Clear Sky Science · en
Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors
Why your photos and posts matter
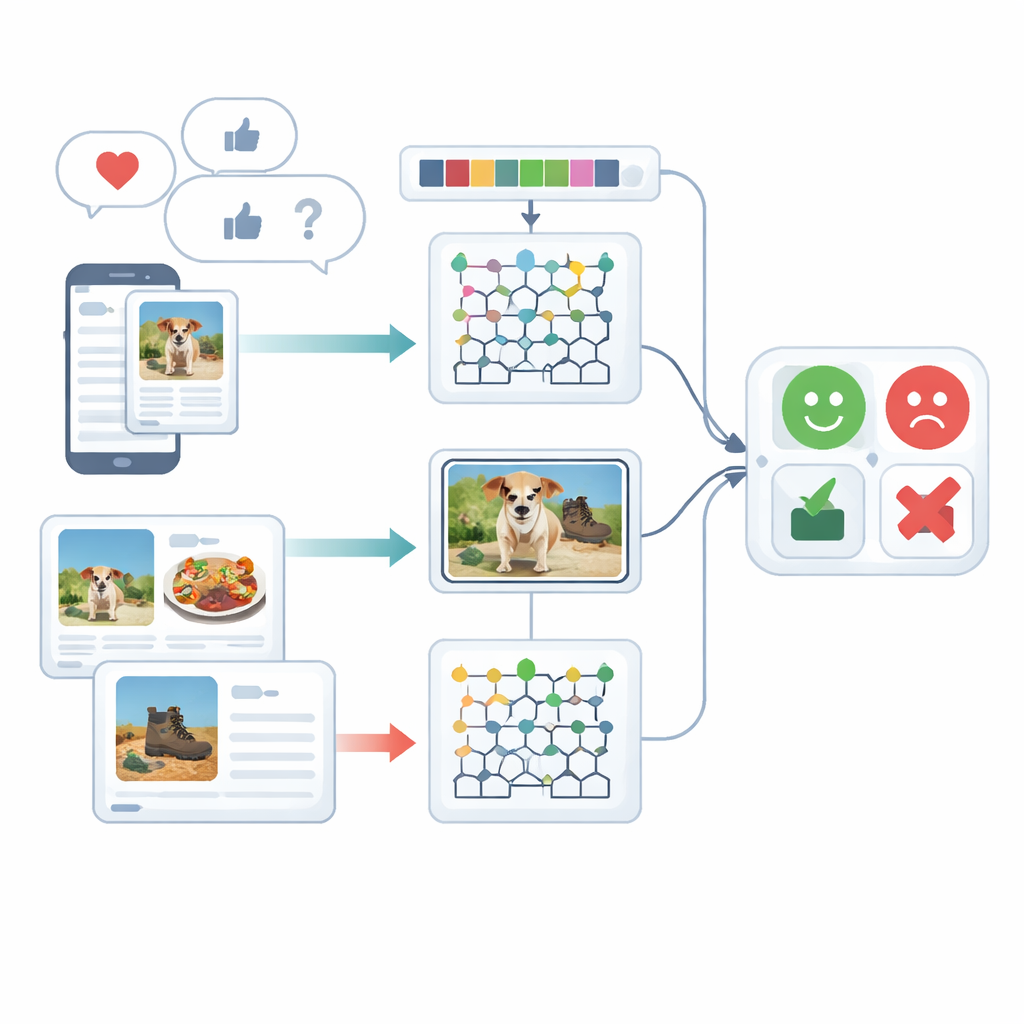
Every day, people share opinions through short messages, photos of meals, product shots, and reaction images. Companies, researchers, and apps all want to know: is the mood behind this content positive or negative? Traditional sentiment analysis mostly looks at text alone, ignoring what is shown in the picture. This paper presents a new way to read emotions from both words and images together, aiming for more accurate and reliable sentiment detection on real-world social and review data.
Looking at feelings from many angles
The study focuses on multimodal sentiment analysis, which means understanding emotions using more than one type of signal—in this case, written text and images. People rarely express themselves in just one way: a cheerful caption can be paired with a gloomy photo, or a sarcastic sentence might be softened by a playful emoji. Existing systems struggle to fuse these different clues and often treat text or images separately. The authors review past work that relies on recurrent neural networks, transformers, or simple feature combinations, and show that these approaches often overlook subtle links between what is written and what is shown, or require very heavy training resources.
Cleaning up the mess before making sense of it
Before any opinion can be classified, the raw data needs to be tidied. For text, the system breaks sentences into pieces, removes common filler words like “the” or “and,” and reduces words to their basic form so that similar terms are handled together. It also pays special attention to emojis, since these tiny images carry strong emotional cues. For images, the framework uses a fast object-detection method to locate the main items in a photo—such as food on a plate or a gadget on a table. This step removes background distraction so that later processing can focus on the parts of an image that actually matter for judging sentiment.
Teaching the model what to notice
After cleaning, the system turns both text and images into rich numerical descriptions. On the text side, it counts short word sequences (N-grams), tracks emoji usage, and uses an improved version of a classic weighting method called TF–IDF. The improvement makes sure that emotionally important words, which may appear unevenly across different types of documents, stand out more clearly. On the image side, the method captures two kinds of visual detail: color-and-texture patterns and local shapes. It refines a known texture descriptor so that subtle differences in color and edge orientation are preserved, and combines this with a technique that represents the shapes and textures of facial or object regions in a compact way. Together, these features help the system distinguish, for example, a cozy restaurant scene from a harshly lit, uninviting one.
Blending two smart engines into one decision
The heart of the framework is a hybrid model that processes text and images with separate deep-learning engines and then merges their judgments. Text features are sent to a Deep Maxout network, a type of neural model that learns flexible decision boundaries; its internal settings are tuned by a custom optimization procedure inspired by the hunting and movement patterns of beluga whales. This optimizer searches efficiently for the combination of weights that minimizes classification errors. In parallel, image features are fed into a modified bidirectional recurrent network that reads information in both directions along a sequence. The authors redesign one of its internal gates and its activation function to learn more effectively, and they use transfer learning so that knowledge learned in one setting can speed up training in another. Finally, the scores from the text and image branches are averaged to yield a single sentiment decision.
Putting the approach to the test
To see how well their method works, the researchers test it on three types of data: restaurant photos with associated business traits, product images of Apple devices, and a small collection of Twitter posts containing both pictures and text. They compare their hybrid system against a range of modern competitors, including transformer-based models, multimodal attention networks, and several existing optimization techniques. Across measures such as accuracy, precision, and F-measure, their approach consistently comes out ahead, often by a clear margin. It also converges faster during training and maintains good performance even when artificial noise is added, suggesting that it is both efficient and robust.
What this means for everyday technology
In plain terms, this work shows that computers can better sense our feelings online when they look at what we say and what we show at the same time. By carefully cleaning the data, designing richer features, and combining two specialized neural engines with a smart optimization strategy, the proposed framework reduces misread moods and improves the reliability of sentiment predictions. While the current system focuses on text and images, the same ideas could be extended to include voice tone or video, paving the way for future tools that understand human emotions more naturally and support more responsive, personalized digital experiences.
Citation: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
Keywords: multimodal sentiment analysis, social media emotions, image and text fusion, deep learning classifier, feature optimization