Clear Sky Science · de
Multimodale Sentiment-Analyse: hybrides Klassifikationsmodell mit Bild- und Textmerkmalen
Warum Ihre Fotos und Beiträge wichtig sind
Jeden Tag teilen Menschen Meinungen über kurze Nachrichten, Fotos von Mahlzeiten, Produktaufnahmen und Reaktionsbilder. Unternehmen, Forschende und Apps möchten alle wissen: Ist die Stimmung hinter diesen Inhalten positiv oder negativ? Traditionelle Sentiment‑Analysen betrachten meist nur den Text und ignorieren, was auf dem Bild zu sehen ist. Diese Arbeit stellt einen neuen Ansatz vor, der Emotionen aus Worten und Bildern gemeinsam liest, mit dem Ziel, eine genauere und verlässlichere Sentiment‑Erkennung für reale Social‑Media‑ und Bewertungsdaten zu erreichen.
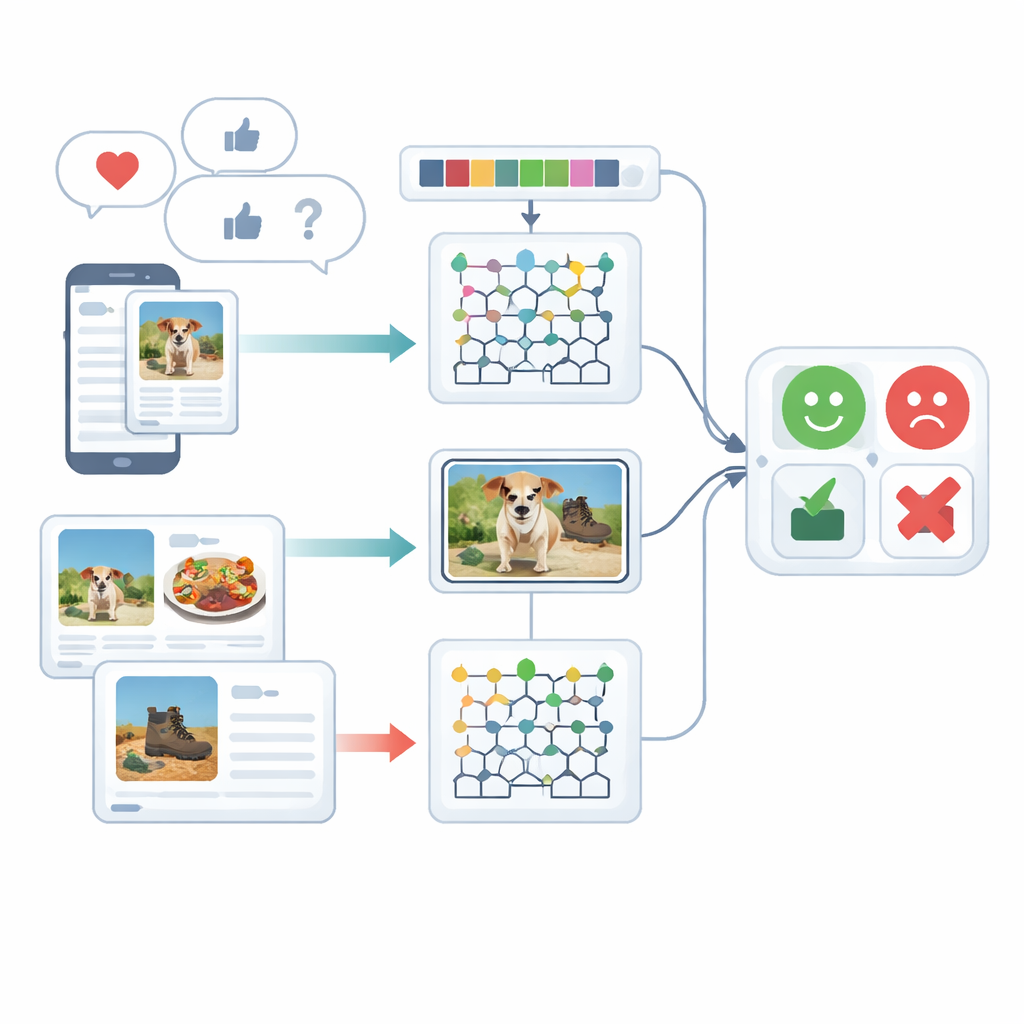
Gefühle aus vielen Blickwinkeln betrachten
Die Studie konzentriert sich auf multimodale Sentiment‑Analyse, das heißt auf das Verstehen von Emotionen mithilfe mehrerer Signaltypen – in diesem Fall geschriebener Text und Bilder. Menschen drücken sich selten nur auf eine Weise aus: Eine heitere Bildunterschrift kann mit einem düsteren Foto gepaart sein, oder ein sarkastischer Satz wird durch ein verspieltes Emoji abgeschwächt. Bestehende Systeme tun sich schwer damit, diese unterschiedlichen Hinweise zu verschmelzen, und behandeln Text oder Bild oft getrennt. Die Autorinnen und Autoren fassen frühere Arbeiten zusammen, die auf rekurrenten neuronalen Netzen, Transformern oder einfachen Merkmal‑Kombinationen beruhen, und zeigen, dass diese Ansätze oft subtile Verknüpfungen zwischen Geschriebenem und Gezeigtem übersehen oder sehr hohe Trainingsressourcen erfordern.
Das Durcheinander bereinigen, bevor es Sinn ergibt
Bevor eine Meinung klassifiziert werden kann, müssen die Rohdaten bereinigt werden. Für den Text zerlegt das System Sätze in Teile, entfernt häufige Füllwörter wie „der“ oder „und“ und reduziert Wörter auf ihre Grundform, damit ähnliche Begriffe zusammengefasst werden. Besonderes Augenmerk gilt Emojis, da diese kleinen Bilder starke emotionale Hinweise tragen. Für Bilder verwendet das Framework eine schnelle Objekterkennung, um die Hauptobjekte in einem Foto zu lokalisieren – etwa Essen auf einem Teller oder ein Gerät auf einem Tisch. Dieser Schritt entfernt Hintergrundstörungen, sodass die spätere Verarbeitung sich auf die Bildbereiche konzentrieren kann, die für die Beurteilung des Sentiments wirklich relevant sind.
Dem Modell beibringen, worauf es achten soll
Nach der Bereinigung wandelt das System sowohl Text als auch Bilder in aussagekräftige numerische Beschreibungen um. Auf der Textseite zählt es kurze Wortfolgen (N‑Gramme), verfolgt die Verwendung von Emojis und nutzt eine verbesserte Version einer klassischen Gewichtungsmethode namens TF–IDF. Die Verbesserung stellt sicher, dass emotional wichtige Wörter, die in unterschiedlichen Dokumenttypen ungleich verteilt auftreten können, deutlicher hervortreten. Auf der Bildseite erfasst die Methode zwei Arten visueller Details: Farb‑ und Texturmuster sowie lokale Formen. Sie verfeinert einen bekannten Texturbeschreiber, sodass subtile Unterschiede in Farbe und Kantenausrichtung erhalten bleiben, und kombiniert dies mit einer Technik, die die Formen und Texturen von Gesichts‑ oder Objektregionen kompakt darstellt. Zusammen helfen diese Merkmale dem System beispielsweise, eine gemütliche Restaurantszene von einer hart beleuchteten, unfreundlichen Szene zu unterscheiden.
Zwei intelligente Motoren zu einer Entscheidung verschmelzen
Das Herzstück des Frameworks ist ein hybrides Modell, das Text und Bilder mit getrennten Deep‑Learning‑Modulen verarbeitet und dann ihre Urteile zusammenführt. Textmerkmale werden an ein Deep‑Maxout‑Netzwerk übergeben, eine Art neuronales Modell, das flexible Entscheidungsgrenzen lernt; seine internen Einstellungen werden durch ein maßgeschneidertes Optimierungsverfahren abgestimmt, das sich an den Jagd‑ und Bewegungsmustern von Beluga‑Walen orientiert. Dieser Optimierer durchsucht effizient die Kombination von Gewichten, die die Klassifikationsfehler minimiert. Parallel dazu werden Bildmerkmale in ein modifiziertes bidirektionales rekurrentes Netzwerk eingespeist, das Informationen entlang einer Sequenz in beide Richtungen liest. Die Autoren überarbeiten eines seiner internen Gates und seine Aktivierungsfunktion, um effektiver zu lernen, und nutzen Transferlernen, sodass in einem Kontext gewonnenes Wissen das Training in einem anderen beschleunigt. Schließlich werden die Scores der Text‑ und Bildzweige gemittelt, um eine einheitliche Sentiment‑Entscheidung zu erhalten.
Den Ansatz auf die Probe stellen
Um die Leistungsfähigkeit ihres Verfahrens zu prüfen, testen die Forschenden es auf drei Datentypen: Restaurantfotos mit zugehörigen geschäftlichen Merkmalen, Produktbildern von Apple‑Geräten und einer kleinen Sammlung von Twitter‑Beiträgen, die sowohl Bilder als auch Text enthalten. Sie vergleichen ihr hybrides System mit einer Reihe moderner Konkurrenten, darunter transformerbasierte Modelle, multimodale Attention‑Netzwerke und mehrere bestehende Optimierungstechniken. Über Messgrößen wie Genauigkeit, Präzision und F‑Maß schneidet ihr Ansatz durchgehend besser ab, oft mit klarem Vorsprung. Er konvergiert zudem schneller während des Trainings und behält gute Leistung bei, selbst wenn künstliches Rauschen hinzugefügt wird, was darauf hindeutet, dass er sowohl effizient als auch robust ist.
Was das für Alltagstechnologie bedeutet
Einfach gesagt zeigt diese Arbeit, dass Computer unsere Online‑Gefühle besser erfassen können, wenn sie zugleich darauf achten, was wir sagen und was wir zeigen. Durch sorgfältige Datenbereinigung, die Gestaltung reichhaltigerer Merkmale und die Kombination zweier spezialisierter neuronaler Motoren mit einer klugen Optimierungsstrategie reduziert das vorgeschlagene Framework Fehlinterpretationen von Stimmungen und erhöht die Zuverlässigkeit von Sentiment‑Vorhersagen. Während das aktuelle System Text und Bilder fokussiert, könnten dieselben Ideen erweitert werden, um etwa Sprachton oder Video einzubeziehen, und so den Weg für künftige Werkzeuge ebnen, die menschliche Emotionen natürlicher verstehen und responsivere, personalisierte digitale Erlebnisse unterstützen.
Zitation: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
Schlüsselwörter: multimodale Sentiment-Analyse, Emotionen in sozialen Medien, Fusion von Bild und Text, Deep-Learning-Klassifikator, Merkmalsoptimierung