Clear Sky Science · nl
Verbetering van logistieke regressieclassificatie: inzichten uit simulatie en praktijktoepassingen via ranked set sampling
Slimmere bemonstering voor betere gezondheidsvoorspellingen
Wanneer artsen en ziekenhuizen data gebruiken om te voorspellen wie een ziekte kan ontwikkelen, vertrouwen ze vaak op machine-learninghulpmiddelen zoals logistieke regressie. Maar achter de schermen zijn deze hulpmiddelen slechts zo goed als de data die we erin stoppen. Deze studie stelt een eenvoudige maar krachtige vraag: in plaats van patiënten louter willekeurig te kiezen, kunnen we ze slimmer selecteren—met name de zeldzame, hoog‑risicogevallen—zodat onze voorspellingsmodellen zowel scherper als efficiënter worden?
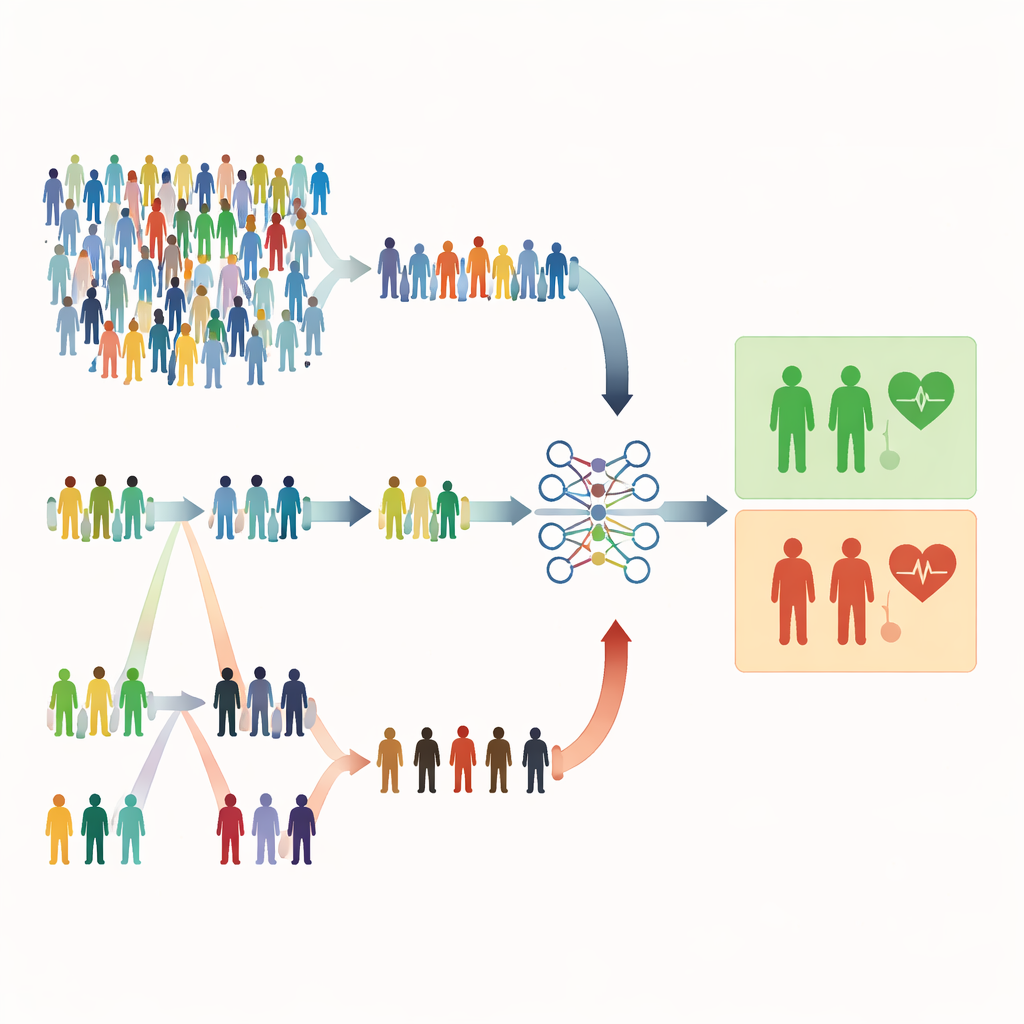
Waarom gewone willekeurige selectie tekort kan schieten
De meeste medische studies vertrouwen nog steeds op eenvoudige willekeurige steekproeftrekking, waarbij iedereen dezelfde kans heeft om geselecteerd te worden. Dat klinkt eerlijk, maar het kan verspilling opleveren. Wanneer ernstige aandoeningen zeldzaam zijn, kan een willekeurige trekking vooral gezonde mensen omvatten en te weinig hoog‑risicopatiënten. Dat verzwakt het vermogen van het model om waarschuwingssignalen te herkennen en kan onderzoekers dwingen veel grotere steekproeven te werven, wat meer tijd, geld en inspanning kost. De auteurs van dit artikel beargumenteren dat we in veel gezondheidsonderzoeken al goedkope, gemakkelijk meetbare aanwijzingen hebben—zoals leeftijd, laboratoriumwaarden of symptoomscores—die een slimmere bemonstering kunnen sturen zonder het aantal gemeten personen te verhogen.
Kiezen op volgorde in plaats van puur toeval
De studie richt zich op ranggebaseerde bemonstermethoden die een snelle, goedkope indicator gebruiken om individuen te rangschikken voordat de volledige, kostbare metingen worden gedaan. Bij ranked set sampling (RSS) worden mensen in kleine groepen verdeeld en op volgorde gezet op basis van een eenvoudige markeerder zoals ernst van symptomen of een screeningsscore. Uit elke groep wordt één persoon met een bepaalde rang (bijvoorbeeld de op één na hoogste) gekozen voor gedetailleerde meting. Extreme ranked set sampling (ERSS) gaat een stap verder: het selecteert opzettelijk mensen aan de uitersten van elke groep—de laagste en hoogste waarden, en soms het midden—waardoor de steekproef wordt verrijkt met ongebruikelijke of grensgevallen. Deze uitersten bevatten vaak juist de patiënten die echt risico lopen maar zeldzaam zouden zijn in een puur willekeurige steekproef.
De idee testen met virtuele en echte patiënten
Om te zien hoe deze strategieën de logistieke regressie beïnvloeden, voerden de onderzoekers uitgebreide computersimulaties uit. Ze creëerden kunstmatige populaties met verschillende groottes, steekproefgroottes en graden van klasse-ongelijkheid (van evenwichtige uitkomsten tot zeldzame gebeurtenissen), en varieerden hoe sterk de goedkope rangvariabele met de werkelijke uitkomst samenhing. Voor elke situatie bouwden ze voorspellingsmodellen met drie ontwerpen: eenvoudige willekeurige steekproeftrekking, klassieke ranked set sampling en extreme ranked set sampling. Ze beoordeelden de prestaties met standaardmaatstaven zoals nauwkeurigheid, area under the ROC-curve, F1-score en Matthews correlatiecoëfficiënt. Vervolgens controleerden ze of de patronen standhielden in de praktijk met twee echte datasets: één voor het voorspellen van osteoporose en een andere voor het beoordelen van maternale gezondheidsrisico's, waarbij variabelen als leeftijd of body-mass index als natuurlijke rangschikkingshulpmiddelen werden gebruikt.
Wat er gebeurde toen uitersten werden benadrukt
De resultaten waren opvallend consistent. Standaard RSS presteerde meestal ongeveer even goed als willekeurige steekproeftrekking en bood weinig verbetering in classificatie. ERSS bood daarentegen vaak duidelijke voordelen, vooral wanneer de rangvariabele matig tot sterk gerelateerd was aan de uitkomst en wanneer de setgrootte (het aantal mensen dat samen wordt gerangschikt) groter was. Bij setgroottes van vijf of tien leverde ERSS vaak hogere nauwkeurigheid, betere scheiding tussen hoog‑ en laagrisicogroepen en sterkere detectie van de minderheidsklasse, zelfs wanneer slechts 60 of 120 patiënten voor training werden gebruikt. In veel gesimuleerde scenario's benaderden of overschreden de prestatie‑indicatoren voor ERSS 0,95. Cruciaal was dat het vergroten van de totale populatiegrootte weinig effect had; wat telde was hoe de steekproef werd gekozen. In de datasets voor osteoporose en maternale gezondheid verbeterde ERSS opnieuw de prestaties van logistieke regressie telkens wanneer een redelijk informatieve rangvariabele beschikbaar was.
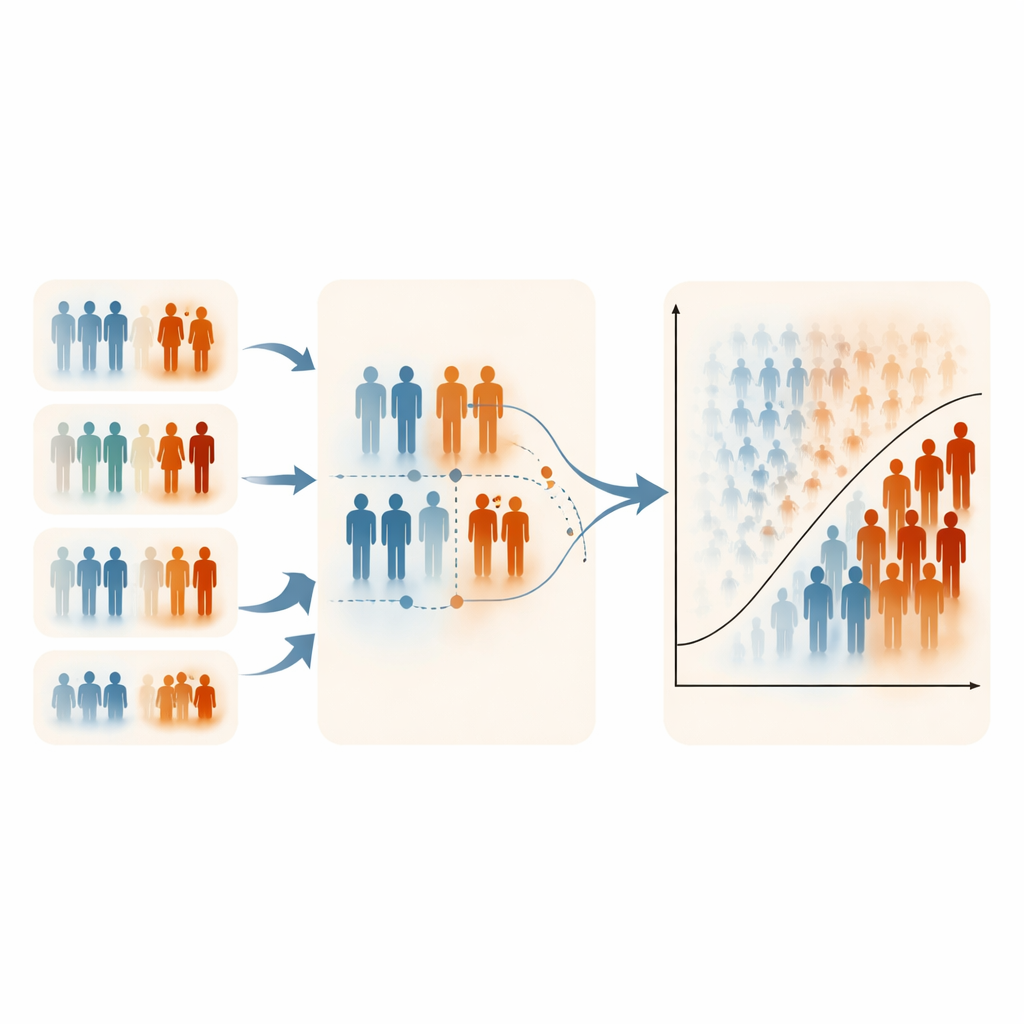
Beperkingen, afwegingen en praktisch gebruik
De auteurs merken op dat ERSS afhankelijk is van het hebben van ten minste één praktische, informatieve variabele voor rangschikking; zonder zo’n variabele verliest de methode haar voordeel. Hun simulaties richtten zich ook op matige niveaus van klasse-ongelijkheid, omdat extreem zeldzame uitkomsten moeilijk te simuleren zijn terwijl zowel prevalentie als correlatiestructuren zorgvuldig worden gecontroleerd. In sommige sterk scheve situaties verminderde ERSS de specificiteit (het correct classificeren van gezonde individuen) iets, wat de bedoeling weerspiegelt om hoog‑risicogevallen extra te benadrukken. Desalniettemin waren de rekentijden vergelijkbaar voor alle bemonsteringsontwerpen en bleven parameterinschattingen van de logistieke regressie stabiel en ongedeeld, wat suggereert dat deze slimmere steekproeven de onderliggende medische relaties niet vervormen.
Wat dit betekent voor toekomstige medische studies
In eenvoudige bewoordingen laat de studie zien dat het kiezen welke patiënten te meten net zo belangrijk kan zijn als het kiezen welk voorspellingsalgoritme te gebruiken. Door doelbewust extreme of grensgevallen te oversamplen met ERSS, kunnen onderzoekers logistieke regressiemodellen een rijker beeld geven van het risicovolle uiteinde van het spectrum, waarmee voorspellingen verbeteren voor zowel evenwichtige als onevenwichtige datasets zonder meer gegevens te verzamelen. Voor gezondheidsonderzoekers met beperkte middelen en zeldzame maar kritieke uitkomsten biedt ERSS een praktische manier om van elke gemeten patiënt meer waarde te maken, wat mogelijk leidt tot eerdere detectie, beter gerichte interventies en betrouwbaardere decision-supporttools.
Bronvermelding: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
Trefwoorden: logistieke regressie, ranked set sampling, onevenwichtige gegevens, medische risicovoorspelling, steekproefontwerp