Clear Sky Science · pl
Wielomodalna analiza nastroju: hybrydowy model klasyfikacyjny z deskryptorami cech obrazu i tekstu
Dlaczego twoje zdjęcia i posty mają znaczenie
Codziennie ludzie dzielą się opiniami za pomocą krótkich wiadomości, zdjęć posiłków, fotografii produktów i obrazków-reakcji. Firmy, badacze i aplikacje chcą wiedzieć: czy nastrój stojący za tymi treściami jest pozytywny, czy negatywny? Tradycyjna analiza nastroju zwykle skupia się wyłącznie na tekście, pomijając to, co widoczne na zdjęciu. Artykuł przedstawia nowy sposób odczytywania emocji z jednoczesnej analizy słów i obrazów, dążąc do dokładniejszego i bardziej wiarygodnego wykrywania nastroju na rzeczywistych danych społecznościowych i recenzenckich.
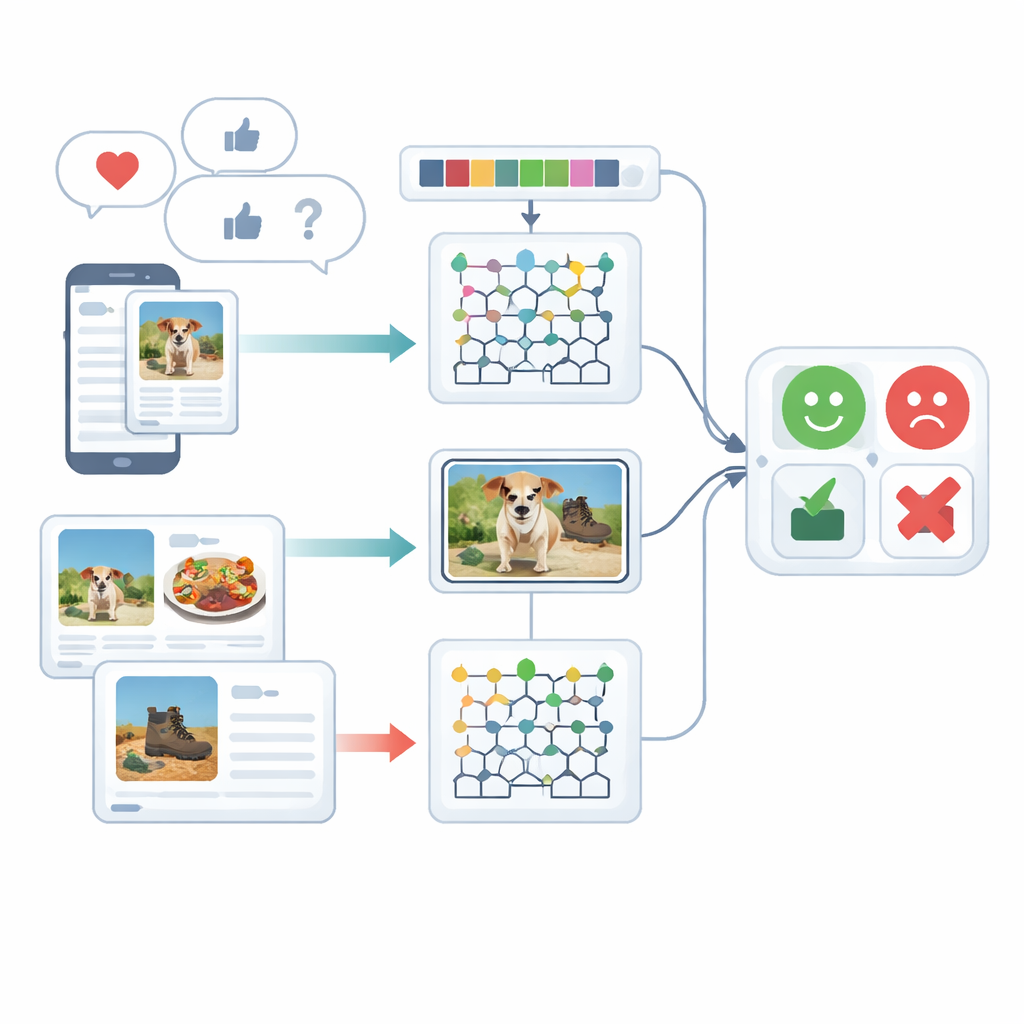
Patrzenie na uczucia z wielu stron
Badanie koncentruje się na wielomodalnej analizie nastroju, czyli rozumieniu emocji przy użyciu więcej niż jednego rodzaju sygnału — w tym przypadku tekstu pisanego i obrazów. Ludzie rzadko wyrażają się tylko jednym kanałem: radosny podpis może towarzyszyć ponurej fotografii, a sarkastyczne zdanie może być złagodzone zabawnym emotikonem. Istniejące systemy mają trudności z połączeniem tych różnych wskazówek i często traktują tekst lub obraz osobno. Autorzy przeglądają wcześniejsze prace oparte na rekurencyjnych sieciach neuronowych, transformerach czy prostych kombinacjach cech, pokazując, że te podejścia często pomijają subtelne powiązania między tym, co napisane, a tym, co pokazane, albo wymagają bardzo dużych zasobów treningowych.
Porządkowanie bałaganu zanim zaczniemy go rozumieć
Zanim jakakolwiek opinia zostanie sklasyfikowana, surowe dane trzeba uprzątnąć. Dla tekstu system dzieli zdania na fragmenty, usuwa powszechne wypełniacze takie jak „the” czy „and” i sprowadza wyrazy do formy podstawowej, aby podobne terminy były traktowane wspólnie. Zwraca też szczególną uwagę na emotikony, ponieważ te małe obrazki niosą silne wskazówki emocjonalne. Dla obrazów rama używa szybkiej metody wykrywania obiektów, aby zlokalizować główne elementy zdjęcia — na przykład jedzenie na talerzu czy gadżet na stole. Ten krok usuwa rozpraszające tło, dzięki czemu dalsze przetwarzanie może skupić się na częściach obrazu istotnych przy ocenie nastroju.
Nauczanie modelu, na co zwracać uwagę
Po oczyszczeniu system przekształca zarówno tekst, jak i obrazy w bogate opisy numeryczne. Po stronie tekstowej liczy krótkie sekwencje słów (n-gramy), śledzi użycie emotikonów i wykorzystuje ulepszoną wersję klasycznej metody ważenia zwanej TF–IDF. Ulepszenie to sprawia, że emocjonalnie ważne słowa, które mogą pojawiać się nierównomiernie w różnych typach dokumentów, wyróżniają się wyraźniej. Po stronie obrazów metoda uchwyca dwa rodzaje szczegółów wizualnych: wzory koloru i tekstury oraz lokalne kształty. Dopracowuje znany deskryptor tekstury tak, aby subtelne różnice w kolorze i orientacji krawędzi były zachowane, i łączy to z techniką reprezentującą kształty i tekstury regionów twarzy lub obiektów w skondensowanej formie. Razem te cechy pomagają systemowi rozróżnić na przykład przytulną scenę w restauracji od ostro oświetlonej, nieprzyjaznej przestrzeni.
Łączenie dwóch inteligentnych silników w jedną decyzję
Rdzeniem ram jest model hybrydowy, który przetwarza tekst i obrazy za pomocą oddzielnych silników głębokiego uczenia, a następnie scala ich oceny. Cechy tekstowe trafiają do sieci Deep Maxout, rodzaju modelu neuronowego uczącego się elastycznych granic decyzyjnych; jej wewnętrzne ustawienia są dostrajane przez niestandardową procedurę optymalizacji inspirowaną wzorcami polowania i ruchu białuchy. Ten optymalizator efektywnie przeszukuje kombinację wag minimalizującą błędy klasyfikacji. Równolegle cechy obrazów są podawane do zmodyfikowanej dwukierunkowej sieci rekurencyjnej, która odczytuje informacje w obu kierunkach wzdłuż sekwencji. Autorzy przeprojektowali jedno z jej wewnętrznych „bramek” oraz funkcję aktywacji, aby uczyć się efektywniej, i używają uczenia transferowego, by wiedza zdobyta w jednym zadaniu przyspieszała trening w innym. Na koniec wyniki z gałęzi tekstowej i obrazowej są uśredniane, dając pojedynczą decyzję o nastroju.
Wystawienie metody na próbę
Aby ocenić skuteczność metody, badacze testują ją na trzech typach danych: zdjęciach restauracji z powiązanymi cechami działalności, zdjęciach produktów Apple oraz niewielkim zbiorze postów z Twittera zawierających zarówno obraz, jak i tekst. Porównują swój system hybrydowy z szeregiem nowoczesnych konkurentów, w tym modelami opartymi na transformerach, multimodalnymi sieciami uwagowymi i kilkoma istniejącymi technikami optymalizacji. W miarach takich jak dokładność, precyzja i miara F ich podejście konsekwentnie wypada lepiej, często z wyraźną przewagą. Zbiega się też szybciej podczas treningu i utrzymuje dobrą wydajność nawet po dodaniu sztucznego szumu, co sugeruje, że jest zarówno wydajne, jak i odporne.
Co to oznacza dla codziennych technologii
Mówiąc prościej, praca ta pokazuje, że komputery mogą lepiej wyczuwać nasze uczucia w sieci, gdy patrzą jednocześnie na to, co mówimy, i co pokazujemy. Poprzez staranne oczyszczenie danych, zaprojektowanie bogatszych cech i połączenie dwóch wyspecjalizowanych silników neuronowych ze sprytną strategią optymalizacji, proponowane rozwiązanie zmniejsza błędy w odczycie nastrojów i poprawia wiarygodność predykcji. Chociaż obecny system koncentruje się na tekście i obrazach, te same pomysły można rozszerzyć o ton głosu czy wideo, otwierając drogę do przyszłych narzędzi, które naturalniej rozumieją ludzkie emocje i wspierają bardziej responsywne, spersonalizowane doświadczenia cyfrowe.
Cytowanie: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
Słowa kluczowe: wielomodalna analiza nastroju, emocje w mediach społecznościowych, fuzja obrazu i tekstu, klasyfikator głębokiego uczenia, optymalizacja cech