Clear Sky Science · nl
Multimodale sentimentanalyse: hybride classificatiemodel met beeld- en tekstkenmerken
Waarom je foto’s en berichten ertoe doen
Dagelijks delen mensen meningen via korte berichten, foto’s van maaltijden, productfoto’s en reactieafbeeldingen. Bedrijven, onderzoekers en apps willen allemaal weten: is de stemming achter deze inhoud positief of negatief? Traditionele sentimentanalyse kijkt vooral naar tekst en negeert wat op de foto te zien is. Dit artikel presenteert een nieuwe manier om emoties tegelijk uit woorden en beelden te lezen, met als doel accuratere en betrouwbaardere sentimentdetectie op echte sociale en beoordelingsdata.
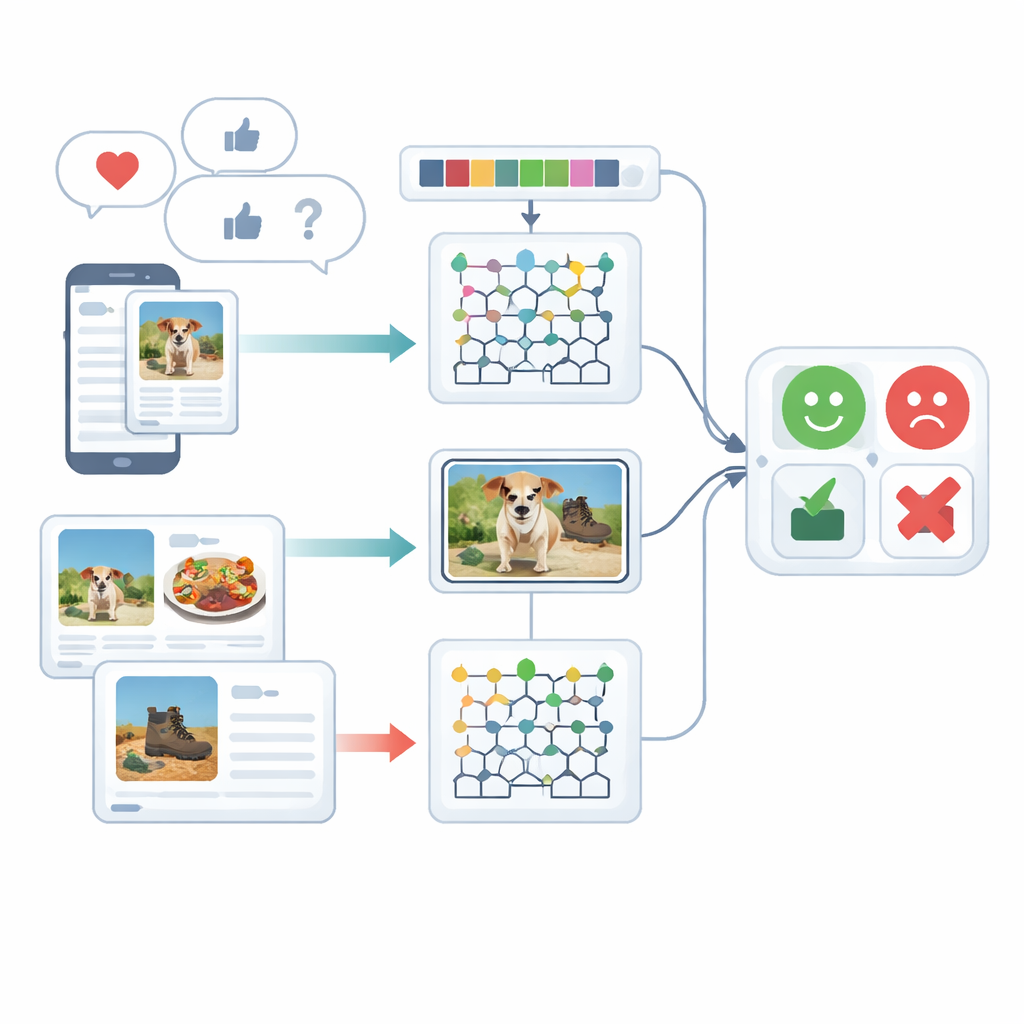
Gevoelens vanuit meerdere hoeken bekijken
De studie richt zich op multimodale sentimentanalyse, wat betekent dat emoties worden begrepen met meer dan één type signaal—in dit geval geschreven tekst en afbeeldingen. Mensen uiten zichzelf zelden op één manier: een opgewekte onderschrift kan gekoppeld zijn aan een sombere foto, of een sarcastische zin kan worden verzacht door een speelse emoji. Bestaande systemen hebben moeite om deze verschillende aanwijzingen te combineren en behandelen tekst of afbeeldingen vaak apart. De auteurs bespreken eerder werk dat vertrouwt op recurrente neurale netwerken, transformers of eenvoudige feature-combinaties, en tonen aan dat deze benaderingen subtiele verbanden tussen wat geschreven is en wat getoond wordt vaak over het hoofd zien of zeer zware trainingsmiddelen vereisen.
Opruimen voordat je het gaat begrijpen
Voordat een mening geclassificeerd kan worden, moeten de ruwe gegevens worden opgeschoond. Voor tekst breekt het systeem zinnen op, verwijdert het veelvoorkomende stopwoorden zoals “de” of “en”, en reduceert het woorden tot hun basisvorm zodat soortgelijke termen samen worden behandeld. Er wordt ook speciale aandacht besteed aan emoji’s, omdat deze kleine afbeeldingen sterke emotionele aanwijzingen bevatten. Voor afbeeldingen gebruikt het raamwerk een snelle objectdetectiemethode om de belangrijkste objecten in een foto te lokaliseren—zoals eten op een bord of een apparaat op een tafel. Deze stap verwijdert achtergrondafleiding zodat latere verwerking zich kan richten op de delen van een afbeelding die werkelijk van belang zijn voor het beoordelen van sentiment.
Het model leren waar het op moet letten
Na het opschonen zet het systeem zowel tekst als afbeeldingen om in rijke numerieke beschrijvingen. Aan de tekstkant telt het korte woordketens (n-grammen), houdt het emoji-gebruik bij en gebruikt het een verbeterde versie van een klassieke weegmethode genaamd TF–IDF. De verbetering zorgt ervoor dat emotioneel belangrijke woorden, die ongelijk verdeeld kunnen voorkomen over verschillende soorten documenten, duidelijker opvallen. Aan de beeldkant legt de methode twee soorten visuele details vast: kleur- en textuurpatronen en lokale vormen. Het verfijnt een bekende textuurbeschrijver zodat subtiele verschillen in kleur en randoriëntatie behouden blijven, en combineert dit met een techniek die de vormen en texturen van gezichts- of objectregio’s compact weergeeft. Samen helpen deze kenmerken het systeem bijvoorbeeld een gezellige restaurantscène te onderscheiden van een fel verlicht, onaantrekkelijk tafereel.
Twee slimme motoren in één beslissing samenvoegen
Het hart van het raamwerk is een hybride model dat tekst en afbeeldingen verwerkt met afzonderlijke deep-learning-engines en daarna hun oordelen samenvoegt. Tekstkenmerken worden naar een Deep Maxout-netwerk gestuurd, een type neuronale model dat flexibele beslissingsgrenzen leert; zijn interne instellingen worden afgestemd door een aangepaste optimalisatieprocedure geïnspireerd door de jacht- en bewegingspatronen van beluga’s. Deze optimizer zoekt efficiënt naar de combinatie van gewichten die classificatiefouten minimaliseert. Parallel daaraan worden beeldkenmerken ingevoerd in een aangepaste bidirectionele recurrente netwerk dat informatie in beide richtingen langs een sequentie leest. De auteurs herontwerpen één van zijn interne poorten en de activatiefunctie om effectiever te leren, en ze gebruiken transfer learning zodat kennis die in de ene setting is opgedaan, de training in een andere kan versnellen. Ten slotte worden de scores van de tekst- en beeldtak gemiddeld om tot één sentimentbeslissing te komen.
De aanpak op de proef stellen
Om te beoordelen hoe goed hun methode werkt, testen de onderzoekers deze op drie typen data: restaurantfoto’s met bijbehorende bedrijfskenmerken, productafbeeldingen van Apple-apparaten, en een kleine verzameling Twitter-berichten die zowel afbeeldingen als tekst bevatten. Ze vergelijken hun hybride systeem met een reeks moderne concurrenten, waaronder op transformers gebaseerde modellen, multimodale attentienetwerken en verschillende bestaande optimalisatietechnieken. Over maatstaven zoals nauwkeurigheid, precisie en F-measure komt hun aanpak consequent als beste uit de bus, vaak met een duidelijke marge. Het convergeert ook sneller tijdens training en behoudt goede prestaties zelfs wanneer kunstmatige ruis wordt toegevoegd, wat suggereert dat het zowel efficiënt als robuust is.
Wat dit betekent voor alledaagse technologie
In eenvoudige bewoordingen laat dit werk zien dat computers onze online gevoelens beter kunnen aanvoelen wanneer ze tegelijk kijken naar wat we zeggen en wat we tonen. Door zorgvuldig de data schoon te maken, rijkere kenmerken te ontwerpen en twee gespecialiseerde neurale motoren te combineren met een slimme optimalisatiestrategie, vermindert het voorgestelde raamwerk misinterpretaties en verbetert het de betrouwbaarheid van sentimentvoorspellingen. Hoewel het huidige systeem zich richt op tekst en afbeeldingen, zouden dezelfde ideeën kunnen worden uitgebreid met toon van stem of video, en daarmee de weg banen voor toekomstige hulpmiddelen die menselijke emoties op een natuurlijkere manier begrijpen en meer responsieve, gepersonaliseerde digitale ervaringen ondersteunen.
Bronvermelding: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
Trefwoorden: multimodale sentimentanalyse, emoties op sociale media, fusie van beeld en tekst, deep learning-classifier, kenmerkoptimalisatie