Clear Sky Science · es
Análisis multimodal del sentimiento: modelo de clasificación híbrido con descriptores de características de imagen y texto
Por qué importan tus fotos y publicaciones
Cada día, las personas comparten opiniones mediante mensajes breves, fotos de comidas, imágenes de productos e imágenes de reacción. Empresas, investigadores y aplicaciones quieren saber: ¿es el estado de ánimo detrás de este contenido positivo o negativo? El análisis de sentimiento tradicional suele centrarse únicamente en el texto, ignorando lo que aparece en la imagen. Este artículo presenta una nueva forma de leer las emociones a partir de palabras e imágenes conjuntamente, con el objetivo de lograr una detección de sentimiento más precisa y fiable en datos reales de redes sociales y reseñas.
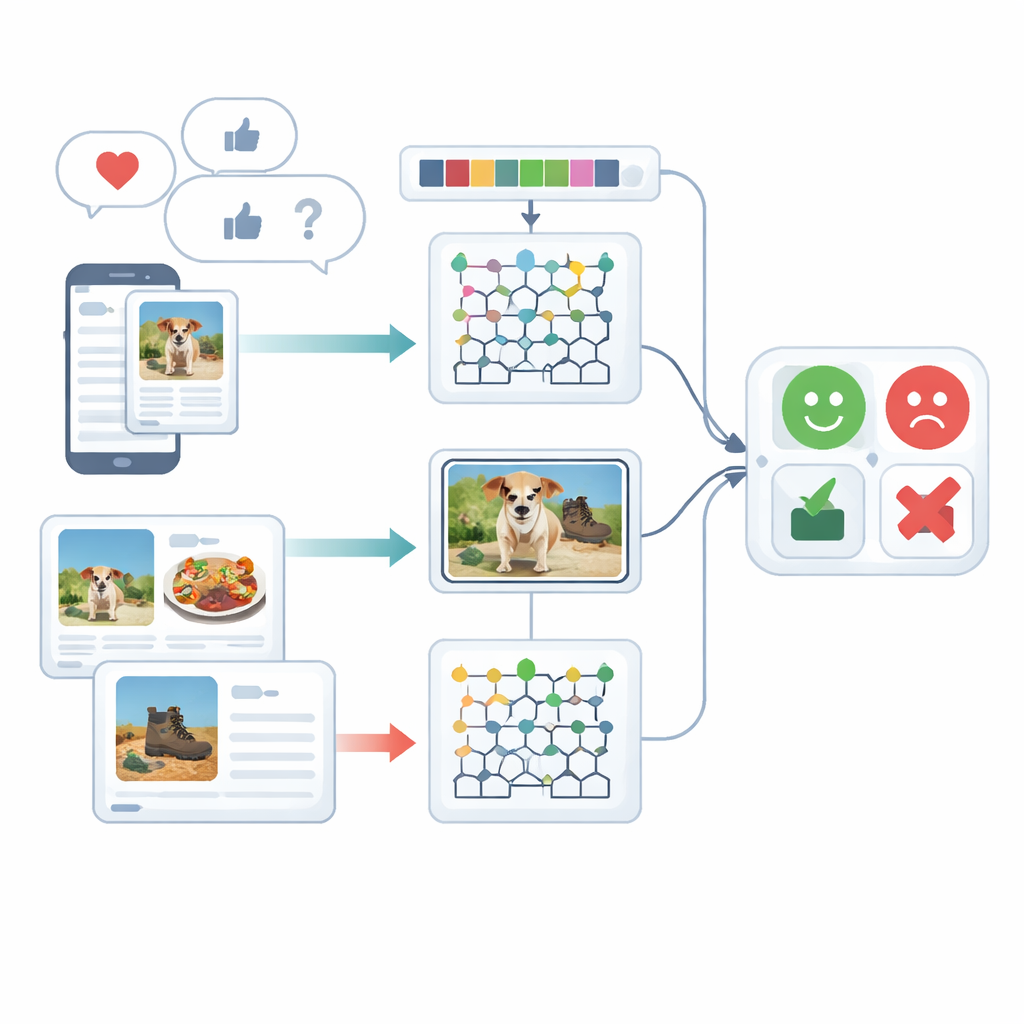
Examinar los sentimientos desde varios ángulos
El estudio se centra en el análisis multimodal del sentimiento, que significa comprender las emociones usando más de un tipo de señal —en este caso, texto escrito e imágenes. Rara vez las personas se expresan de una sola manera: un pie de foto alegre puede ir acompañado de una foto sombría, o una frase sarcástica puede suavizarse con un emoji desenfadado. Los sistemas existentes tienen dificultades para fusionar estas pistas distintas y con frecuencia tratan el texto o las imágenes por separado. Los autores revisan trabajos previos basados en redes neuronales recurrentes, transformers o combinaciones simples de características, y muestran que estos enfoques a menudo pasan por alto vínculos sutiles entre lo escrito y lo mostrado, o requieren recursos de entrenamiento muy intensivos.
Limpiar el desorden antes de interpretarlo
Antes de que cualquier opinión pueda clasificarse, los datos en bruto deben ordenarse. Para el texto, el sistema segmenta las oraciones, elimina palabras vacías comunes como “el” o “y”, y reduce las palabras a su forma base para que términos similares se traten de manera conjunta. También presta atención especial a los emojis, ya que estas pequeñas imágenes aportan fuertes señales emocionales. Para las imágenes, el marco utiliza un método rápido de detección de objetos para localizar los elementos principales en una foto —por ejemplo, comida en un plato o un dispositivo sobre una mesa. Este paso elimina distracciones de fondo para que el procesamiento posterior pueda centrarse en las partes de la imagen que realmente importan al juzgar el sentimiento.
Enseñar al modelo qué debe fijarse
Tras la limpieza, el sistema convierte tanto el texto como las imágenes en descripciones numéricas ricas. En el lado del texto, cuenta secuencias cortas de palabras (N-gramas), rastrea el uso de emojis y utiliza una versión mejorada de un método clásico de ponderación llamado TF–IDF. La mejora asegura que las palabras con carga emocional, que pueden aparecer de forma desigual en distintos tipos de documentos, destaquen con mayor claridad. En el lado de la imagen, el método captura dos tipos de detalle visual: patrones de color y textura, y formas locales. Refina un descriptor de textura conocido para que se conserven diferencias sutiles en color y orientación de bordes, y combina esto con una técnica que representa de forma compacta las formas y texturas de regiones faciales u objetos. En conjunto, estas características ayudan al sistema a distinguir, por ejemplo, una escena de restaurante acogedora de una iluminada de forma dura y poco atractiva.
Combinar dos motores inteligentes en una sola decisión
El núcleo del marco es un modelo híbrido que procesa texto e imágenes con motores de aprendizaje profundo separados y luego fusiona sus juicios. Las características de texto se envían a una red Deep Maxout, un tipo de modelo neuronal que aprende fronteras de decisión flexibles; sus parámetros internos se ajustan mediante un procedimiento de optimización personalizado inspirado en los patrones de caza y movimiento de las belugas. Este optimizador busca de forma eficiente la combinación de pesos que minimiza los errores de clasificación. En paralelo, las características de imagen se introducen en una red recurrente bidireccional modificada que lee la información en ambas direcciones a lo largo de una secuencia. Los autores rediseñan una de sus puertas internas y su función de activación para aprender de forma más eficaz, y emplean aprendizaje por transferencia para que el conocimiento adquirido en un entorno acelere el entrenamiento en otro. Finalmente, las puntuaciones de las ramas de texto e imagen se promedian para producir una decisión única sobre el sentimiento.
Poner el enfoque a prueba
Para evaluar el rendimiento de su método, los investigadores lo prueban en tres tipos de datos: fotos de restaurantes con rasgos comerciales asociados, imágenes de productos de dispositivos Apple y una pequeña colección de publicaciones de Twitter que contienen tanto imágenes como texto. Comparan su sistema híbrido frente a una variedad de competidores modernos, incluidos modelos basados en transformers, redes de atención multimodal y varias técnicas de optimización existentes. En medidas como exactitud, precisión y F-medida, su enfoque sale consistentemente adelante, a menudo con una ventaja clara. Además, converge más rápido durante el entrenamiento y mantiene buen rendimiento incluso cuando se añade ruido artificial, lo que sugiere que es tanto eficiente como robusto.
Qué supone esto para la tecnología cotidiana
En términos sencillos, este trabajo demuestra que los ordenadores pueden percibir mejor nuestras emociones en línea cuando analizan a la vez lo que decimos y lo que mostramos. Al limpiar cuidadosamente los datos, diseñar características más ricas y combinar dos motores neuronales especializados con una estrategia de optimización inteligente, el marco propuesto reduce las interpretaciones erróneas del estado de ánimo y mejora la fiabilidad de las predicciones de sentimiento. Aunque el sistema actual se centra en texto e imágenes, las mismas ideas podrían ampliarse para incluir tono de voz o video, abriendo camino a herramientas futuras que entiendan las emociones humanas de forma más natural y ofrezcan experiencias digitales más reactivas y personalizadas.
Cita: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
Palabras clave: análisis multimodal del sentimiento, emociones en redes sociales, fusión de imagen y texto, clasificador de aprendizaje profundo, optimización de características