Clear Sky Science · ru
Мультимодальный анализ настроений: гибридная модель классификации с дескрипторами признаков изображения и текста
Почему важны ваши фото и публикации
Каждый день люди делятся мнениями через короткие сообщения, фото блюд, снимки товаров и реакционные картинки. Компании, исследователи и приложения хотят понять: положительно или отрицательно настроение за этим контентом? Традиционный анализ настроений в основном смотрит только на текст, игнорируя то, что изображено на фотографии. В этой работе предложен новый подход к чтению эмоций одновременно по словам и изображениям, с целью более точного и надежного определения настроения на реальных данных из соцсетей и отзывов.
Изучая чувства с разных сторон
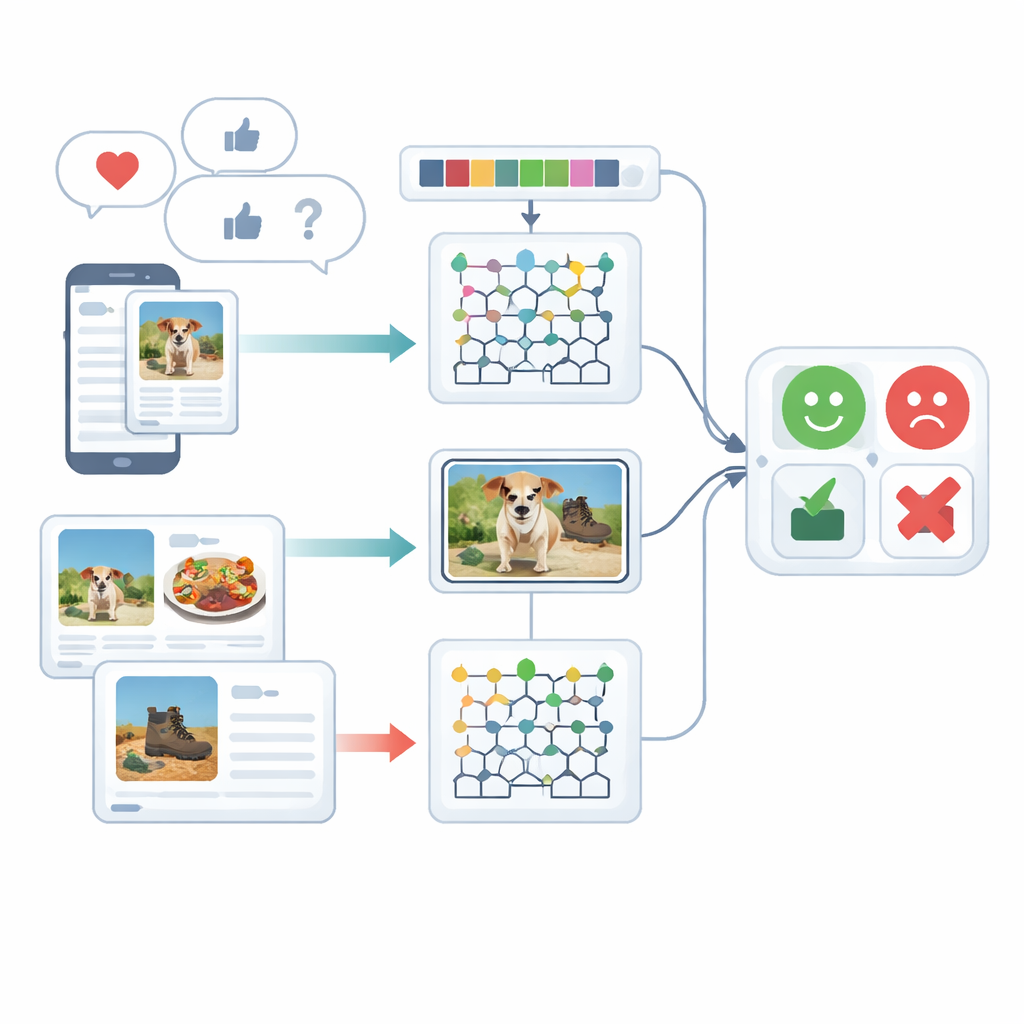
Исследование сосредоточено на мультимодальном анализе настроений, то есть на понимании эмоций с помощью более чем одного типа сигналов — в данном случае письменного текста и изображений. Люди редко выражают себя только одним способом: радостная подпись может сопровождать мрачное фото, а саркастичное высказывание — смягчаться игривым эмодзи. Существующие системы с трудом объединяют эти разные подсказки и часто обрабатывают текст или изображение по отдельности. Авторы рассматривают предыдущие работы, основанные на рекуррентных нейронных сетях, трансформерах или простых комбинациях признаков, и показывают, что такие подходы часто упускают тонкие связи между тем, что написано, и тем, что показано, либо требуют больших вычислительных ресурсов для обучения.
Уборка данных перед их анализом
Прежде чем классифицировать мнение, необработанные данные нужно привести в порядок. Для текста система разбивает предложения на части, удаляет общеупотребительные служебные слова вроде «the» или «and» и приводит слова к их базовой форме, чтобы похожие термины обрабатывались вместе. Особое внимание уделяется эмодзи, поскольку эти маленькие изображения несут сильные эмоциональные сигналы. Для изображений фреймворк использует быстрый метод обнаружения объектов, чтобы локализовать главные предметы на фото — например, еду на тарелке или гаджет на столе. Этот этап устраняет фоновую путаницу, позволяя дальнейшей обработке сосредоточиться на частях изображения, действительно важных для оценки настроения.
Обучая модель тому, на что стоит обращать внимание
После очистки система превращает как текст, так и изображения в подробные числовые описания. Со стороны текста она считает короткие последовательности слов (N-граммы), учитывает использование эмодзи и применяет улучшенную версию классического метода взвешивания TF–IDF. Улучшение обеспечивает более четкое выделение эмоционально значимых слов, которые могут появляться неравномерно в разных типах документов. Со стороны изображений метод захватывает два вида визуальных деталей: цветовые и текстурные паттерны и локальные формы. Он уточняет известный текстурный дескриптор так, чтобы сохранялись тонкие различия в цвете и ориентации границ, и сочетает это с техникой, которая компактно представляет формы и текстуры областей лица или объектов. В совокупности эти признаки помогают системе отличать, например, уютную сцену в ресторане от жестко освещённой, неприветливой.
Слияние двух продвинутых движков в одном решении
Ядро фреймворка — гибридная модель, которая обрабатывает текст и изображения отдельными глубокими нейронными движками, а затем объединяет их суждения. Текстовые признаки поступают в сеть Deep Maxout — тип нейронной модели, который обучается гибким границам принятия решений; её внутренние параметры настраиваются с помощью специальной процедуры оптимизации, вдохновлённой охотой и движениями белух. Этот оптимизатор эффективно ищет комбинацию весов, минимизирующую ошибки классификации. Параллельно признаки изображений подаются в модифицированную двунаправленную рекуррентную сеть, которая читает информацию в обоих направлениях вдоль последовательности. Авторы переработали один из внутренних вентилей и функцию активации, чтобы сеть училась эффективнее, и использовали перенос обучения, чтобы знания, полученные в одной задаче, ускоряли обучение в другой. Наконец, оценки от текстовой и визуальной ветвей усредняются для получения единого решения о настроении.
Тестирование подхода
Чтобы проверить работоспособность метода, исследователи испытывают его на трёх типах данных: фотографии ресторанов с сопутствующими характеристиками бизнеса, изображения продуктов Apple и небольшой коллекции твитов, содержащих и картинки, и текст. Они сравнивают свою гибридную систему с рядом современных конкурентов, включая модели на основе трансформеров, мультимодальные сети с вниманием и несколько существующих методов оптимизации. По таким метрикам, как точность, precision и F-мера, их подход систематически показывает лучшие результаты, часто с заметным отрывом. Он также быстрее сходится при обучении и сохраняет хорошую производительность даже при добавлении искусственного шума, что указывает на его эффективность и устойчивость.
Что это значит для повседневных технологий
Проще говоря, работа показывает, что компьютеры могут лучше улавливать наши онлайн‑чувства, когда они одновременно смотрят на то, что мы пишем, и на то, что мы показываем. За счёт тщательной очистки данных, разработки более насыщенных признаков и объединения двух специализированных нейронных движков со «смарт»-оптимизацией предложённый фреймворк уменьшает ошибки в распознавании настроений и повышает надежность предсказаний. Хотя текущая система фокусируется на тексте и изображениях, те же идеи можно расширить, включив тон голоса или видео, что откроет путь к будущим инструментам, которые будут понимать человеческие эмоции более естественно и обеспечивать более отзывчивые, персонализированные цифровые сервисы.
Цитирование: Vasanthi, P., Madhu Viswanatham, V. Multimodal sentiment analysis: hybrid classification model with image and text feature descriptors. Sci Rep 16, 13987 (2026). https://doi.org/10.1038/s41598-026-42912-2
Ключевые слова: мультимодальный анализ настроений, эмоции в социальных сетях, слияние изображения и текста, глубокий классификатор, оптимизация признаков