Clear Sky Science · sv
Förbättrad logistisk regressionsklassificering: insikter från simuleringar och verkliga tillämpningar genom rankordnad urvalsampling
Smartare urval för bättre hälsoprediktioner
När läkare och sjukhus använder data för att förutse vem som kan utveckla en sjukdom förlitar de sig ofta på maskininlärningsverktyg som logistisk regression. Men bakom kulisserna är dessa verktyg bara så bra som de data vi matar dem med. Denna studie ställer en enkel men kraftfull fråga: i stället för att välja patienter helt slumpmässigt, kan vi välja dem mer klokt—särskilt de sällsynta, högriskfallen—så att våra prediktionsmodeller blir både skarpare och mer effektiva?
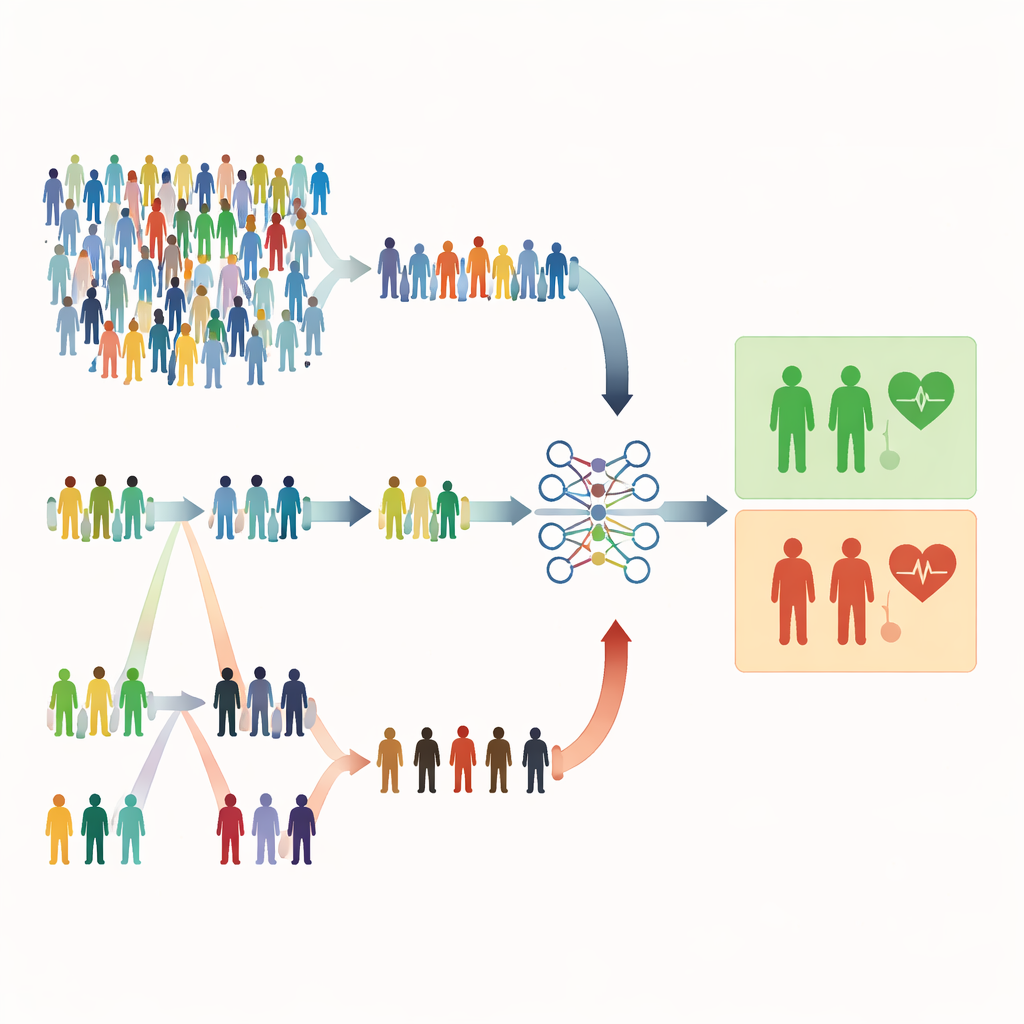
Varför vanliga slumpurval kan vara otillräckliga
De flesta medicinska studier förlitar sig fortfarande på enkelt slumpurval, där varje person har samma sannolikhet att bli vald. Det låter rättvist, men kan vara slösaktigt. När allvarliga tillstånd är sällsynta kan ett slumpmässigt urval bestå mestadels av friska personer och för få högriskpatienter. Det försvagar modellens förmåga att känna igen varningstecken och kan tvinga forskare att rekrytera mycket större urval, vilket kostar mer tid, pengar och ansträngning. Artikelförfattarna menar att många hälsostudier redan har billiga, lättmätta ledtrådar—som ålder, labbvärden eller symtompoäng—som kan vägleda smartare urval utan att öka antalet personer vi mäter.
Välja efter ordning i stället för ren slump
Studien fokuserar på rankbaserade urvalsmetoder som använder en snabb, billig indikator för att rangordna individer innan de görs fullständiga, kostsamma mätningar. I rankordnad urvalsampling (RSS) delas personer in i små grupper och ordnas efter en enkel markör såsom symtomsvårighetsgrad eller ett screeningspoäng. Från varje grupp väljs en person med en viss rang (till exempel den näst högsta) för detaljerade mätningar. Extrem rankordnad urvalsampling (ERSS) går steget längre: den väljer medvetet personer i extremområdena i varje grupp—de lägsta och högsta värdena, och ibland mitten—vilket berikar provet med ovanliga eller gränsfall. Dessa extremfall innefattar ofta just de patienter som är i verklig risk men som skulle vara sällsynta i ett rent slumpurval.
Testa idén med virtuella och verkliga patienter
För att se hur dessa strategier påverkar logistisk regression genomförde forskarna omfattande datorsimuleringar. De skapade artificiella populationer med olika storlekar, provstorlekar och grader av klassobalans (från balanserade utfall till sällsynta händelser), och varierade hur starkt den billiga rankningsvariabeln var relaterad till det verkliga utfallet. För varje inställning byggde de prediktionsmodeller med tre designer: enkelt slumpurval, klassisk rankordnad urvalsampling och extrem rankordnad urvalsampling. De bedömde prestanda med standardmått såsom noggrannhet, area under ROC-kurvan, F1‑poäng och Matthews korrelationskoefficient. De kontrollerade sedan om mönstren höll i praktiken genom att använda två verkliga dataset: ett som förutsäger osteoporos och ett annat som bedömer maternell hälsorisk, där variabler som ålder eller BMI fungerade som naturliga rankningsverktyg.
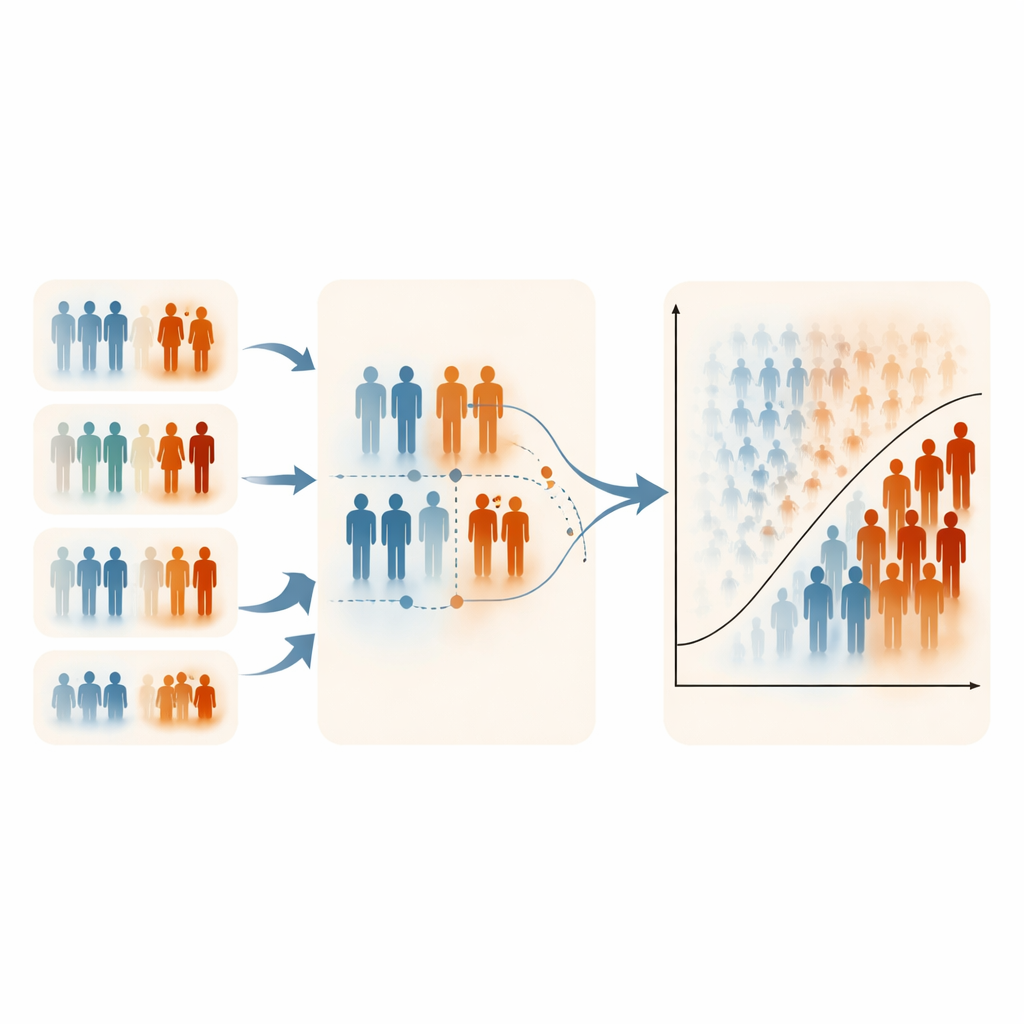
Vad som hände när extremvärden betonades
Resultaten var slående konsekventa. Standard-RSS presterade vanligtvis ungefär lika bra som slumpurval och gav liten förbättring i klassificering. ERSS gav däremot ofta tydliga vinster, särskilt när rankningsvariabeln var måttligt eller starkt relaterad till utfallet och när setstorleken (antalet personer som rangordnas tillsammans) var större. Med setstorlekar på fem eller tio gav ERSS ofta högre noggrannhet, bättre separation mellan högrisk‑ och lågriskfall och starkare upptäckt av minoritetsklassen, även när endast 60 eller 120 patienter användes för träning. I många simulerade scenarier närmade sig eller översteg prestationsmåtten för ERSS 0,95. Av central betydelse påverkade inte en ökad total populationsstorlek nämnvärt; det viktiga var hur provet valdes. I datasetten för osteoporos och maternell hälsa förbättrade ERSS återigen logistisk regressionsprestanda när en rimligt informativ rankningsvariabel fanns tillgänglig.
Begränsningar, avvägningar och praktisk användning
Författarna påpekar att ERSS förutsätter att det finns åtminstone en praktisk, informativ variabel för rangordning; utan en sådan förlorar metoden sin fördel. Deras simuleringar fokuserade också på måttliga nivåer av klassobalans, eftersom extremt sällsynta utfall är svåra att simulera samtidigt som man noggrant kontrollerar både förekomst och korrelationsstrukturer. I vissa starkt snedfördelade situationer minskade ERSS något specificiteten (att korrekt klassificera friska individer), vilket speglar dess avsiktliga fokus på högriskfall. Trots detta var beräkningstiderna likartade över alla urvalsdesigner, och parameteruppskattningarna från logistisk regression förblev stabila och obiaserade, vilket tyder på att dessa smartare urval inte förvränger de underliggande medicinska sambanden.
Vad detta betyder för framtida medicinska studier
Enkelt uttryckt visar studien att valet av vilka patienter som mäts kan vara lika viktigt som valet av vilken prediktionsalgoritm som används. Genom att med avsikt översampelera extrema eller gränsfall med ERSS kan forskare ge logistiska regressionsmodeller en rikare bild av den riskfyllda delen av spektrumet, förbättra prediktioner för både balanserade och obalanserade dataset utan att samla in fler data totalt. För hälsoresearchers med begränsade resurser och sällsynta men kritiska utfall erbjuder ERSS ett praktiskt sätt att få varje mätt patient att betyda mer, vilket potentiellt leder till tidigare upptäckt, bättre riktade interventioner och mer tillförlitliga beslutsstödsverktyg.
Citering: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
Nyckelord: logistisk regression, rankordnad urvalsampling, obalanserade data, medicinsk riskprediktion, urvalsdesign