Clear Sky Science · zh
通过分层秩取样改进逻辑回归分类:来自模拟与真实应用的见解
更聪明的抽样以提升健康预测
当医生和医院利用数据预测谁可能罹患某种疾病时,往往依赖像逻辑回归这样的机器学习工具。但在幕后,这些工具的性能受限于我们提供的数据。本研究提出了一个简单却有力的问题:与其纯粹随机抽取患者,不如更聪明地选择样本——尤其是那些罕见的高风险个体——是否能使我们的预测模型更精准且更高效?
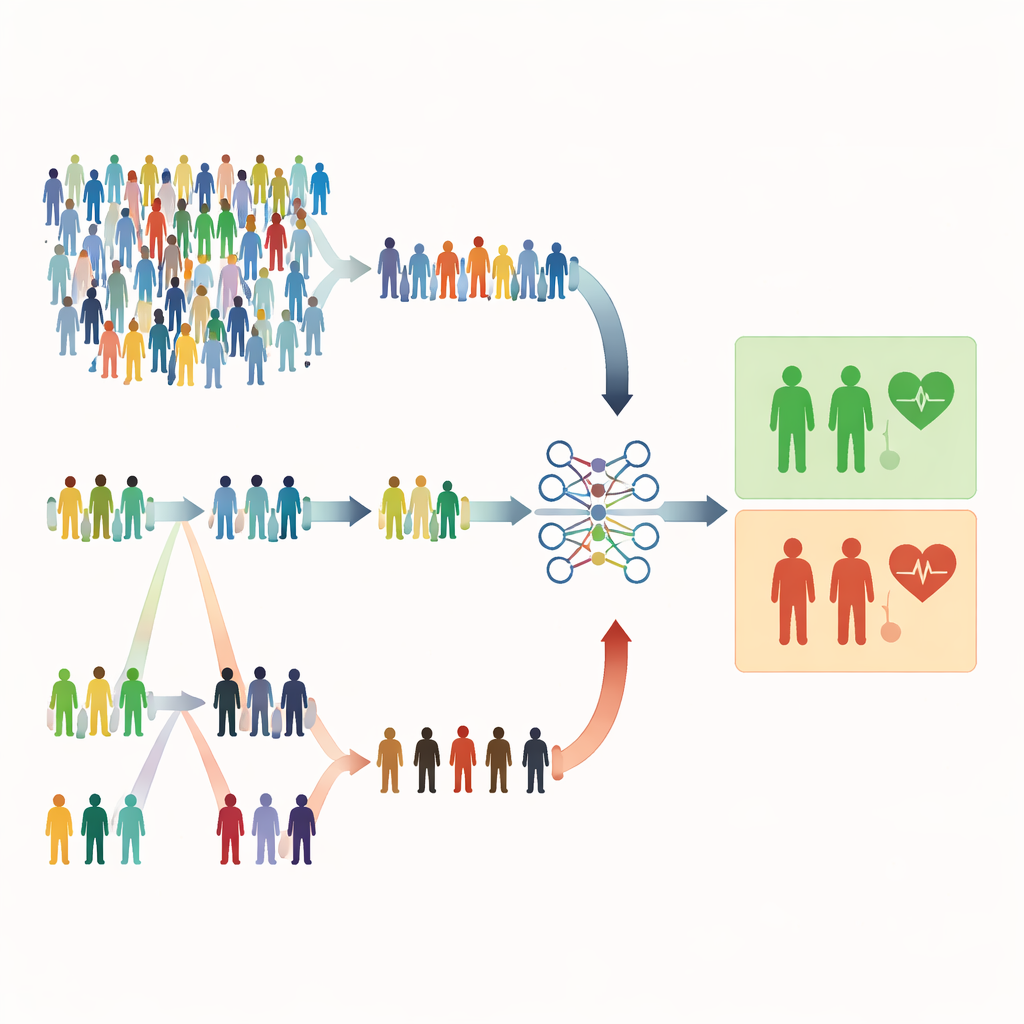
为何普通随机抽取可能不足
多数医学研究仍依赖简单随机抽样,每个人被抽中的概率相同。表面上这很公平,但也可能浪费资源。当严重疾病很少见时,随机抽样可能主要包含健康个体,而高风险患者太少。这削弱了模型识别危险信号的能力,并可能迫使研究者招募更多样本,从而增加时间、金钱和人力成本。本文作者认为,许多健康研究中已有廉价且易测的线索——如年龄、化验数值或症状评分——可用于引导更智能的抽样,而无需增加所测人数。
按秩次而非纯随机选择
研究关注秩式抽样方法,这类方法先用一个快速、廉价的指标对个体进行排序,然后再做完整而昂贵的测量。在秩样本抽样(RSS)中,人们被分成小组,并按诸如症状严重程度或筛查评分等简单指标排序。从每组中,选择具有特定秩次的人(例如第二高)进行详细测量。极端秩样本抽样(ERSS)更进一步:它刻意从每组中选择极端个体——最低与最高值,有时也包括中位——以丰富样本中的异常或边界病例。这些极端值往往包括在纯随机样本中罕见但真正处于高风险的患者。
用虚拟与真实患者检验想法
为了评估这些策略对逻辑回归的影响,研究者进行了大量计算机模拟。他们构建了不同总体大小、样本量和类别不平衡程度(从平衡到稀有事件)的人工人群,并改变廉价排序变量与真实结果的相关强度。在每种设定下,他们使用三种设计构建预测模型:简单随机抽样、经典秩样本抽样和极端秩样本抽样。评估指标包括准确率、ROC 曲线下面积、F1 分数和 Matthews 相关系数等标准度量。随后,他们在两个真实数据集中验证这些模式:一个用于骨质疏松预测,另一个用于评估母体健康风险,其中年龄或体质指数等变量作为自然的排序工具。
强调极端值时的结果
结果表现出高度一致性。标准 RSS 通常与随机抽样表现相近,改进有限;而 ERSS 则常常带来明显收益,特别是在排序变量与结果具有中等或强相关且组内人数(即一组被排序的人数)较大时。当组大小为五或十时,ERSS 经常产生更高的准确率、更清晰的高低风险分离,以及更强的少数类检测能力,即使训练样本仅为 60 或 120 人。在许多模拟情景中,ERSS 的性能指标接近或超过 0.95。关键在于总体规模的增加影响不大;决定性的是样本如何被选择。在骨质疏松和母体健康数据集中,只要存在信息量相当的排序变量,ERSS 同样提升了逻辑回归的表现。
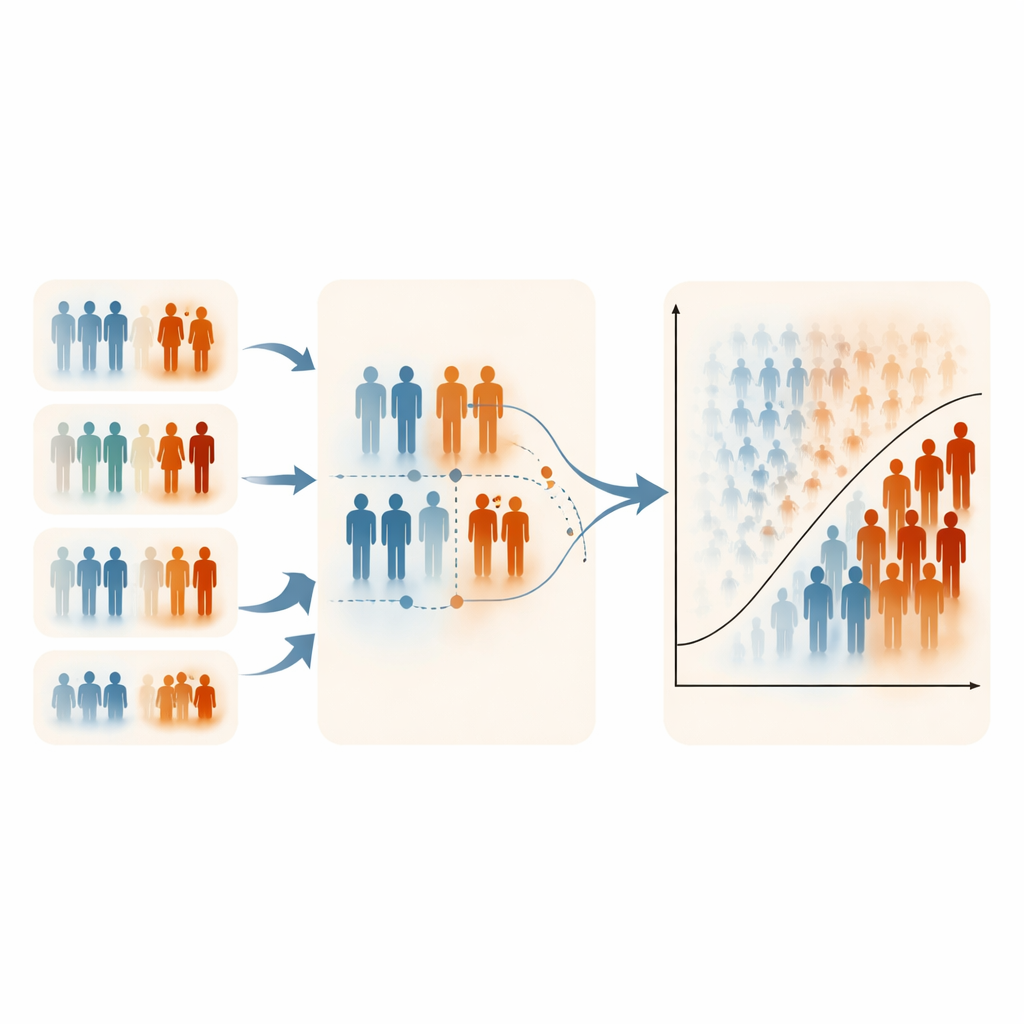
局限、权衡与实际应用
作者指出,ERSS 依赖至少有一个实用且有信息量的排序变量;没有这样的变量,方法的优势会消失。他们的模拟也主要关注中等程度的类别不平衡,因为在严格控制患病率与相关结构的同时模拟极端罕见事件较为困难。在某些高度偏斜的情形中,ERSS 会略微降低特异性(正确识别健康个体),这反映了其刻意强调高风险个体的策略。尽管如此,各抽样设计的计算时间相似,逻辑回归得到的参数估计保持稳定且无偏,表明这些更聪明的样本并不会扭曲潜在的医学关系。
这对未来医学研究的意义
简而言之,该研究表明,选择测量哪些患者与选择运行哪种预测算法同样重要。通过使用 ERSS 有意过采样极端或边界病例,研究者能为逻辑回归模型提供关于风险端更丰富的信息,从而在不增加总体测量人数的情况下改善对平衡与不平衡数据集的预测。对于面临资源有限且结果罕见但关键的健康研究者来说,ERSS 提供了一种实用方法,让每一个被测患者都更有价值,可能带来更早的发现、更有针对性的干预以及更可靠的决策支持工具。
引用: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
关键词: 逻辑回归, 秩样本抽样, 不平衡数据, 医学风险预测, 抽样设计