Clear Sky Science · he
שיפור סיווג ברגרסיה לוגיסטית: תובנות מסימולציות ויישומים מעשיים באמצעות דגימת קבוצות מדורגת
דגימה חכמה יותר לחיזויים בריאותיים מדויקים יותר
כאשר רופאים ובתי חולים משתמשים בנתונים כדי לחזות מי עלול לפתח מחלה, הם לעתים קרובות מסתמכים על כלים של למידת מכונה כמו רגרסיה לוגיסטית. אך מאחורי הקלעים, הכלים האלה טובים בדיוק כפי שהנתונים שאנו מספקים להם. המחקר הזה שואל שאלה פשוטה אך חזקה: במקום לבחור חולים אקראית בלבד, האם ניתן לבחור אותם בחוכמה רבה יותר — במיוחד את המקרים הנדירים ובעלי הסיכון הגבוה — כדי שהמודלים החיזויים שלנו יהיו חדישים ויעילים יותר?
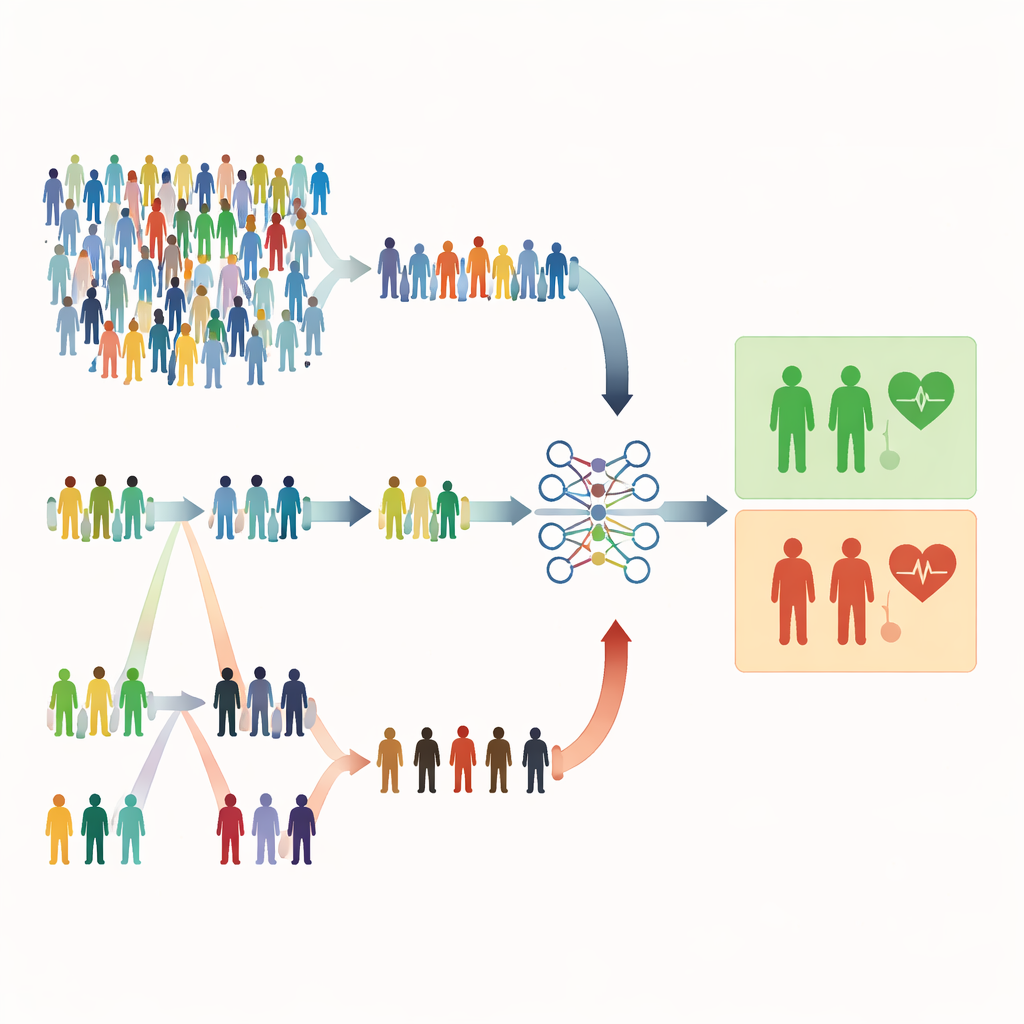
מדוע בחירות אקראיות רגילות עלולות להיות בלתי מספקות
ברוב המחקרים הרפואיים עדיין מסתמכים על דגימה אקראית פשוטה, שבה לכל אדם יש אותה הזדמנות להיבחר. זה נשמע הוגן, אבל יכול להיות בזבזני. כאשר מצבים חמורים נדירים, דגימה אקראית עלולה לכלול בעיקר אנשים בריאים ומעט מדי חולים בסיכון גבוה. הדבר מחליש את יכולת המודל לזהות סימני אזהרה ועלול להכריח את החוקרים לגייס מדגמים גדולים בהרבה, מה שדורש יותר זמן, כסף ומאמץ. המחברים טוענים שבמחקרים רבים בבריאות כבר יש לנו רמזים זולים וקלי מדידה — כמו גיל, ערכי מעבדה או ציון תסמינים — שיכולים להנחות דגימה חכמה יותר מבלי להגדיל את מספר הנבדקים שאנו מודדים.
בחירה לפי דרוג במקום על‑פי מזל טהור
המחקר מתמקד בשיטות דגימה מבוססות דרוג שמשתמשות במדד מהיר וזול כדי לדרג אנשים לפני המדידות המלאות והיקרות. בדגימת קבוצות מדורגת (RSS), מחלקים אנשים לקבוצות קטנות ומדרגים אותם לפי סמן פשוט כמו חומרת תסמינים או ציון סקר. מכל קבוצה בוחרים אדם עם דרג מסוים (למשל, השני בגובהו) למדידה מפורטת. דגימת קבוצות מדורגת קיצונית (ERSS) הולכת צעד נוסף: היא בוחרת בכוונה אנשים בקצוות של כל קבוצה — הערכים הנמוכים והגבוהים, ולעיתים גם את האמצע — ובכך מעשירה את המדגם במקרים חריגים או קוצתיים. קצוות אלו כוללים לעיתים את החולים שבאמת בסיכון אך היו נדירים במדגם אקראי טהור.
בדיקת הרעיון על מטופלים מדומים ומציאותיים
כדי לראות כיצד אסטרטגיות אלה משפיעות על רגרסיה לוגיסטית, החוקרים ערכו סימולציות ממוחשבות נרחבות. הם יצרו אוכלוסיות מלאכותיות בגדלים שונים, גדלי מדגם שונים ורמות שונות של חוסר איזון בכיתות (מאיזון ועד אירועים נדירים), ושינו עד כמה משתנה הדירוג הזול קשור לתוצאה האמיתית. בכל הגדרה הם בנו מודלים חיזוי באמצעות שלושה עיצובים: דגימה אקראית פשוטה, דגימת קבוצות מדורגת קלאסית, ודגימת קבוצות מדורגת קיצונית. הם העריכו ביצועים באמצעות מדדים סטנדרטיים כגון דיוק, שטח תחת עקומת ROC, נקודת F1 ומדד המתיווס (Matthews correlation coefficient). לאחר מכן הם בדקו האם הדפוסים נשמרים במציאות באמצעות שני מערכי נתונים אמיתיים: אחד לחיזוי אוסטאופורוזיס ואחד להערכת סיכון בריאותי מטפורמה של האם, שבה משתנים כמו גיל או מדד מסת גוף שימשו ככלי דירוג טבעי.
מה קרה כאשר הדגישו קצוות
התוצאות היו עקביות בצורה בולטת. RSS סטנדרטי בדרך כלל ביצע בערך כמו דגימה אקראית, ללא שיפור משמעותי בסיווג. לעומת זאת, ERSS סיפקה לעיתים קרובות רווחים ברורים, במיוחד כאשר משתנה הדירוג היה בקשר מתון או חזק עם התוצאה וכאשר גודל הקבוצה (מספר האנשים שדורגו יחד) היה גדול יותר. עם גדלי קבוצות של חמש או עשר, ERSS לעתים קרובות הניבה דיוק גבוה יותר, הפרדה טובה יותר בין מקרים בעלי סיכון גבוה ונמוך וגילוי חזק יותר של הכיתה המיעוטית, גם כאשר השתמשו רק ב‑60 או 120 מטופלים לאימון. במספר תרחישים מדומים מדדי הביצועים של ERSS הגיעו או אף עלו על 0.95. קריטי לציין, הגדלת גודל האוכלוסייה הכולל כמעט ולא השפיעה; מה שחשוב היה הוא האופן שבו בחרו את המדגם. במערכי המידע של אוסטאופורוזיס ובריאות האם, ERSS שוב שיפרה את ביצועי הרגרסיה הלוגיסטית בכל פעם שהיה זמין משתנה דירוג מידעתי סביר.
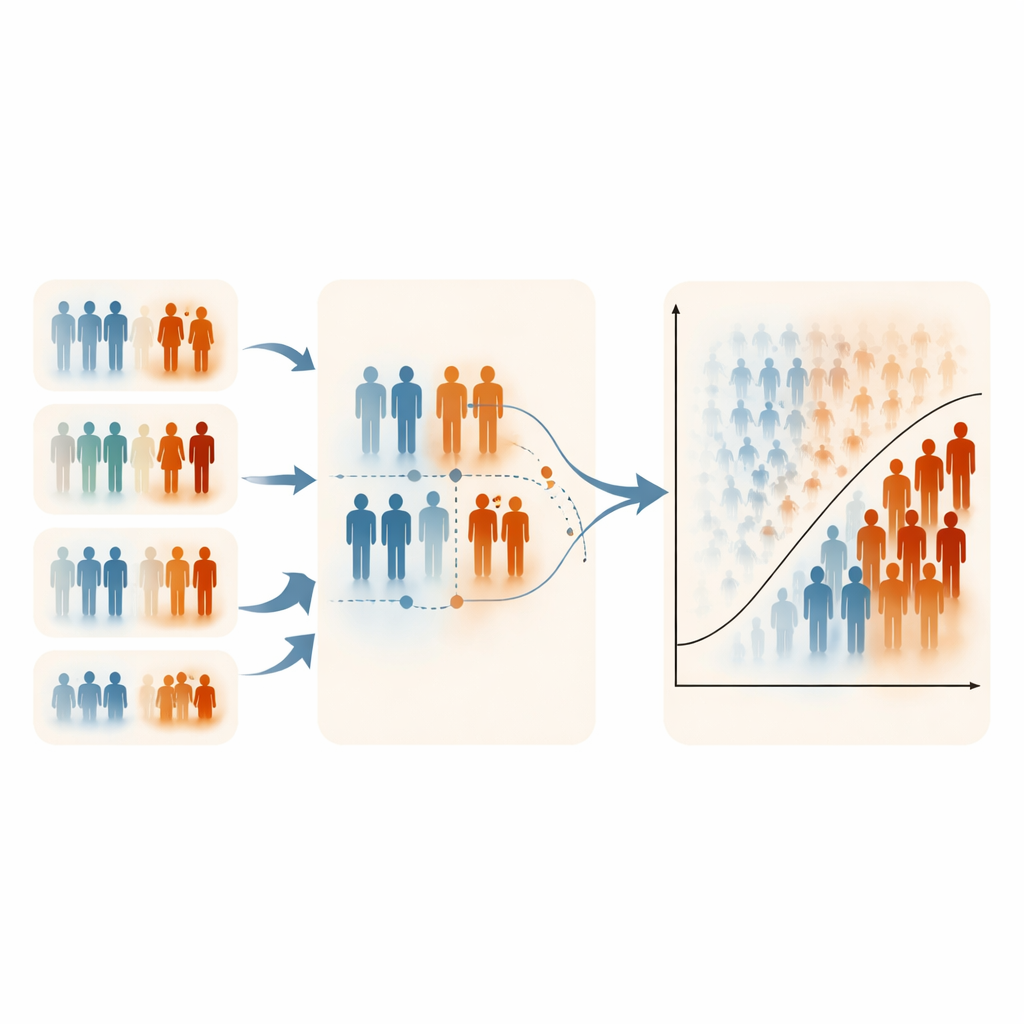
מגבלות, פשרות ושימוש מעשי
המחברים מציינים כי ERSS תלוית קיום לפחות משתנה דירוג פרקטי ומידע; בלעדיו השיטה מאבדת את יתרונה. הסימולציות שלהם התמקדו גם ברמות מתונות של חוסר איזון בכיתות, מכיוון שתוצאות נדירות מאוד קשה לסמל אותן תוך שליטה קפדנית גם בשכיחות וגם במבני המתאם. בחלק מההגדרות המחמירות מאוד, ERSS הורידה במעט את הספציפיות (סיווג נכון של אנשים בריאים), המשקפת את הדגש המכוון על מקרים בסיכון גבוה. עם זאת, זמני החישוב היו דומים בכל עיצובי הדגימה, והערכת הפרמטרים ברגרסיה הלוגיסטית נותרה יציבה ולא מוטה, מה שמרמז שהדגימות החכמות לא מעוותות את הקשרים הרפואיים הבסיסיים.
מה משמעות הדבר למחקרים רפואיים עתידיים
במילים ברורות, המחקר מראה שהבחירה אילו חולים למדוד יכולה להיות חשובה לא פחות מהבחירה באלגוריתם החיזוי להרצה. על‑ידי דגימה מכוונת של מקרים קיצוניים או קצהיים באמצעות ERSS, חוקרים יכולים לספק למודלי רגרסיה לוגיסטית תמונה עשירה יותר של קצה הסיכון, ולשפר חיזויים עבור מערכי נתונים מאוזנים ובלתי מאוזנים מבלי לאסוף יותר נתונים בסך הכל. לחוקרים בתחומי הבריאות המתמודדים עם משאבים מוגבלים ותוצאות נדירות אך קריטיות, ERSS מציעה דרך פרקטית לגרום לכך שכל נבדק הנמדד יוסיף יותר ערך, מה שעשוי להוביל לזיהוי מוקדם יותר, התערבויות ממוקדות יותר וכלים לתמיכה בקבלת החלטות אמינים יותר.
ציטוט: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
מילות מפתח: רגרסיה לוגיסטית, דגימת קבוצות מדורגת, נתונים בלתי מאוזנים, חיזוי סיכון רפואי, תכנון דגימה