Clear Sky Science · fr
Améliorer la classification par régression logistique : enseignements issus de simulations et d’applications réelles via l’échantillonnage par ensembles ordonnés
Un échantillonnage plus malin pour de meilleures prédictions en santé
Lorsque médecins et hôpitaux s’appuient sur des données pour prédire qui pourrait développer une maladie, ils utilisent souvent des outils d’apprentissage automatique comme la régression logistique. Mais en coulisses, ces outils ne sont aussi bons que les données qui les alimentent. Cette étude pose une question simple mais puissante : au lieu de sélectionner les patients purement au hasard, peut‑on les choisir de façon plus intelligente — en particulier les cas rares et à haut risque — afin de rendre nos modèles de prédiction à la fois plus précis et plus efficients ?
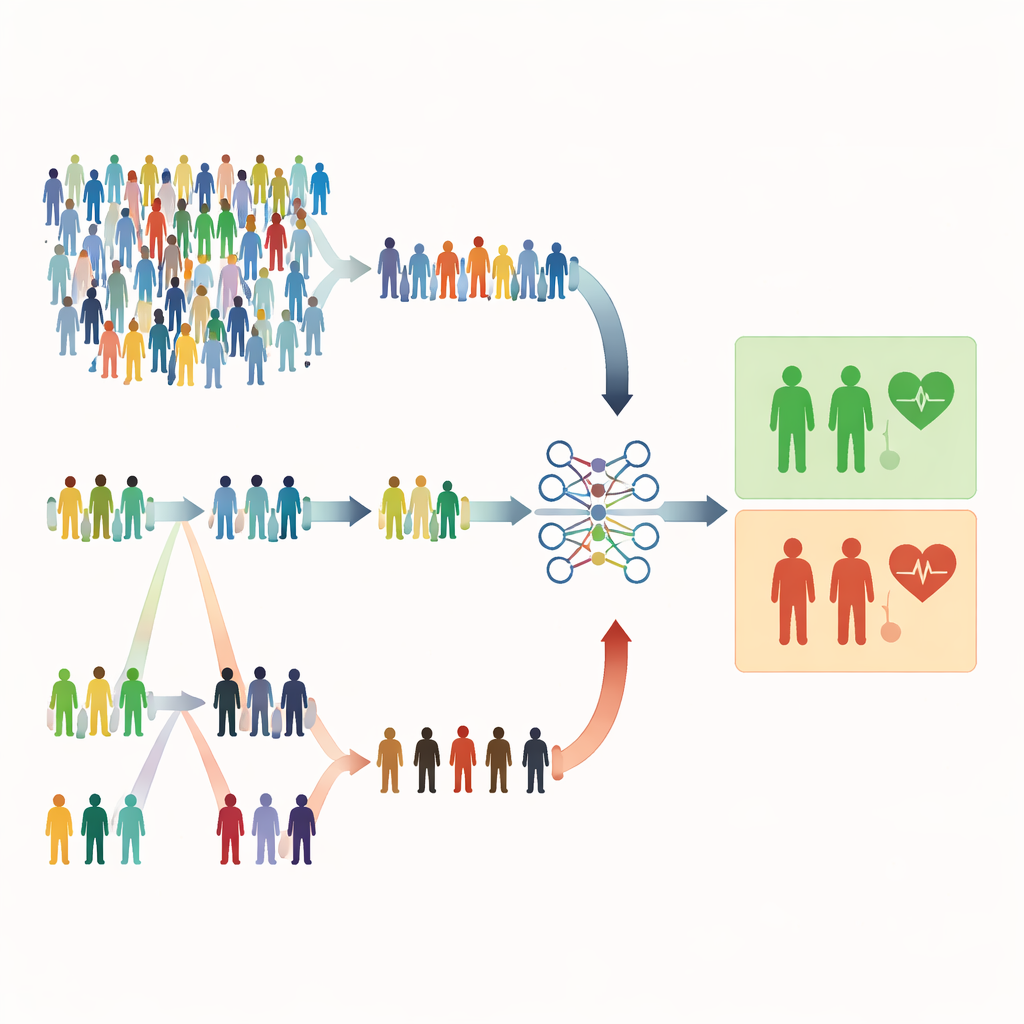
Pourquoi les tirages aléatoires ordinaires peuvent être insuffisants
La plupart des études médicales reposent encore sur l’échantillonnage aléatoire simple, où chaque personne a la même probabilité d’être sélectionnée. Cela semble juste, mais c’est parfois gaspilleur. Quand les affections graves sont rares, un tirage aléatoire peut inclure majoritairement des personnes en bonne santé et trop peu de patients à haut risque. Cela affaiblit la capacité du modèle à repérer les signaux d’alerte et peut contraindre les chercheurs à recruter des échantillons beaucoup plus grands, ce qui coûte plus de temps, d’argent et d’effort. Les auteurs soutiennent que dans de nombreuses études en santé, nous disposons déjà d’indices peu coûteux et faciles à mesurer — âge, valeurs biologiques ou scores de symptômes — qui pourraient guider un échantillonnage plus intelligent sans augmenter le nombre de personnes examinées.
Sélectionner par ordre plutôt que par pur hasard
L’étude se concentre sur des méthodes d’échantillonnage basées sur le classement, qui utilisent un indicateur rapide et peu onéreux pour ordonner les individus avant d’effectuer les mesures complètes et coûteuses. Dans l’échantillonnage par ensembles ordonnés (RSS), les personnes sont réparties en petits groupes et triées selon un marqueur simple comme la sévérité des symptômes ou un score de dépistage. Dans chaque groupe, on choisit pour mesure détaillée une personne à un rang particulier (par exemple, la deuxième la plus élevée). L’échantillonnage extrême par ensembles ordonnés (ERSS) va plus loin : il sélectionne intentionnellement les individus aux extrêmes de chaque groupe — les valeurs les plus basses et les plus hautes, et parfois le milieu — enrichissant l’échantillon en cas limites ou atypiques. Ces extrêmes comprennent souvent les patients réellement à risque qui seraient rares dans un échantillon purement aléatoire.
Tester l’idée sur des patients virtuels et réels
Pour évaluer l’impact de ces stratégies sur la régression logistique, les chercheurs ont réalisé de nombreuses simulations informatiques. Ils ont créé des populations artificielles de tailles et d’échantillons variés, avec différents degrés de déséquilibre de classes (allant d’issues équilibrées à des événements rares), et ont modifié la force de la relation entre la variable de classement bon marché et le véritable résultat. Pour chaque configuration, ils ont construit des modèles de prédiction selon trois plans : échantillonnage aléatoire simple, RSS classique et ERSS. Ils ont évalué les performances avec des mesures standard telles que la précision, l’aire sous la courbe ROC, le score F1 et le coefficient de corrélation de Matthews. Ils ont ensuite vérifié si ces tendances se confirmaient en pratique sur deux jeux de données réels : un pour prédire l’ostéoporose et un autre pour évaluer le risque maternel, où des variables comme l’âge ou l’indice de masse corporelle servaient de critères de classement naturels.
Ce qui s’est passé quand les extrêmes ont été privilégiés
Les résultats ont été remarquablement cohérents. Le RSS standard a généralement des performances proches de l’échantillonnage aléatoire, apportant peu d’amélioration. L’ERSS, en revanche, a souvent montré des gains nets, en particulier lorsque la variable de classement était modérément ou fortement liée au résultat et lorsque la taille des ensembles (le nombre de personnes classées ensemble) était plus grande. Avec des tailles d’ensemble de cinq ou dix, l’ERSS produisait fréquemment une précision supérieure, une meilleure séparation entre les cas à risque élevé et faible, et une détection renforcée de la classe minoritaire, même avec seulement 60 ou 120 patients pour l’entraînement. Dans de nombreux scénarios simulés, les métriques de performance pour l’ERSS approchaient ou dépassaient 0,95. Fait important, l’augmentation de la taille de la population globale avait peu d’effet ; ce qui importait était la manière dont l’échantillon était choisi. Dans les jeux de données sur l’ostéoporose et la santé maternelle, l’ERSS a de nouveau amélioré les performances de la régression logistique dès lors qu’une variable de classement suffisamment informative était disponible.
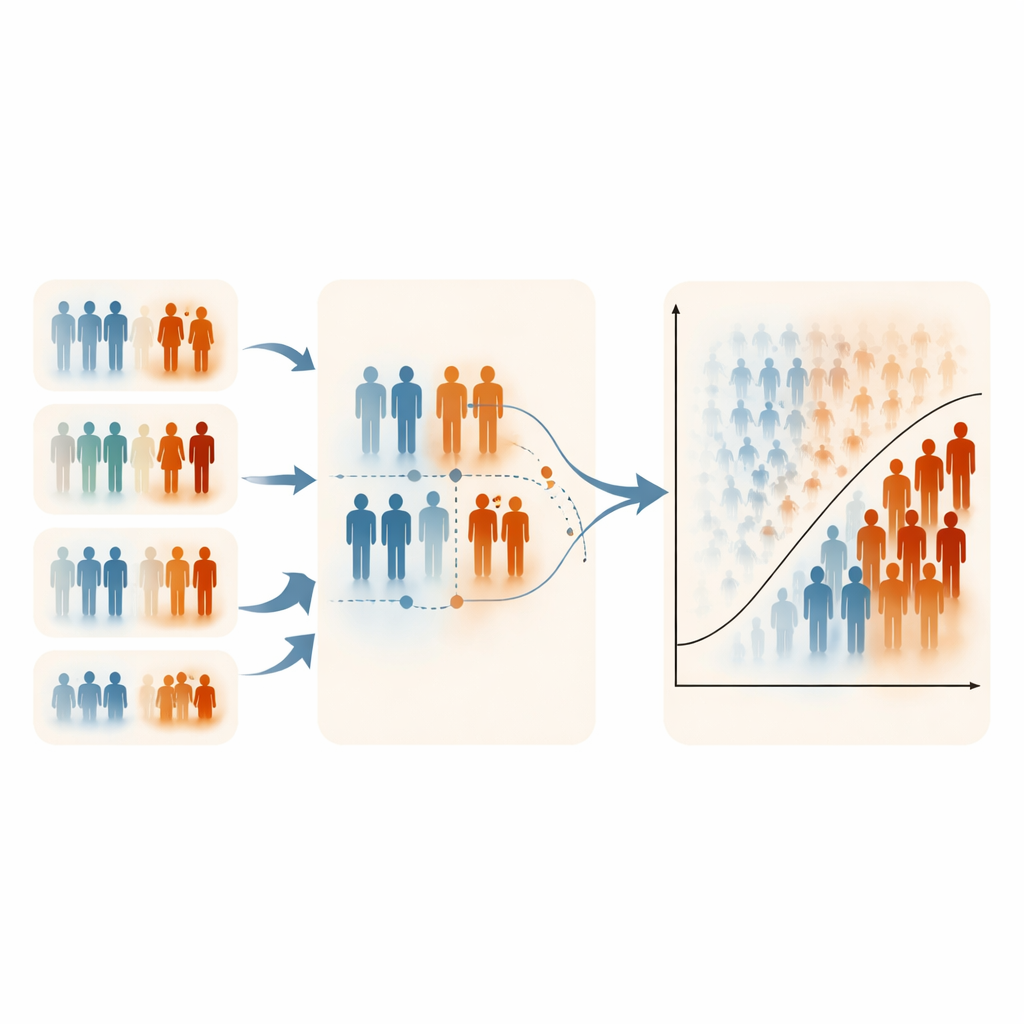
Limites, compromis et usage pratique
Les auteurs notent que l’ERSS dépend de l’existence d’au moins une variable pratique et informative pour le classement ; sans cela, la méthode perd son avantage. Leurs simulations se sont aussi concentrées sur des niveaux modérés de déséquilibre de classes, car les issues extrêmement rares sont difficiles à simuler tout en contrôlant finement à la fois la prévalence et les structures de corrélation. Dans certains contextes fortement asymétriques, l’ERSS a légèrement réduit la spécificité (classification correcte des individus en bonne santé), reflet de son accent délibéré sur les cas à haut risque. Néanmoins, les temps de calcul étaient similaires pour tous les plans d’échantillonnage, et les estimateurs des paramètres en régression logistique sont restés stables et non biaisés, ce qui suggère que ces échantillons plus intelligents ne déforment pas les relations médicales sous‑jacentes.
Ce que cela signifie pour les études médicales à venir
En termes simples, l’étude montre que choisir quels patients mesurer peut être tout aussi important que choisir l’algorithme de prédiction. En surgéchantillonnant délibérément les cas extrêmes ou aux limites via l’ERSS, les chercheurs peuvent offrir aux modèles de régression logistique une vision plus riche du bout risqué du spectre, améliorant les prédictions pour des jeux de données équilibrés comme déséquilibrés sans collecter plus de données au total. Pour les chercheurs en santé disposant de ressources limitées et confrontés à des issues rares mais critiques, l’ERSS offre un moyen pratique de maximiser la valeur de chaque patient mesuré, ce qui peut conduire à une détection plus précoce, des interventions mieux ciblées et des outils d’aide à la décision plus fiables.
Citation: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
Mots-clés: régression logistique, échantillonnage par ensembles ordonnés, données déséquilibrées, prévision du risque médical, plan d’échantillonnage