Clear Sky Science · ar
تحليل المشاعر متعدد الوسائط: نموذج تصنيف هجين بوصفات ميزات من الصورة والنص
لماذا تَهمّ صورك ومنشوراتك
يشارك الناس يوميًا آراءهم عبر رسائل قصيرة، صور لوجبات، لقطات لمنتجات، وصور تعبيرية. الشركات والباحثون والتطبيقات جميعهم يرغبون في معرفة: هل المزاج وراء هذا المحتوى إيجابي أم سلبي؟ التحليل التقليدي للمشاعر ينظر في النص وحده عادةً، متجاهلًا ما تظهره الصورة. تقدم هذه الورقة طريقة جديدة لقراءة العواطف من الكلمات والصور معًا، بهدف تحقيق كشف للمشاعر أكثر دقة وموثوقية على بيانات حقيقية من الوسائط الاجتماعية والمراجعات.
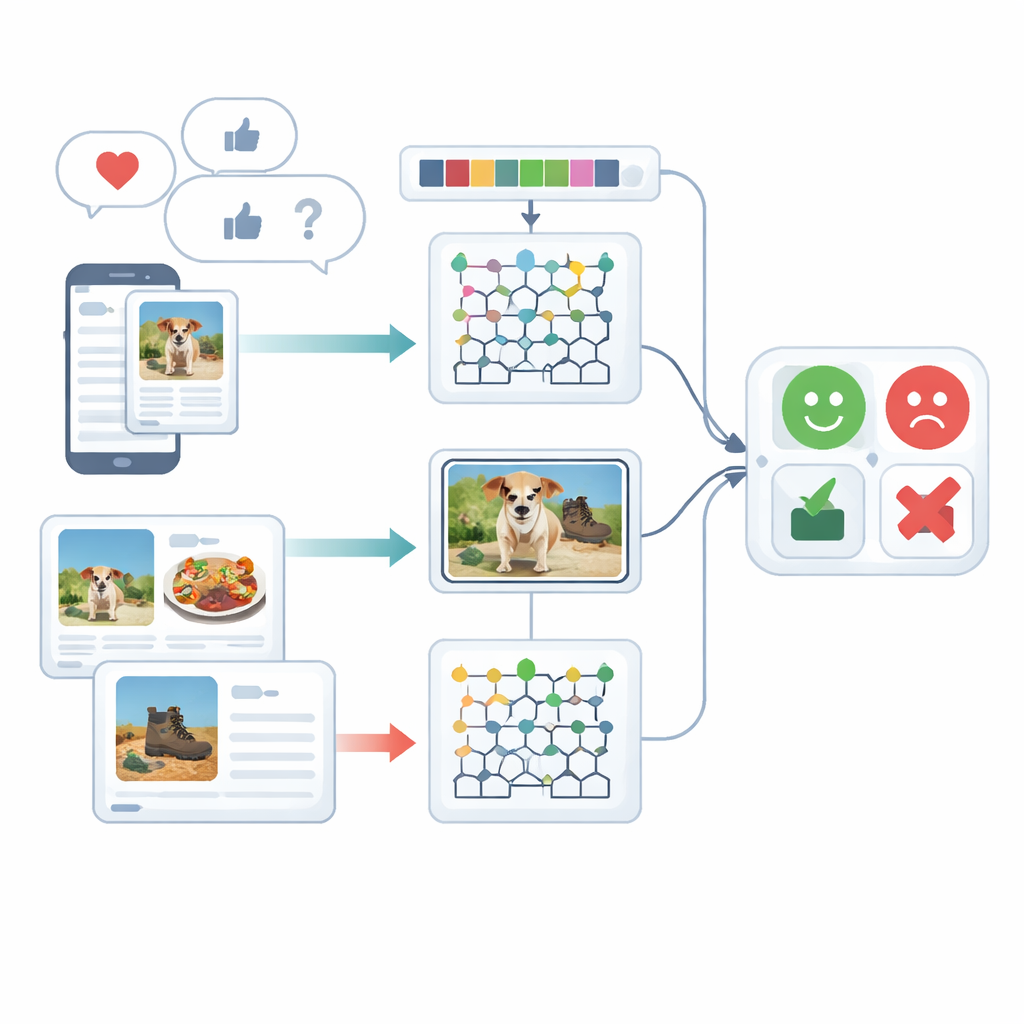
النظر إلى المشاعر من زوايا متعددة
تركز الدراسة على تحليل المشاعر متعدد الوسائط، أي فهم العواطف باستخدام أكثر من نوع واحد من الإشارات — في هذه الحالة النص المكتوب والصور. نادراً ما يعبر الناس عن أنفسهم بطريقة واحدة فقط: تعليق مرح قد يقترن بصورة قاتمة، أو جملة ساخرة قد تُخفّف بواسطة إيموجي مرِح. الأنظمة الحالية تكافح لدمج هذه الأدلة المختلفة وغالبًا ما تتعامل مع النص أو الصور بشكل منفصل. يستعرض المؤلفون الأعمال السابقة التي تعتمد على الشبكات العصبونية المتكررة، أو المحولات، أو مجموعات الميزات البسيطة، ويظهرون أن هذه الأساليب غالبًا ما تتجاهل الروابط الدقيقة بين ما يُكتب وما يُعرض، أو تتطلب موارد تدريب ضخمة.
تنظيف الفوضى قبل فهمها
قبل أن يُصنّف أي رأي، يجب ترتيب البيانات الخام. بالنسبة للنص، يكسر النظام الجمل إلى أجزاء، ويزيل كلمات حشو شائعة مثل «الـ» أو «و»، ويقلّص الكلمات إلى شكلها الأساسي حتى تُعالج المصطلحات المماثلة معًا. كما يولِي اهتمامًا خاصًا بالإيموجي، لأن هذه الصور الصغيرة تحمل دلائل انفعالية قوية. بالنسبة للصور، يستخدم الإطار طريقة سريعة لاكتشاف الكائنات لتحديد العناصر الرئيسية في الصورة — مثل طعام على طبق أو جهاز على طاولة. تزيل هذه الخطوة تشتيت الخلفية حتى تتركز المعالجة اللاحقة على أجزاء الصورة ذات الأهمية الحقيقية لتقييم المشاعر.
تعليم النموذج ما الذي يجب ملاحظته
بعد التنظيف، يحوّل النظام النص والصور إلى أوصاف رقمية غنية. في جانب النص، يحسب تكرارات متتاليات الكلمات القصيرة (N-grams)، يتتبع استخدام الإيموجي، ويستخدم نسخة محسنة من طريقة الترجيح الكلاسيكية المسماة TF–IDF. التحسين يضمن أن الكلمات ذات الأهمية الانفعالية، التي قد تظهر بتوزيع غير متساوٍ عبر أنواع الوثائق، تبرز بوضوح أكبر. على جانب الصورة، تلتقط الطريقة نوعين من التفاصيل البصرية: أنماط اللون والملمس والأشكال المحلية. تُنقّح وصفة نسيج معروفة بحيث تُحفظ الفوارق الدقيقة في اللون واتجاه الحواف، وتُدمج هذه مع تقنية تمثل أشكال ومنسوجات مناطق الوجوه أو الأشياء بصورة مضغوطة. معًا، تساعد هذه الميزات النظام على التمييز، على سبيل المثال، بين مشهد مطعم مريح ومشهد مُضاء بشكل قاسٍ غير جذاب.
دمج محركين ذكيين في قرار واحد
لب الإطار هو نموذج هجين يعالج النص والصور بمحركات تعلم عميق منفصلة ثم يدمج أحكامهما. تُرسل ميزات النص إلى شبكة Deep Maxout، وهو نوع من النماذج العصبية يتعلم حدود قرار مرنة؛ تُضبط إعداداته الداخلية بواسطة إجراء تحسين مخصص مستوحى من أنماط الصيد والحركة لحيتان البيلوجا. يبحث هذا المحسّن بكفاءة عن مجموعة الأوزان التي تُقلّل أخطاء التصنيف. بالتوازي، تُغذى ميزات الصورة إلى شبكة متكررة ثنائية الاتجاه معدّلة تقرأ المعلومات في كلا الاتجاهين على طول تسلسل. يعيد المؤلفون تصميم أحد بواباته الداخلية ودالة التفعيل الخاصة به ليتعلم بصورة أكثر فعالية، ويستخدمون التعلم النقلي حتى تُسرّع المعرفة المكتسبة في بيئة ما تدريبًا في بيئات أخرى. أخيرًا، تُؤخذ معدلات الفرعين النصي والصوري وتُحصّل للحصول على قرار واحد للمشاعر.
اختبار المنهجية
لاختبار فعالية طريقتهم، يجرب الباحثون النظام على ثلاثة أنواع من البيانات: صور مطاعم مع خصائص تجارية مرتبطة بها، صور منتجات لأجهزة آبل، ومجموعة صغيرة من منشورات تويتر التي تحتوي على صور ونص معًا. يقارنون نظامهم الهجين بمجموعة من المنافسين الحديثين، بما في ذلك نماذج قائمة على المحولات، وشبكات الانتباه متعددة الوسائط، وعدة تقنيات تحسين موجودة. عبر مقاييس مثل الدقة والدقة المرجعية ومقياس F، يخرج نهجهم متفوقًا باستمرار، غالبًا بفارق واضح. كما يتقارب بسرعة أثناء التدريب ويحافظ على أداء جيد حتى عند إضافة ضوضاء اصطناعية، مما يشير إلى كفاءته ومتانته.
ماذا يعني هذا للتقنية اليومية
بعبارات بسيطة، تُظهر هذه العمل أن الحواسيب يمكنها أن تحس بمشاعرنا على الإنترنت بشكل أفضل عندما تنظر إلى ما نقوله وما نعرضه في آنٍ واحد. من خلال تنظيف البيانات بعناية، وتصميم ميزات أغنى، ودمج محركين عصبيين متخصّصين مع استراتيجية تحسين ذكية، يقلل الإطار المقترح من سوء فهم المزاج ويحسّن موثوقية توقعات المشاعر. بينما يركز النظام الحالي على النص والصورة، يمكن توسعة نفس الأفكار لتشمل نبرة الصوت أو الفيديو، ممهّدة الطريق لأدوات مستقبلية تفهم المشاعر البشرية بصورة أكثر طبيعية وتدعم تجارب رقمية أكثر تجاوبًا وتخصيصًا.
الاستشهاد: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
الكلمات المفتاحية: تحليل المشاعر متعدد الوسائط, عواطف وسائل التواصل الاجتماعي, دمج الصورة والنص, مُصنِّف التعلم العميق, تحسين الميزات