una piccola raccolta di post Twitter contenenti sia immagini sia testo. Confrontano il loro sistema ibrido con una serie di concorrenti moderni, inclusi modelli basati su transformer, reti di attenzione multimodale e diverse tecniche di ottimizzazione esistenti. Su misure come accuratezza, precisione e F-measure, il loro approccio risulta costantemente in testa, spesso con un margine netto. Converge anche più rapidamente durante l’addestramento e mantiene buone prestazioni anche quando viene aggiunto rumore artificiale, suggerendo che è sia efficiente sia robusto.
Cosa significa per la tecnologia di tutti i giorni
In termini semplici, questo lavoro mostra che i computer possono cogliere meglio le nostre sensazioni online quando osservano contemporaneamente ciò che diciamo e ciò che mostriamo. Ripulendo con cura i dati, progettando caratteristiche più ricche e combinando due motori neurali specializzati con una strategia di ottimizzazione intelligente, il framework proposto riduce le interpretazioni errate dell’umore e migliora l’affidabilità delle previsioni del sentimento. Sebbene il sistema attuale si concentri su testo e immagini, le stesse idee potrebbero essere estese per includere il tono della voce o il video, aprendo la strada a strumenti futuri che comprendono le emozioni umane in modo più naturale e supportano esperienze digitali più reattive e personalizzate.
Citazione: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
Parole chiave: analisi del sentimento multimodale, emozioni sui social media, fusione immagine e testo, classificatore deep learning, ottimizzazione delle caratteristiche