Clear Sky Science · fr
Analyse multimodale du sentiment : modèle de classification hybride avec des descripteurs de caractéristiques image et texte
Pourquoi vos photos et publications comptent
Chaque jour, des personnes partagent des opinions via de courts messages, des photos de repas, des clichés de produits et des images de réaction. Entreprises, chercheurs et applications veulent tous savoir : l’humeur derrière ce contenu est-elle positive ou négative ? L’analyse de sentiment traditionnelle se concentre principalement sur le texte seul, en ignorant ce que montre l’image. Cet article présente une nouvelle façon de lire les émotions à la fois à partir des mots et des images, visant une détection du sentiment plus précise et plus fiable sur des données réelles issues des réseaux sociaux et des avis.
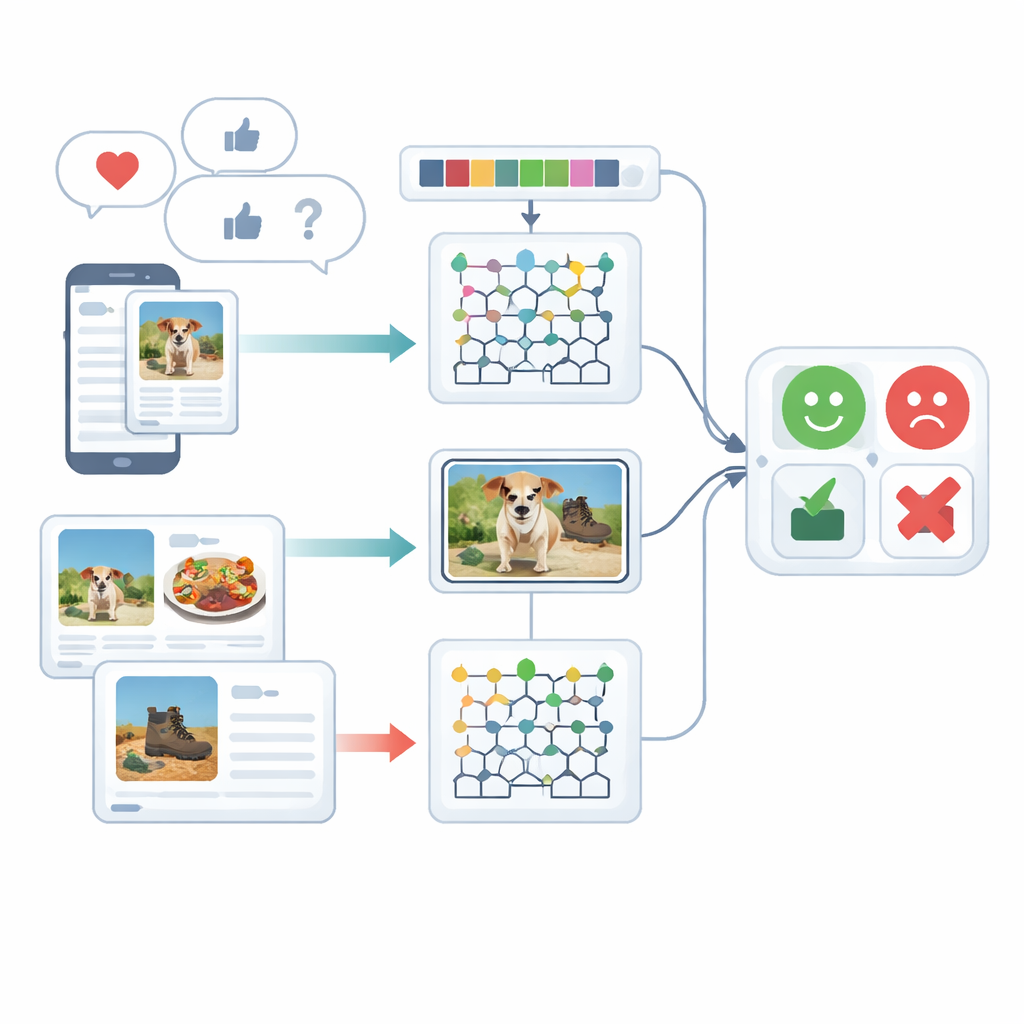
Observer les sentiments sous plusieurs angles
L’étude porte sur l’analyse multimodale des sentiments, c’est‑à‑dire la compréhension des émotions en utilisant plus d’un type de signal — ici, le texte écrit et les images. Les personnes s’expriment rarement d’une seule manière : une légende enjouée peut accompagner une photo morose, ou une phrase sarcastique peut être adoucie par un emoji ludique. Les systèmes existants ont du mal à fusionner ces indices différents et traitent souvent le texte ou l’image séparément. Les auteurs passent en revue les travaux antérieurs basés sur des réseaux récurrents, des transformeurs ou de simples combinaisons de caractéristiques, et montrent que ces approches négligent souvent les liens subtils entre ce qui est écrit et ce qui est montré, ou exigent des ressources d’entraînement très lourdes.
Nettoyer le bazar avant d’en extraire du sens
Avant de pouvoir classifier une opinion, il faut nettoyer les données brutes. Pour le texte, le système segmente les phrases, supprime les mots-vides courants comme « le » ou « et », et ramène les mots à leur forme de base afin que les termes similaires soient traités ensemble. Il accorde aussi une attention particulière aux emojis, car ces petites images portent des indices émotionnels forts. Pour les images, le cadre utilise une méthode de détection d’objets rapide pour localiser les éléments principaux d’une photo — par exemple un plat sur une assiette ou un gadget sur une table. Cette étape élimine les distractions d’arrière-plan afin que le traitement ultérieur se concentre sur les parties de l’image réellement pertinentes pour juger le sentiment.
Apprendre au modèle ce qu’il faut remarquer
Après le nettoyage, le système transforme le texte et les images en descriptions numériques riches. Du côté texte, il compte des séquences de mots courtes (n-grammes), suit l’usage des emojis et utilise une version améliorée d’une méthode classique de pondération appelée TF–IDF. L’amélioration veille à ce que les mots à forte charge émotionnelle, qui peuvent apparaître de manière inégale selon les types de documents, ressortent plus clairement. Du côté image, la méthode capture deux types de détails visuels : les motifs de couleur et de texture, et les formes locales. Elle affine un descripteur de texture connu pour préserver les différences subtiles de couleur et d’orientation des contours, et combine cela avec une technique qui représente de façon compacte les formes et textures des régions faciales ou des objets. Ensemble, ces caractéristiques aident le système à distinguer, par exemple, une scène de restaurant chaleureuse d’une scène durement éclairée et peu accueillante.
Fusionner deux moteurs intelligents en une seule décision
Le cœur du cadre est un modèle hybride qui traite le texte et les images avec des moteurs d’apprentissage profond séparés puis fusionne leurs jugements. Les caractéristiques textuelles sont envoyées à un réseau Deep Maxout, un type de modèle neuronal qui apprend des frontières de décision flexibles ; ses paramètres internes sont réglés par une procédure d’optimisation personnalisée inspirée des schémas de chasse et de déplacement des bélugas. Cet optimiseur recherche efficacement la combinaison de poids qui minimise les erreurs de classification. En parallèle, les caractéristiques d’image sont injectées dans un réseau récurrent bidirectionnel modifié qui lit l’information dans les deux sens le long d’une séquence. Les auteurs reconfigurent l’une de ses portes internes et sa fonction d’activation pour améliorer l’apprentissage, et utilisent l’apprentissage par transfert pour que les connaissances acquises dans un contexte accélèrent l’entraînement dans un autre. Enfin, les scores des branches texte et image sont moyennés pour produire une décision unique de sentiment.
Mettre l’approche à l’épreuve
Pour évaluer l’efficacité de leur méthode, les chercheurs la testent sur trois types de données : des photos de restaurants avec attributs commerciaux associés, des images de produits d’appareils Apple, et une petite collection de publications Twitter contenant à la fois images et texte. Ils comparent leur système hybride à une gamme de concurrents modernes, y compris des modèles basés sur les transformeurs, des réseaux d’attention multimodale et plusieurs techniques d’optimisation existantes. Selon des métriques telles que la précision, le rappel et la F-mesure, leur approche arrive systématiquement en tête, souvent avec une marge nette. Elle converge également plus rapidement pendant l’entraînement et conserve de bonnes performances même lorsque du bruit artificiel est ajouté, ce qui suggère qu’elle est à la fois efficace et robuste.
Ce que cela signifie pour la technologie du quotidien
Concrètement, ce travail montre que les ordinateurs peuvent mieux saisir nos sentiments en ligne lorsqu’ils regardent ce que nous disons et ce que nous montrons simultanément. En nettoyant soigneusement les données, en concevant des caractéristiques plus riches et en combinant deux moteurs neuronaux spécialisés avec une stratégie d’optimisation intelligente, le cadre proposé réduit les interprétations erronées d’humeur et améliore la fiabilité des prédictions de sentiment. Bien que le système actuel se concentre sur le texte et l’image, les mêmes idées pourraient être étendues pour inclure le ton de la voix ou la vidéo, ouvrant la voie à des outils futurs qui comprennent les émotions humaines de manière plus naturelle et soutiennent des expériences numériques plus réactives et personnalisées.
Citation: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
Mots-clés: analyse multimodale des sentiments, émotions sur les réseaux sociaux, fusion image et texte, classifieur par apprentissage profond, optimisation des caractéristiques