Clear Sky Science · en
Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling
Smarter Sampling for Better Health Predictions
When doctors and hospitals use data to predict who might develop a disease, they often rely on machine-learning tools like logistic regression. But behind the scenes, these tools are only as good as the data we feed them. This study asks a simple but powerful question: instead of taking patients purely at random, can we choose them more cleverly—especially the rare, high‑risk cases—so that our prediction models become both sharper and more efficient?
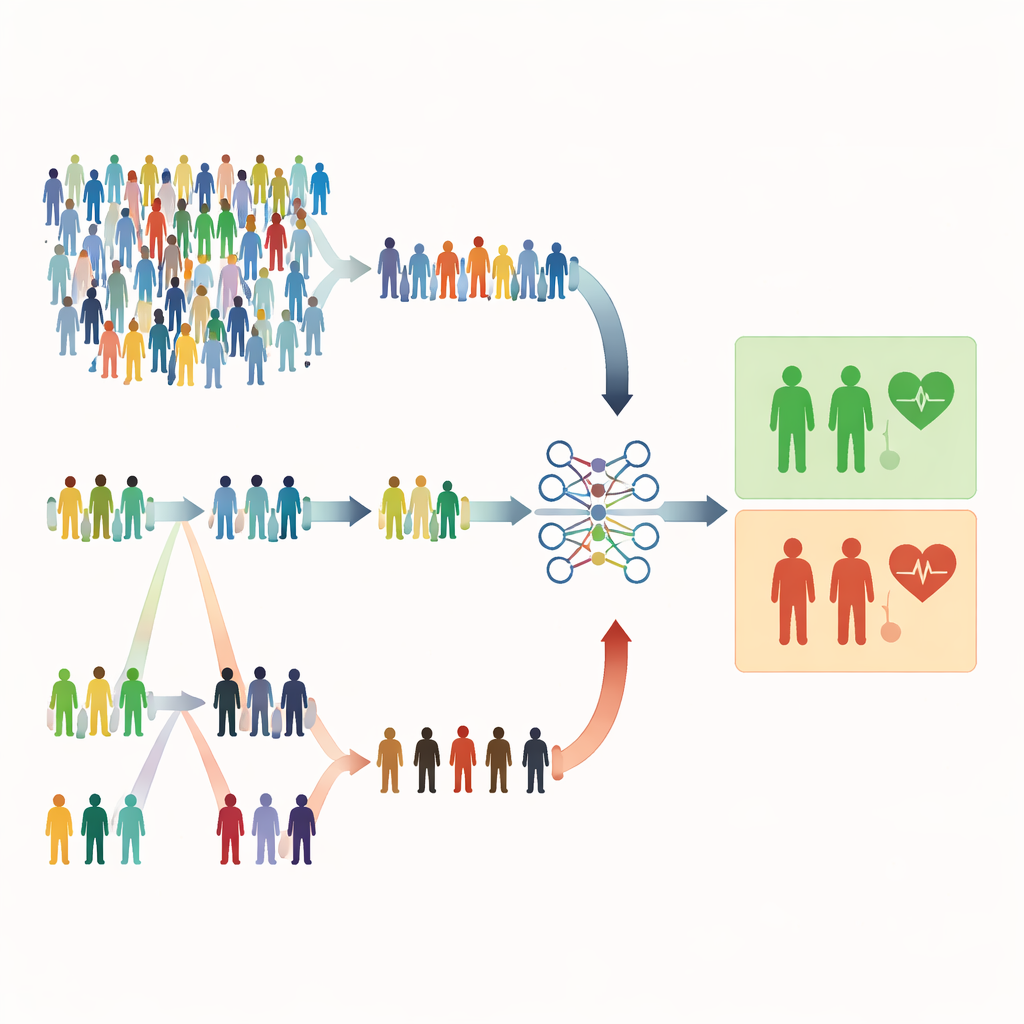
Why Ordinary Random Picks Can Fall Short
Most medical studies still rely on simple random sampling, where every person has the same chance of being picked. That sounds fair, but it can be wasteful. When serious conditions are rare, a random draw may include mostly healthy people and too few high‑risk patients. This weakens the model’s ability to recognize warning signs and can force researchers to recruit much larger samples, which costs more time, money, and effort. The authors of this paper argue that in many health studies we already have cheap, easily measured clues—like age, lab values, or symptom scores—that could guide smarter sampling without increasing the number of people we measure.
Picking by Order Instead of Pure Chance
The study focuses on rank‑based sampling methods that use a quick, inexpensive indicator to rank individuals before doing the full, costly measurements. In ranked set sampling (RSS), people are divided into small groups and ordered by a simple marker such as symptom severity or a screening score. From each group, one person with a particular rank (for example, the second‑highest) is chosen for detailed measurement. Extreme ranked set sampling (ERSS) goes a step further: it intentionally selects people at the extremes of each group—the lowest and highest values, and sometimes the middle—enriching the sample with unusual or boundary cases. These extremes often include the very patients who are at genuine risk but would be rare in a purely random sample.
Testing the Idea With Virtual and Real Patients
To see how these strategies affect logistic regression, the researchers ran extensive computer simulations. They created artificial populations with different sizes, sample sizes, and degrees of class imbalance (from balanced outcomes to rare events), and varied how strongly the cheap ranking variable was related to the true outcome. For each setting, they built prediction models using three designs: simple random sampling, classical ranked set sampling, and extreme ranked set sampling. They judged performance using standard measures such as accuracy, area under the ROC curve, F1‑score, and Matthews correlation coefficient. They then checked whether the patterns held up in practice using two real datasets: one predicting osteoporosis and another assessing maternal health risk, where variables like age or body‑mass index served as natural ranking tools.
What Happened When Extremes Were Emphasized
The results were strikingly consistent. Standard RSS usually performed about as well as random sampling, offering little improvement in classification. ERSS, however, often provided clear gains, especially when the ranking variable was moderately or strongly related to the outcome and when the set size (the number of people ranked together) was larger. With set sizes of five or ten, ERSS frequently produced higher accuracy, better separation between high‑ and low‑risk cases, and stronger minority‑class detection, even when only 60 or 120 patients were used for training. In many simulated scenarios, performance metrics for ERSS approached or exceeded 0.95. Crucially, increasing the overall population size had little effect; what mattered was how the sample was chosen. In the osteoporosis and maternal health datasets, ERSS again improved logistic regression performance whenever a reasonably informative ranking variable was available.
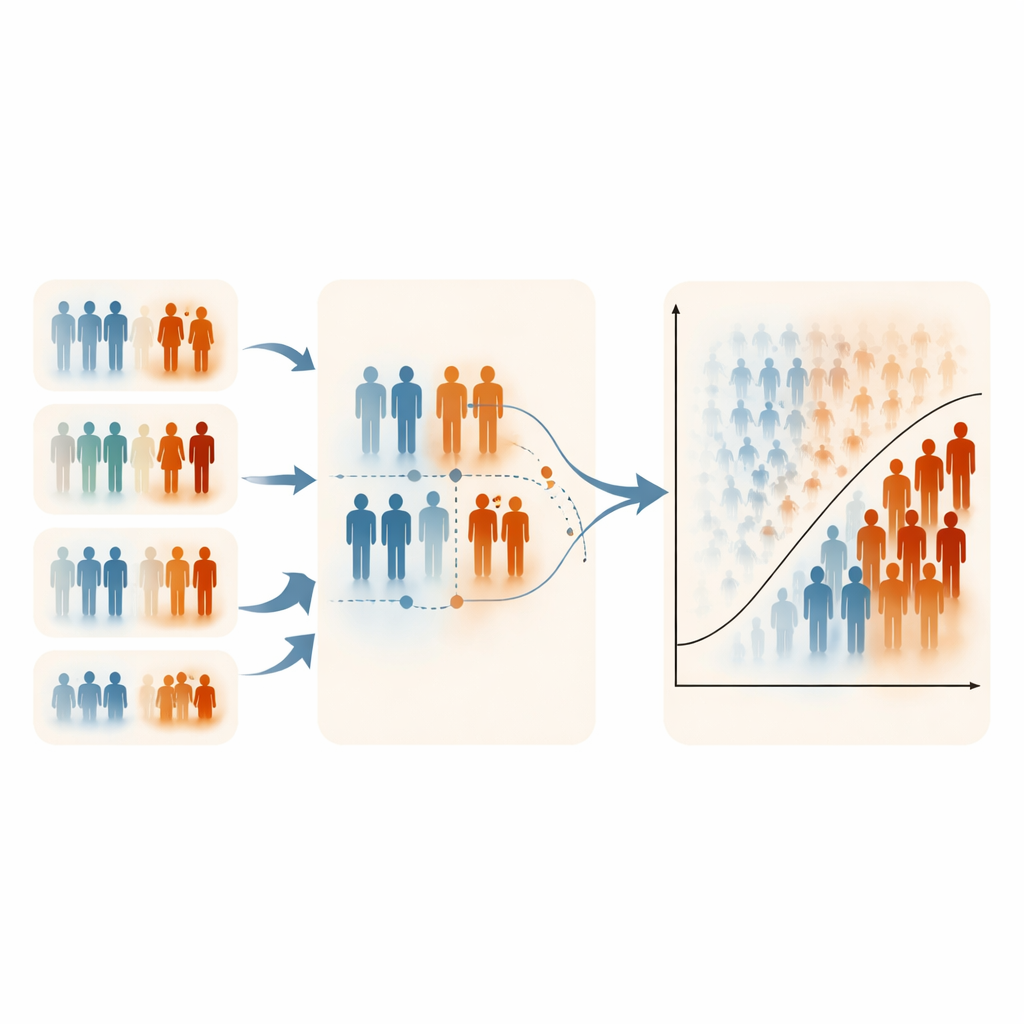
Limits, Trade‑Offs, and Practical Use
The authors note that ERSS depends on having at least one practical, informative variable for ranking; without it, the method loses its edge. Their simulations also focused on moderate levels of class imbalance, because extremely rare outcomes are difficult to simulate while carefully controlling both prevalence and correlation structures. In some highly skewed settings, ERSS slightly reduced specificity (correctly classifying healthy individuals), reflecting its deliberate emphasis on high‑risk cases. Nonetheless, computation times were similar across all sampling designs, and parameter estimates from logistic regression remained stable and unbiased, suggesting that these smarter samples do not distort the underlying medical relationships.
What This Means for Future Medical Studies
In plain terms, the study shows that choosing which patients to measure can be just as important as choosing which prediction algorithm to run. By deliberately oversampling extreme or boundary cases using ERSS, researchers can give logistic regression models a richer view of the risky end of the spectrum, improving predictions for both balanced and imbalanced datasets without collecting more data overall. For health researchers facing limited resources and rare but critical outcomes, ERSS offers a practical way to make every measured patient count more, potentially leading to earlier detection, better targeted interventions, and more reliable decision support tools.
Citation: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
Keywords: logistic regression, ranked set sampling, imbalanced data, medical risk prediction, sampling design