Clear Sky Science · ja
ロジスティック回帰分類を強化する:ランク付き集合標本抽出によるシミュレーションと実データ応用からの洞察
より賢いサンプリングで健康予測を高める
医師や病院が誰が病気を発症する可能性があるかを予測する際、しばしばロジスティック回帰のような機械学習手法に頼ります。しかし、その性能は与えられるデータの質に左右されます。本研究は単純だが強力な問いを投げかけます。患者を完全にランダムに選ぶ代わりに、特に稀で高リスクのケースをより巧妙に選べば、予測モデルはより鋭く、より効率的になるのではないか、ということです。
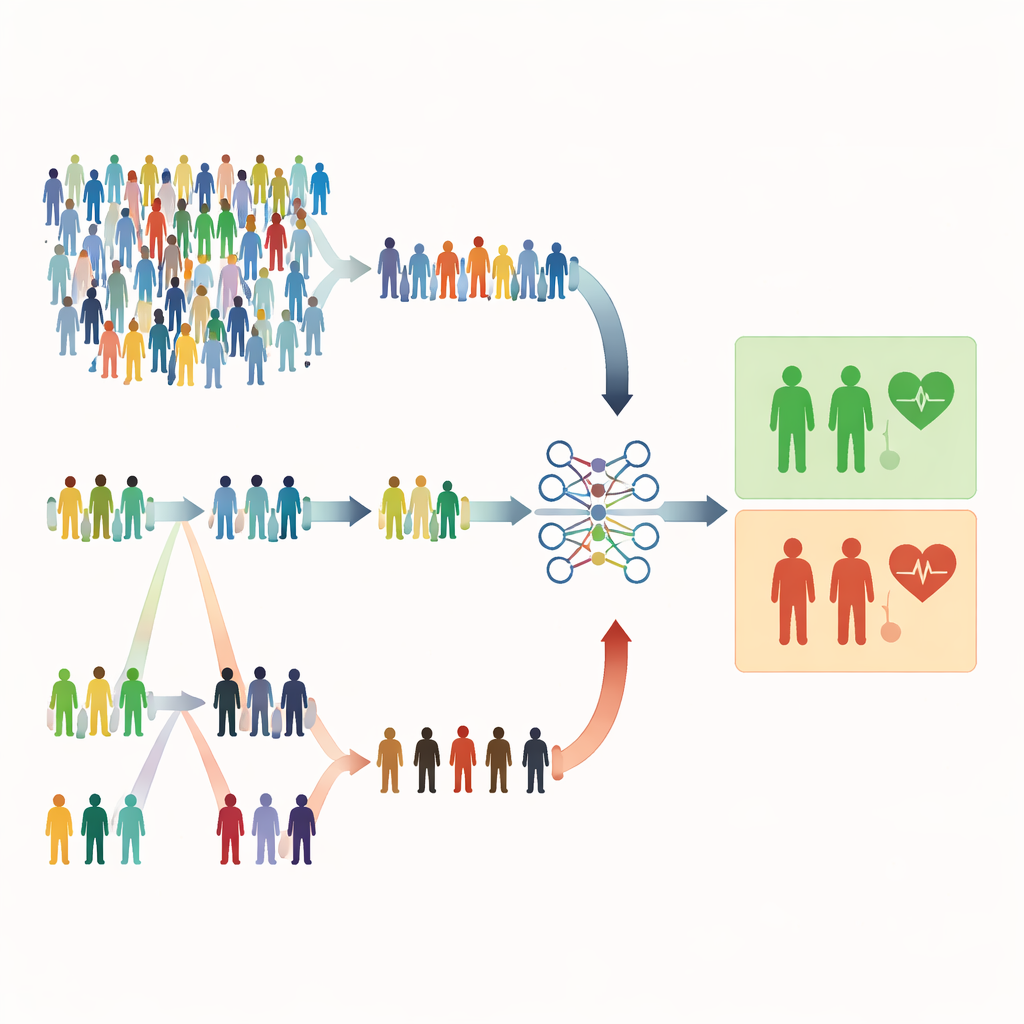
なぜ単純な無作為抽出だけでは不十分なのか
多くの医療研究は依然として、すべての人に同じ抽出確率を与える単純無作為抽出に依存しています。それは公平に聞こえますが、非効率になることがあります。重篤な疾患が稀な場合、無作為抽出では大半が健康な人になり、高リスク患者がほとんど含まれないことがあります。これではモデルが警告サインを学習しにくく、研究者はより大きなサンプルを集める必要に迫られ、時間や費用、労力が増します。本稿の著者らは、多くの健康研究で年齢や検査値、症状スコアなどの廉価で簡単に測れる手がかりが既に存在し、それらを利用すれば測定する人数を増やさずに賢いサンプリングができると主張します。
純粋な偶然ではなく順位で選ぶ
本研究は、簡便で安価な指標で個人を順位付けしてから本格的な高価な測定を行うランクベースのサンプリング手法に焦点を当てています。ランク付き集合標本抽出(RSS)では、人々を小さなグループに分け、症状の重さやスクリーニングスコアなどの簡単な指標で順序付けします。各グループから特定の順位(例えば上から2番目)の人を詳細測定のために選びます。極端ランク付き集合標本抽出(ERSS)はさらに踏み込み、各グループの極端値—最小値と最大値、場合によっては中央値—を意図的に選ぶことで、サンプルを異常値や境界ケースで濃縮します。これらの極端なケースには、純粋な無作為抽出では稀である本当にリスクの高い患者が含まれていることが多いのです。
仮想患者と実患者で検証する
これらの戦略がロジスティック回帰にどのように影響するかを調べるため、研究者らは大規模なコンピュータシミュレーションを実施しました。彼らはさまざまな母集団サイズ、サンプルサイズ、クラス不均衡の程度(均衡な結果から稀な事象まで)をもつ人工集団を作成し、廉価なランク変数が真のアウトカムとどれほど関連しているかを変化させました。各条件で、単純無作為抽出、古典的なRSS、極端RSSの三つの設計で予測モデルを構築しました。性能評価は精度、ROC曲線下面積、F1スコア、Matthews相関係数といった標準的指標を用いて行われました。さらに、骨粗鬆症予測と母体健康リスク評価という二つの実データセットを用い、年齢やBMIのような変数を自然なランキング指標として使える場面で、パターンが実際にも当てはまるかを確認しました。
極端値を重視したときに起きたこと
結果は一貫して際立っていました。標準的なRSSは通常、無作為抽出と同程度の性能で、分類の改善は限定的でした。しかしERSSはしばしば明確な利得をもたらしました。特にランク変数が中程度から強くアウトカムに関連し、セットサイズ(同時に順位付けされる人数)が大きい場合に効果が顕著でした。セットサイズが5や10では、ERSSはしばしばより高い精度、高リスクと低リスクの分離、少数クラスの検出力向上を示し、訓練データが60人や120人でもその傾向が見られました。多くのシミュレーションシナリオで、ERSSの性能指標は0.95に近づくかそれを上回りました。重要なのは母集団全体のサイズではなく、どのようにサンプルを選ぶかでした。骨粗鬆症および母体健康のデータセットでも、十分に情報を与えるランク変数が利用できる場合、ERSSはロジスティック回帰の性能を改善しました。
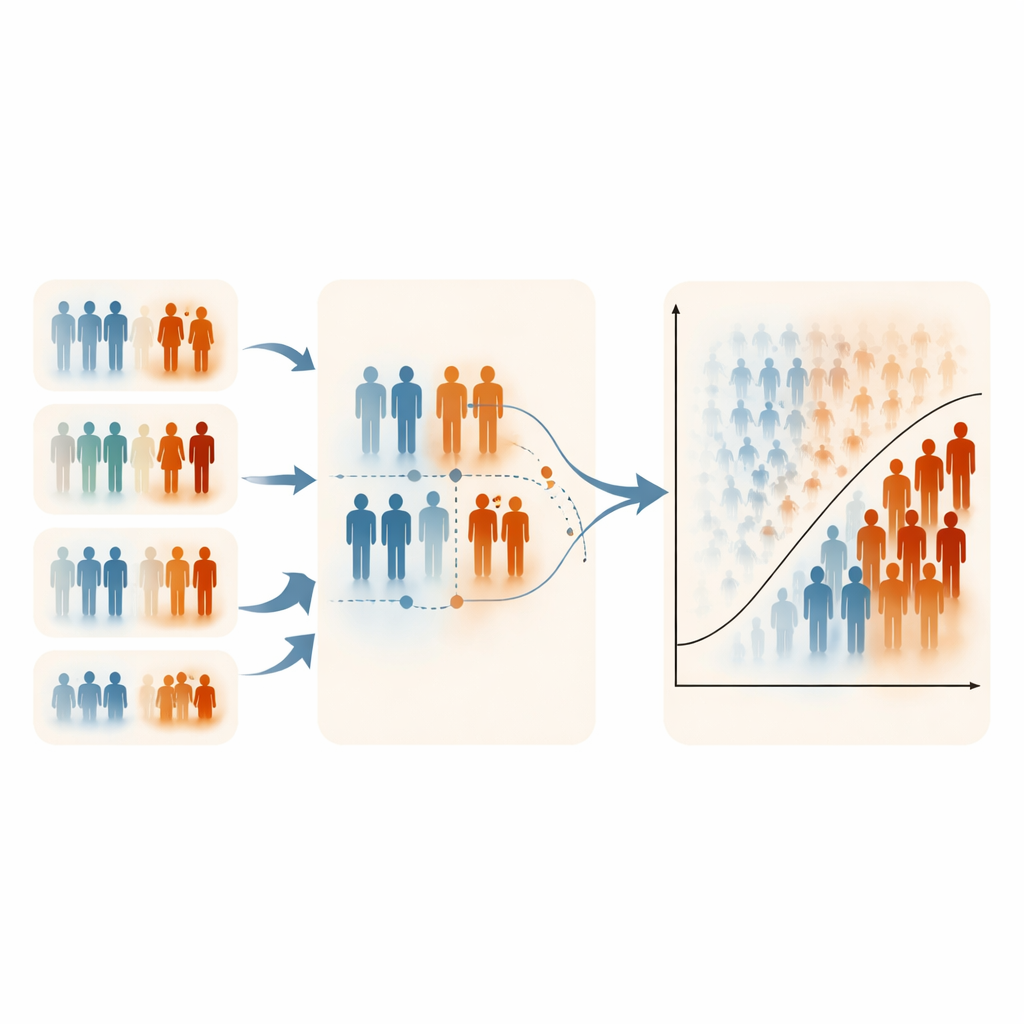
限界、トレードオフ、実用上の注意点
著者らは、ERSSは少なくとも一つの実用的で情報量のあるランク用変数があることに依存すると指摘します。そうした変数がなければ手法の優位性は失われます。また彼らのシミュレーションは中程度のクラス不均衡に焦点を当てており、極端に稀なアウトカムは有病率と相関構造の両方を慎重に制御しながらシミュレートするのが難しいため対象外でした。非常に歪んだ状況では、ERSSは特異度(健康な個体を正しく分類する能力)をわずかに低下させることがあり、これは高リスクケースを意図的に重視する設計の帰結です。それでも計算時間はすべてのサンプリング設計でほぼ同等であり、ロジスティック回帰のパラメータ推定は安定かつ不偏のままでした。つまり、これらの賢いサンプルが基礎となる医学的関係を歪めることはなさそうです。
今後の医療研究にとっての意義
平たく言えば、本研究はどの患者を測るかの選択が、どの予測アルゴリズムを使うかと同じくらい重要になり得ることを示しています。ERSSを使って極端あるいは境界のケースを意図的に過剰抽出することで、研究者はロジスティック回帰モデルにおいてリスクの高い領域をより豊かに示すことができ、追加のデータを集めることなく、均衡・不均衡を問わず予測を改善できます。限られた資源で希少だが重要な結果に対処する医療研究者にとって、ERSSは測定した各患者の価値を高め、早期発見、より適切な介入、信頼できる意思決定支援ツールにつながる実用的な手段を提供します。
引用: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
キーワード: ロジスティック回帰, ランク付き集合標本抽出, 不均衡データ, 医療リスク予測, サンプリング設計