Clear Sky Science · ru
Улучшение классификации логистической регрессии: результаты моделирования и практических приложений с помощью ранжированного комплектного отбора
Умный отбор для более точных медицинских прогнозов
Когда врачи и больницы используют данные для прогнозирования того, кто может заболеть, они часто опираются на инструменты машинного обучения, такие как логистическая регрессия. Но за этой техникой стоит простая истина: модели хороши только настолько, хороши данные, которыми их кормят. В этом исследовании поставлен простой, но важный вопрос: вместо того чтобы отбирать пациентов полностью случайно, нельзя ли выбирать их грамотнее — особенно редкие, высокорисковые случаи — чтобы сделать модели прогноза более точными и эффективными?
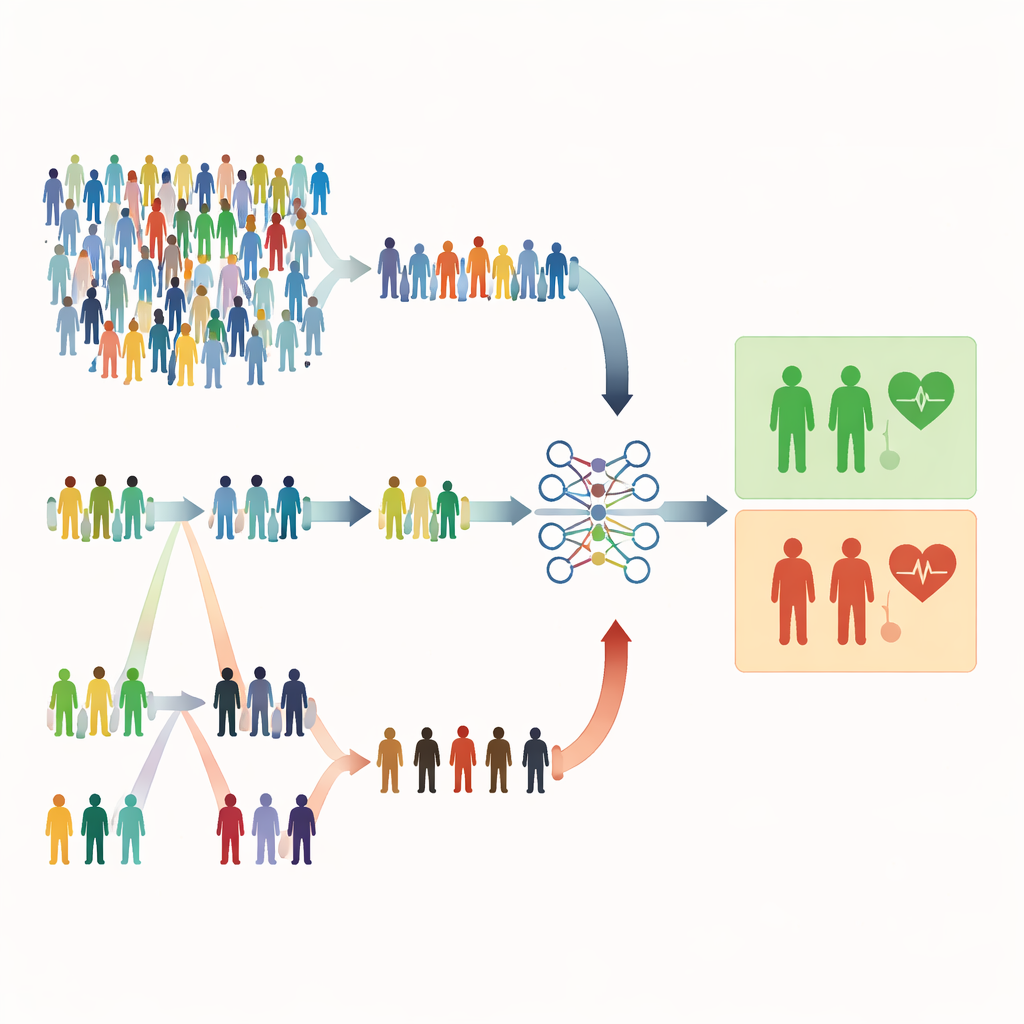
Почему обычная случайная выборка может не справляться
Большинство медицинских исследований по‑прежнему полагаются на простую случайную выборку, когда у каждого человека одинаковый шанс быть выбранным. Это звучит справедливо, но может оказаться расточительным. Когда серьёзные состояния редки, случайная выборка может включать в основном здоровых людей и недостаточно много высокорисковых пациентов. Это снижает способность модели распознавать предупреждающие признаки и может заставить исследователей привлекать значительно большие выборки, что требует больше времени, денег и усилий. Авторы статьи утверждают, что во многих медицинских исследованиях уже имеются дешёвые, легко измеримые подсказки — например, возраст, лабораторные показатели или шкалы симптомов — которые можно использовать для более умного отбора, не увеличивая общего числа измерений.
Отбор по рангу вместо чистого случая
Исследование сосредоточено на методах отбора, основанных на ранжировании, которые используют быстрый и недорогой индикатор для упорядочивания людей перед проведением полных, дорогих измерений. В ранжированном комплектном отборе (RSS) люди делятся на небольшие группы и упорядочиваются по простому маркеру — например, по тяжести симптомов или результату скрининга. Из каждой группы выбирают одного человека с определённым рангом (например, второго по величине) для подробного измерения. Экстремальный ранжированный комплектный отбор (ERSS) идёт дальше: целенаправленно выбирают людей на крайних позициях каждой группы — с наименьшими и наибольшими значениями, а иногда и средними — обогащая выборку необычными или граничными случаями. Такие крайности часто включают именно тех пациентов, которые действительно находятся в группе риска, но были бы редкостью при чисто случайном отборе.
Проверка идеи на виртуальных и реальных пациентах
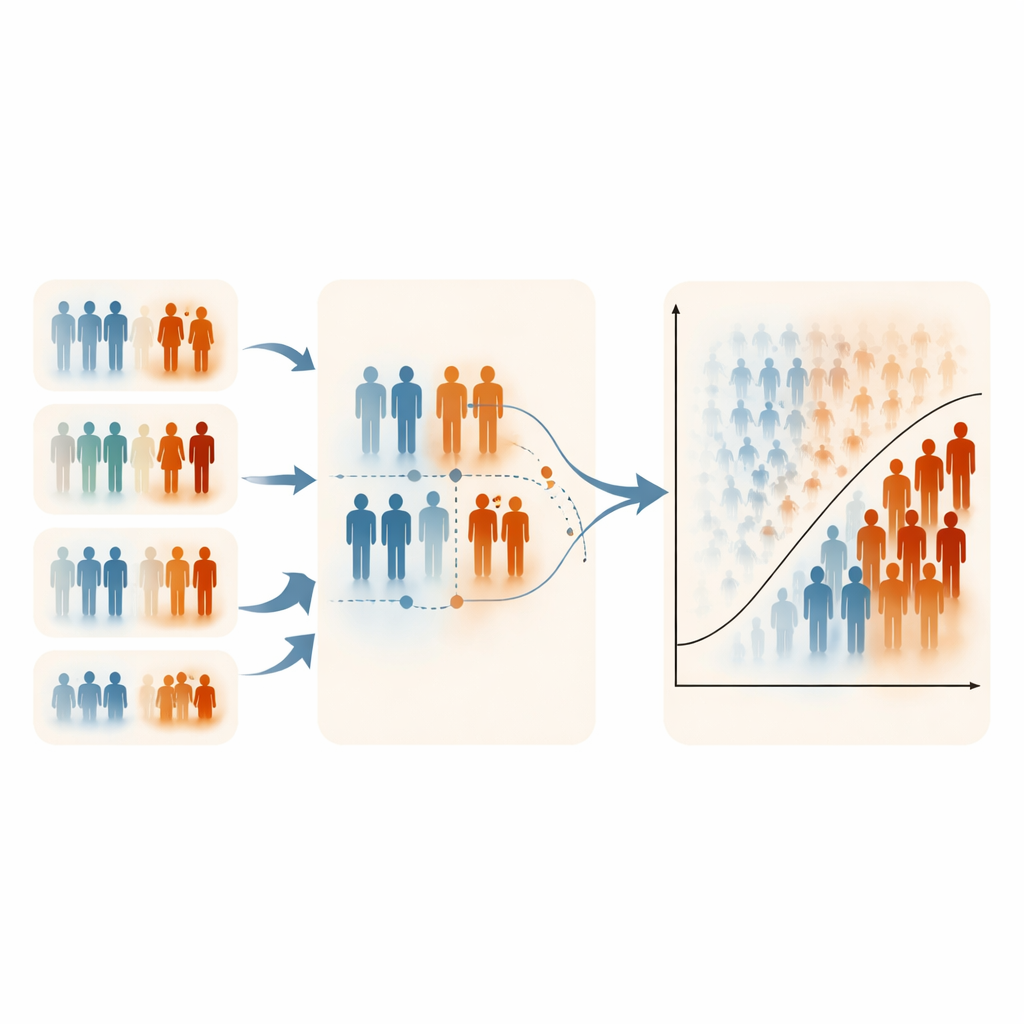
Чтобы оценить влияние этих стратегий на логистическую регрессию, исследователи провели масштабные компьютерные симуляции. Они создали искусственные популяции разных размеров, с разными размерами выборок и степенью дисбаланса классов (от сбалансированных исходов до редких событий), а также варьировали силу связи между дешёвым ранжирующим переменным и истинным исходом. Для каждой настройки они строили модели прогноза по трем схемам: простая случайная выборка, классический ранжированный комплектный отбор и экстремальный ранжированный комплектный отбор. Оценку производили по стандартным метрикам — точности, площади под ROC-кривой, F1‑мере и коэффициенту корреляции Мэттьюза. Затем они проверили, подтверждаются ли эти закономерности на практике, используя два реальных набора данных: один для прогнозирования остеопороза и другой для оценки материнского риска, где такие переменные, как возраст или индекс массы тела, служили естественными инструментами ранжирования.
Что случилось, когда сделали упор на крайности
Результаты оказались последовательными. Стандартный RSS обычно показывал результаты примерно на уровне случайной выборки и давал мало улучшений в классификации. ERSS, однако, часто обеспечивал заметный выигрыш, особенно когда ранжирующая переменная была умеренно или сильно связана с исходом и когда размер набора (число людей, ранжируемых вместе) был больше. При размерах наборов в пять или десять ERSS нередко давал более высокую точность, лучшую отделимость между высоко‑ и низкорисковыми случаями и более сильное обнаружение менее представленной (минорантной) категории, даже при использовании всего 60 или 120 пациентов для обучения. Во многих моделируемых сценариях показатели ERSS приближались к 0.95 или превосходили её. Важно, что увеличение общей численности популяции мало влияло на результаты; решало, как была отобрана выборка. В наборах данных по остеопорозу и материнскому здоровью ERSS снова улучшал работу логистической регрессии, когда имелась разумно информативная переменная для ранжирования.
Ограничения, компромиссы и практическое применение
Авторы отмечают, что ERSS зависит от наличия по крайней мере одной практичной, информативной переменной для ранжирования; без такой переменной метод теряет своё преимущество. Их симуляции также были сосредоточены на умеренных уровнях дисбаланса классов, поскольку крайне редкие исходы трудно адекватно смоделировать при одновременном тщательном контроле за распространённостью и структурами корреляции. В некоторых сильно скошенных настройках ERSS немного снижал специфичность (правильную классификацию здоровых людей), что отражает его целенаправленное внимание к высокорисковым случаям. Тем не менее время расчётов было сопоставимо для всех схем отбора, а оценки параметров логистической регрессии оставались стабильными и несмещёнными, что говорит о том, что такие умные выборки не искажают исходные медицинские взаимосвязи.
Что это значит для будущих медицинских исследований
Говоря просто, исследование показывает: выбор того, каких пациентов измерять, может быть не менее важен, чем выбор алгоритма прогноза. За счёт целенаправленного перепредставления крайних или граничных случаев с помощью ERSS исследователи могут дать моделям логистической регрессии более насыщенное представление об рискованном конце шкалы, улучшая прогнозы как для сбалансированных, так и для несбалансированных наборов данных, без увеличения общего объёма собираемых данных. Для медицинских исследователей с ограниченными ресурсами и при редких, но критических исходах ERSS предлагает практический способ сделать каждое измерение более информативным, что может привести к более раннему выявлению, точечным вмешательствам и более надёжным инструментам поддержки принятия решений.
Цитирование: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
Ключевые слова: логистическая регрессия, ранжированный комплектный отбор, несбалансированные данные, медицинское прогнозирование риска, дизайн выборки