Clear Sky Science · he
ניתוח רגש מולטימודלי: מודל סיווג היברידי המבוסס על תיאורי תכונות מתמונה וטקסט
מדוע התמונות והפוסטים שלכם חשובים
יום־יום אנשים משתפים דעות דרך הודעות קצרות, תמונות של ארוחות, תמונות מוצר ותמונות תגובה. חברות, חוקרים ואפליקציות רוצים לדעת: האם המצב־הרוח שמאחורי התוכן חיובי או שלילי? ניתוח רגשות מסורתי מתבסס בעיקר על טקסט ומזניח את מה שמופיע בתמונה. מאמר זה מציג שיטה חדשה לקריאת רגשות משילוב של מילים ותמונות יחד, במטרה להשיג זיהוי רגשות מדויק ואמין יותר על נתוני מדיה חברתית וביקורות מהעולם האמיתי.
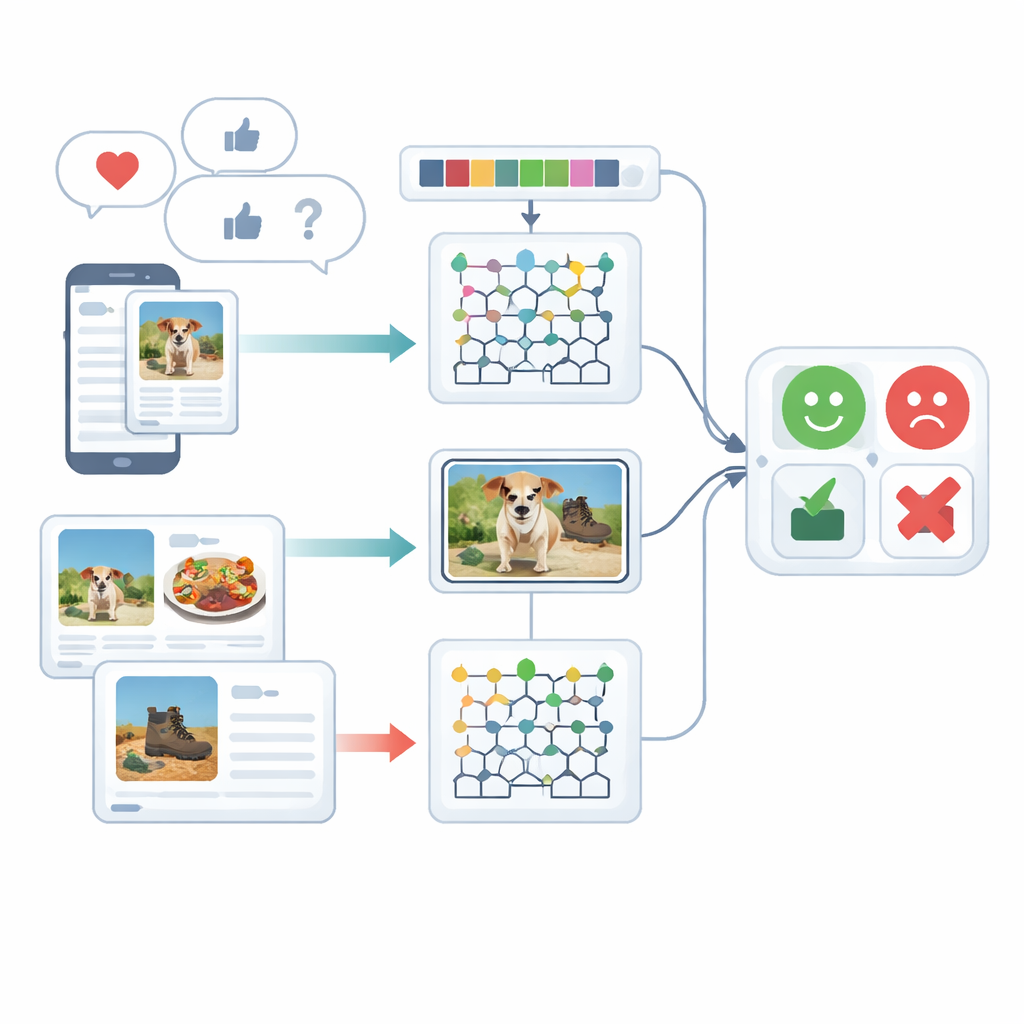
בהסתכלות על רגשות מכמה זוויות
המחקר מתמקד בניתוח רגש מולטימודלי — כלומר הבנת רגשות באמצעות יותר מסוג אחד של אותות — במקרה זה טקסט כתוב ותמונות. אנשים לעתים נדירות מבטאים את עצמם בצורה יחידה: כתובית שמחה יכולה להיגרר אחרי צילום קודר, או משפט סרקסטי יכול להיות מרוכך על־ידי אימוג׳י שובב. מערכות קיימות מתקשות למזג את הרמזים השונים ולעתים מתייחסות לטקסט או לתמונה בנפרד. המחברים בוחנים עבודות קודמות שהתבססו על רשתות נוירונים חוזרות, טרנספורמרים או שילובי תכונות פשוטים, ומראים שגישות אלו לעתים מפספסות קשרים זעירים בין הכתוב והמצולם או דורשות משאבי אימון כבדים מאוד.
ניקוי הבלגן לפני שמבינים אותו
לפני שניתן לסווג דעה, יש לסדר את הנתונים הגולמיים. בטקסט המערכת מפרקת משפטים לחלקים, מסירה מילים שגרתיות כמו «ה» או «ו׳», ומצמצמת מילים לצורתן הבסיסית כדי לטפל במונחים דומים ביחד. המערכת מקדישה גם תשומת־לב מיוחדת לאימוג׳ים, שכן אלה נושאים רמזים רגשיים חזקים. בתמונות, מסגרת העבודה משתמשת בשיטת זיהוי עצמים מהירה לאיתור הפריטים המרכזיים בתמונה — כגון אוכל על צלחת או גאדג׳ט על שולחן. שלב זה מסיר הסחות רקע כדי שעיבוד מאוחר יוכל להתמקד בחלקי התמונה הרלוונטיים לשיפוט הרגש.
ללמד את המודל מה לשים לב אליו
לאחר ניקוי, המערכת ממירה הן טקסט והן תמונות לתיאורים מספריים עשירים. בצד הטקסט היא סופרת רצפי מילים קצרים (N‑grams), עוקבת אחרי שימוש באימוג׳ים ומשתמשת בגרסה משופרת של שיטת המשקל המסורתית TF–IDF. השיפור מבטיח שמילים בעלות חשיבות רגשית, שעשויות להופיע באופן בלתי שוויוני בסוגי מסמכים שונים, יוצאו יותר בולטות. בצד התמונה, השיטה לוכדת שני סוגי פרטי חזותיים: דפוסי צבע ומרקם וצורות מקומיות. היא משכללת תיאור מרקם ידוע כך שפרטים עדינים של צבע וכיווני קצוות נשמרים, ומשלבת זאת עם טכניקה המייצגת בצורה דחוסה את הצורות והמרקמים של אזורי פנים או עצמים. יחד התכונות האלו מאפשרות למערכת להבחין, לדוגמה, בין סצנה מזמינה של מסעדה לבין סצנה מוארת בחוזקה ומעבירה אווירה לא נעימה.
מיזוג שני מנועים חכמים להחלטה אחת
לב המסגרת הוא מודל היברידי שמעבד טקסט ותמונות באמצעות מנועי למידה עמוקה נפרדים ואז מאחד את החלטותיהם. תכונות הטקסט נשלחות לרשת Deep Maxout, סוג של מודל נוירוני הלומד גבולות החלטה גמישים; ההגדרות הפנימיות שלו מכויילות על־ידי פרוצדורת אופטימיזציה מותאמת בהשראת דפוסי הציד והתנועה של לווייתן בְּלוּגָה. מאפיין זה מחפש ביעילות את שילוב המשקלים שממזער שגיאות סיווג. במקביל, תכונות התמונה מוזנות לרשת חוזרת כיוונית־שתי־הכיוונים שעוברת על רצף המידע בשני הכיוונים. המחברים שידרגו אחד מהשערים הפנימיים ואת פונקציית ההפעלה כדי לאפשר למידה יעילה יותר, והם משתמשים בעברת למידה כך שידע שנלמד בהקשר אחד יוכל להאיץ אימון בהקשר אחר. בסופו של דבר, הציונים של ענפי הטקסט והתמונה ממוצעים כדי להניב החלטת רגש אחת.
בדיקת השיטה במבחן
כדי לבדוק עד כמה השיטה עובדת, החוקרים בודקים אותה על שלושה סוגי נתונים: תמונות מסעדות עם מאפייני עסק נלווים, תמונות מוצר של מכשירי Apple ואוסף קטן של פוסטים בטוויטר המכילים גם תמונות וגם טקסט. הם משווים את המערכת ההיברידית שלהם מול מגוון מתחרים מודרניים, כולל מודלים מבוססי טרנספורמר, רשתות תשומת לב מולטימודליות ומספר טכניקות אופטימיזציה קיימות. על פני מדדים כגון דיוק, דיוק חיובי ומדד F, הגישה שלהם מגיעה בעקביות למקום הראשון, לעתים בפער ברור. כמו כן היא מתכנסת מהר יותר במהלך האימון ושומרת על ביצועים טובים גם כאשר נוסף רעש מלאכותי, מה שמעיד על יעילות ועמידות.
מה משמעות הדבר לטכנולוגיה היומיומית
במילים פשוטות, עבודה זו מראה שמחשבים יכולים לחוש טוב יותר את רגשותינו אונליין כשמביטים גם במה שאנו כותבים וגם במה שאנו מציגים יחד. על‑ידי ניקוי קפדני של הנתונים, עיצוב תכונות עשירות ושילוב שני מנועי נוירונים מיוחדים עם אסטרטגיית אופטימיזציה חכמה, המסגרת המוצעת מפחיתה קריאות שגויות של מצבי רוח ומשפרת את אמינות תחזיות הרגש. בעוד המערכת הנוכחית מתמקדת בטקסט ותמונות, ניתן להרחיב את הרעיונות הללו לכלול גם גוון דיבור או וידאו, ולפתוח דלת לכלים עתידיים שמבינים רגשות אנושיים באופן טבעי יותר ותומכים בחוויות דיגיטליות מותאמות ורגישות יותר.
ציטוט: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
מילות מפתח: ניתוח רגש מולטימודלי, רגשות ברשתות חברתיות, מיזוג תמונה וטקסט, מקטלג למידה עמוקה, אופטימיזציית תכונות