Clear Sky Science · de
Verbesserung der logistischen Regressionsklassifikation: Erkenntnisse aus Simulationen und Anwendungen in der Praxis durch Rangstichproben
Intelligenteres Sampling für bessere Gesundheitsprognosen
Wenn Ärztinnen, Ärzte und Krankenhäuser Daten zur Vorhersage verwenden, wer eine Krankheit entwickeln könnte, verlassen sie sich oft auf Machine‑Learning‑Werkzeuge wie die logistische Regression. Hinter den Kulissen sind diese Modelle jedoch nur so gut wie die Daten, mit denen sie gefüttert werden. Diese Studie stellt eine einfache, aber gewichtige Frage: Statt Patientinnen und Patienten rein zufällig auszuwählen, kann man die Auswahl klüger gestalten — insbesondere die seltenen, hochriskanten Fälle — sodass unsere Vorhersagemodelle präziser und effizienter werden?
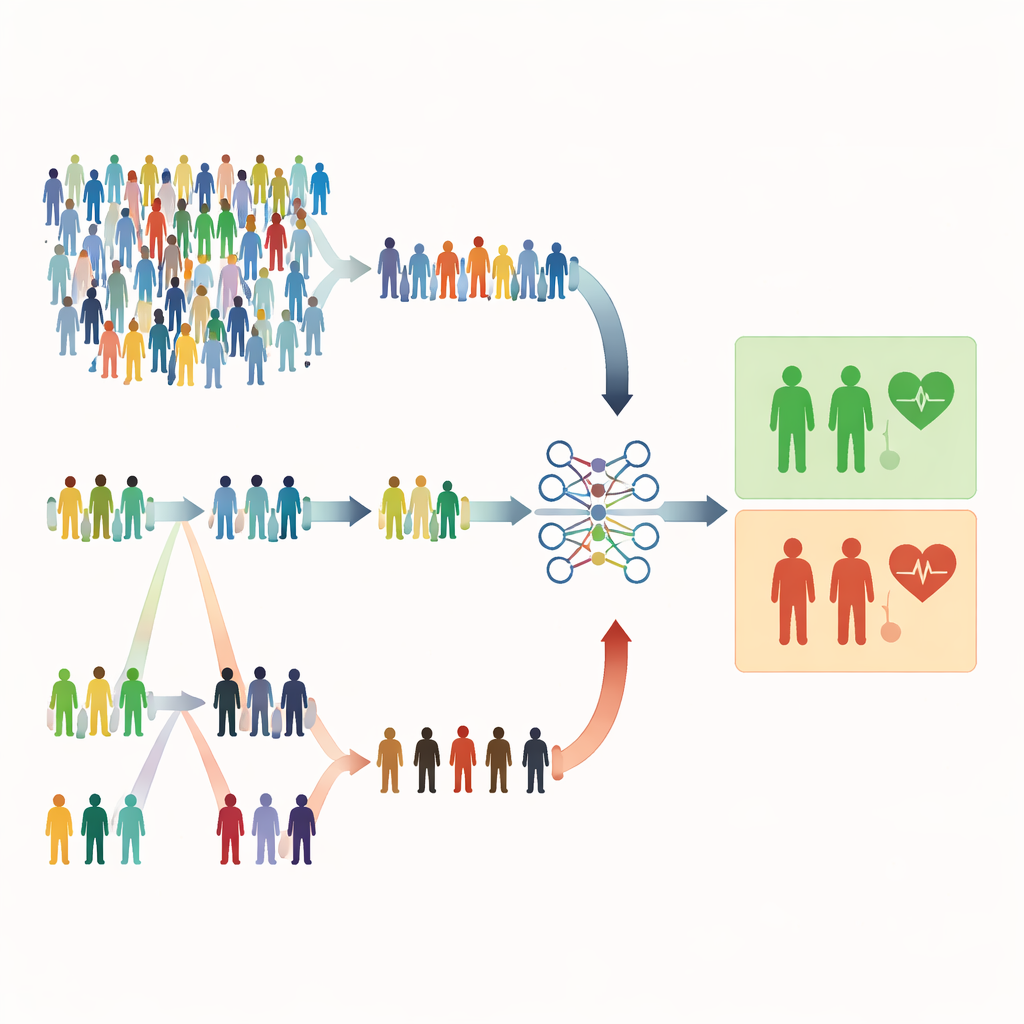
Warum rein zufällige Auswahl an Grenzen stößt
Die meisten medizinischen Studien nutzen weiterhin einfache Zufallsstichproben, bei denen jede Person die gleiche Wahrscheinlichkeit hat, ausgewählt zu werden. Das klingt gerecht, kann aber ineffizient sein. Wenn schwere Erkrankungen selten sind, enthält eine Zufallsstichprobe meist überwiegend gesunde Personen und zu wenige Hochrisikofälle. Das schwächt die Fähigkeit des Modells, Warnsignale zu erkennen, und zwingt Forschende oft dazu, deutlich größere Stichproben zu rekrutieren — mit höheren Kosten an Zeit, Geld und Aufwand. Die Autorinnen und Autoren dieses Papiers argumentieren, dass viele Gesundheitsstudien bereits über günstige, leicht messbare Hinweise verfügen — etwa Alter, Laborwerte oder Symptomskalen — die eine gezieltere Stichprobenwahl ermöglichen, ohne die Zahl der Messungen zu erhöhen.
Auswählen nach Rang statt reinem Zufall
Die Studie konzentriert sich auf rangbasierte Stichprobenverfahren, die ein schnelles, kostengünstiges Merkmal zur Vorreihung von Individuen nutzen, bevor die vollständigen, aufwändigen Messungen erfolgen. Bei der Rangstichprobe (ranked set sampling, RSS) werden Personen in kleine Gruppen eingeteilt und anhand eines einfachen Indikators wie Symptomschwere oder Screening‑Score geordnet. Aus jeder Gruppe wird eine Person mit einem bestimmten Rang (z. B. der zweitbeste) für die detaillierte Messung ausgewählt. Die extreme Rangstichprobe (ERSS) geht einen Schritt weiter: Es werden gezielt die Extremwerte jeder Gruppe — die niedrigsten und höchsten Werte und manchmal auch der mittlere — ausgewählt, wodurch die Stichprobe mit ungewöhnlichen oder randständigen Fällen angereichert wird. Diese Extreme enthalten häufig gerade jene Patienten, die tatsächliches Risiko tragen, aber in einer rein zufälligen Stichprobe selten würden.
Prüfung der Idee mit virtuellen und echten Patientendaten
Um zu untersuchen, wie sich diese Strategien auf die logistische Regression auswirken, führten die Forschenden umfassende Computersimulationen durch. Sie erzeugten künstliche Populationen mit unterschiedlichen Größen, Stichprobengrößen und Ausprägungen der Klassenungleichheit (von ausgeglichenen Ergebnissen bis zu seltenen Ereignissen) und variierten, wie stark die günstige Rangvariable mit dem wahren Ausgang zusammenhing. Für jede Einstellung bauten sie Vorhersagemodelle mit drei Designs: einfache Zufallsstichprobe, klassische Rangstichprobe und extreme Rangstichprobe. Die Leistungsbewertung erfolgte mit Standardmaßen wie Accuracy, Fläche unter der ROC‑Kurve, F1‑Score und Matthews Korrelationskoeffizient. Anschließend prüften sie, ob sich die Muster in der Praxis bestätigten, mithilfe von zwei realen Datensätzen: einem zur Vorhersage von Osteoporose und einem zur Einschätzung maternaler Gesundheitsrisiken, wobei Variablen wie Alter oder Body‑Mass‑Index als natürliche Ranginstrumente dienten.
Was geschah, wenn Extreme betont wurden
Die Ergebnisse waren durchweg aussagekräftig. Standard‑RSS schnitt meist in etwa so gut ab wie die Zufallsstichprobe und brachte wenig Verbesserung der Klassifikation. ERSS zeigte hingegen oft deutliche Vorteile, insbesondere wenn die Rangvariable mäßig bis stark mit dem Ergebnis korrelierte und wenn die Setgröße (die Anzahl der zusammen gereihten Personen) größer war. Bei Setgrößen von fünf oder zehn erzielte ERSS häufig höhere Genauigkeit, bessere Trennung zwischen Hoch‑ und Niedrigrisiko‑Fällen und eine stärkere Erkennung der Minderheitsklasse, selbst wenn nur 60 oder 120 Patientinnen und Patienten für das Training verwendet wurden. In vielen simulierten Szenarien näherten sich die Leistungskennzahlen für ERSS Werten von 0,95 oder überstiegen diese. Wichtig war: Die Vergrößerung der Gesamtpopulation hatte kaum Einfluss; entscheidend war, wie die Stichprobe ausgewählt wurde. Auch in den Osteoporose‑ und maternalen Gesundheitsdaten verbesserte ERSS die Leistung der logistischen Regression, sobald eine einigermaßen informative Rangvariable vorhanden war.
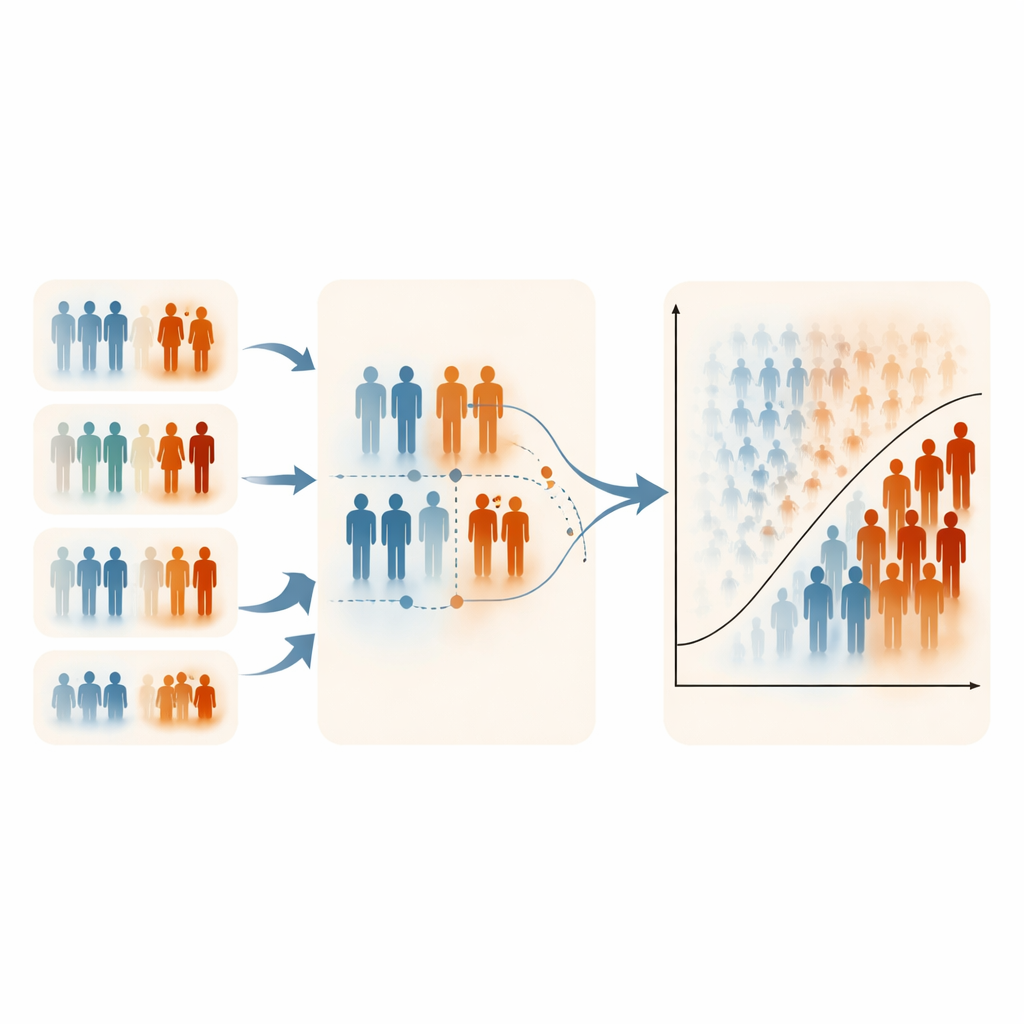
Grenzen, Abwägungen und praktische Anwendung
Die Autorinnen und Autoren weisen darauf hin, dass ERSS davon abhängt, mindestens eine praktikable, informationsreiche Variable zum Ranken zu haben; fehlt diese, verliert die Methode ihren Vorteil. Ihre Simulationen konzentrierten sich außerdem auf moderate Grade der Klassenungleichheit, da extrem seltene Ereignisse schwer zu simulieren sind, wenn man Prävalenz und Korrelationsstrukturen gleichzeitig präzise steuern will. In einigen stark verzerrten Szenarien verringerte ERSS leicht die Spezifität (die korrekte Klassifizierung gesunder Personen), was die bewusste Betonung von Hochrisikofällen widerspiegelt. Dennoch waren die Rechenzeiten bei allen Stichprobenentwürfen ähnlich, und die Parameterschätzungen der logistischen Regression blieben stabil und unverzerrt, was darauf hindeutet, dass diese intelligenteren Stichproben die zugrunde liegenden medizinischen Zusammenhänge nicht verfälschen.
Was das für zukünftige medizinische Studien bedeutet
Einfach gesagt zeigt die Studie, dass die Auswahl der zu messenden Patientinnen und Patienten ebenso wichtig sein kann wie die Wahl des Vorhersagealgorithmus. Durch gezieltes Oversampling von Extrem‑ oder Randfällen mittels ERSS können Forschende den logistischen Regressionsmodellen ein reichhaltigeres Bild des riskanten Endes des Spektrums geben und die Vorhersagen für ausgeglichene wie unausgeglichene Datensätze verbessern, ohne insgesamt mehr Daten zu erheben. Für Gesundheitsforscher mit begrenzten Ressourcen und seltenen, aber kritischen Ergebnissen bietet ERSS einen praktischen Weg, jede gemessene Person wertvoller zu machen — mit Potenzial für frühere Erkennung, gezieltere Interventionen und zuverlässigere Entscheidungsunterstützungssysteme.
Zitation: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
Schlüsselwörter: logistische Regression, Rangstichprobe, unausgeglichene Daten, medizinische Risikovorhersage, Stichprobenplanung