Clear Sky Science · tr
Lojistik regresyon sınıflandırmasını geliştirmek: sıralı küme örneklemesiyle simülasyon ve gerçek dünya uygulamalarından çıkarımlar
Daha Akıllı Örnekleme ile Daha İyi Sağlık Öngörüleri
Doktorlar ve hastaneler bir kişinin hastalık geliştirme olasılığını tahmin etmek için veriye başvurduklarında genellikle lojistik regresyon gibi makine öğrenmesi araçlarına güvenirler. Ancak perde arkasında bu araçlar, beslendikleri veri kadar iyidir. Bu çalışma basit ama güçlü bir soru soruyor: hastaları tamamen rastgele seçmek yerine, özellikle nadir ve yüksek riskli vakaları daha akıllıca seçerek tahmin modellerimizi daha keskin ve daha verimli hale getirebilir miyiz?
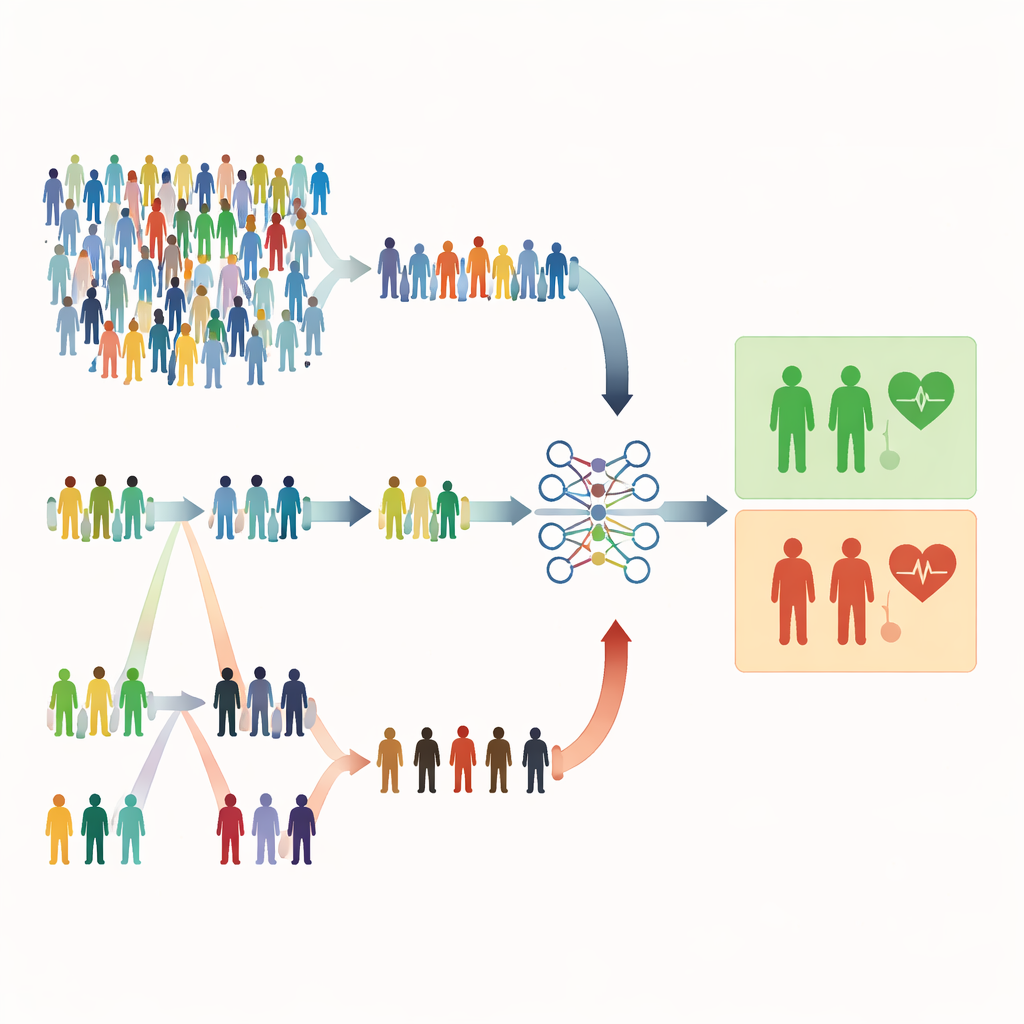
Standart Rastgele Seçim Neden Yetersiz Kalabilir
Çoğu tıbbi çalışma hâlâ her bireyin aynı seçilme şansına sahip olduğu basit rastgele örneklemeye dayanır. Bu adil gibi görünse de israflı olabilir. Ciddi durumlar nadir olduğunda rastgele seçim çoğunlukla sağlıklı kişileri, yüksek riskli hastaları ise az sayıda içerebilir. Bu, modelin uyarı işaretlerini tanıma yeteneğini zayıflatır ve araştırmacıların çok daha büyük örneklemler toplamasını gerektirebilir; bu da daha fazla zaman, para ve emek demektir. Bu makalenin yazarları, birçok sağlık çalışmasında yaş, laboratuvar değerleri veya semptom skorları gibi ucuz ve kolay ölçülen ipuçlarının zaten mevcut olduğunu ve bunların ölçtüğümüz kişi sayısını artırmadan daha akıllı örneklemeye rehberlik edebileceğini savunuyor.
Tamamen Rastgele Yerine Sıraya Göre Seçim
Çalışma, bireyleri tam ölçümlerden önce hızlı ve ucuz bir göstergeyle sıralayan sıralı örnekleme yöntemlerine odaklanıyor. Sıralı küme örneklemede (RSS), kişiler küçük gruplara ayrılır ve semptom şiddeti ya da bir tarama skoru gibi basit bir işaretçiye göre sıralanır. Her gruptan belirli bir sıra (örneğin ikinci en yüksek) seçilerek ayrıntılı ölçüm yapılır. Aşırı sıralı küme örneklemesi (ERSS) bir adım daha ileri gider: her grubun uç değerlerindeki — en düşük ve en yüksek — ve bazen ortadaki bireyleri kasıtlı olarak seçer; böylece örneklem sıra dışı veya sınır vakalarla zenginleştirilir. Bu uçlar genellikle tamamen rastgele bir örnekte nadir olacak, ancak gerçek risk taşıyan hastaları içerir.
Sanal ve Gerçek Hastalarla Fikri Test Etme
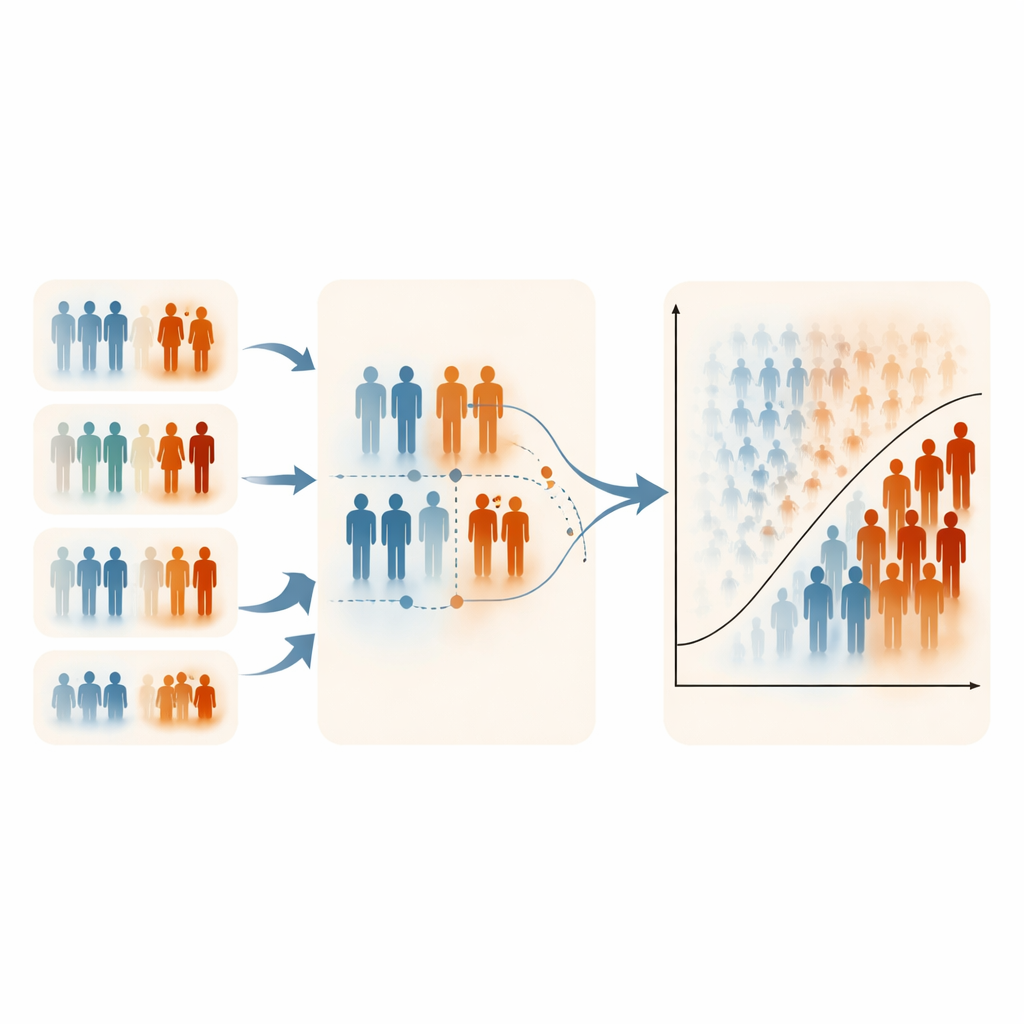
Bu stratejilerin lojistik regresyonu nasıl etkilediğini görmek için araştırmacılar kapsamlı bilgisayar simülasyonları yürüttüler. Farklı nüfus büyüklükleri, örnek boyutları ve sınıf dengesizliği dereceleri (denge durumundan nadir olaylara kadar) olan yapay popülasyonlar yarattılar ve ucuz sıralama değişkeninin gerçek sonuçla ne kadar güçlü ilişkili olduğunu değiştirdiler. Her ayarda üç tasarım kullanılarak tahmin modelleri kurdular: basit rastgele örnekleme, klasik sıralı küme örnekleme ve aşırı sıralı küme örneklemesi. Performansı doğruluk, ROC eğrisi altındaki alan, F1 skoru ve Matthews korelasyon katsayısı gibi standart ölçütlerle değerlendirdiler. Ardından bu kalıpların osteoporozu tahmin eden ve anne sağlığı riskini değerlendiren (yaş veya vücut kitle indeksi gibi değişkenlerin doğal sıralama araçları olduğu) iki gerçek veri kümesinde de geçerli olup olmadığını kontrol ettiler.
Aşırılar Vurgulandığında Ne Oldu
Sonuçlar çarpıcı derecede tutarlıydı. Standart RSS genellikle rastgele örneklemeyle yaklaşık aynı performansı gösterdi ve sınıflandırmada çok az iyileşme sundu. ERSS ise özellikle sıralama değişkeni sonuca orta ila güçlü derecede ilişkili olduğunda ve birlikte sıralanan kişi sayısı (set boyutu) daha büyük olduğunda açık kazançlar sağladı. Beş veya on kişilik set boyutlarında ERSS sıklıkla daha yüksek doğruluk, yüksek ve düşük riskli vakalar arasında daha iyi ayrım ve azınlık sınıfının daha güçlü tespiti sağladı; bu, yalnızca 60 veya 120 hasta eğitim için kullanıldığında bile görüldü. Birçok simüle edilmiş senaryoda ERSS için performans metrikleri 0,95’e yaklaştı veya onu aştı. Önemli olarak, toplam nüfus boyutunun artırılması az etkiliydi; belirleyici olan örneğin nasıl seçildiğiydi. Osteoporoz ve anne sağlığı veri kümelerinde de ERSS, makul derecede bilgilendirici bir sıralama değişkeni mevcut olduğunda lojistik regresyon performansını yine iyileştirdi.
Sınırlar, Takaslar ve Pratik Kullanım
Yazarlar ERSS’nin sıralama için en az bir pratik ve bilgilendirici değişkene bağlı olduğunu not ediyor; bu yoksa yöntem avantajını kaybediyor. Simülasyonları ayrıca sınıf dengesizliğinin ılımlı düzeylerine odaklandı; çünkü aşırı nadir olaylar önvalans ve korelasyon yapılarını dikkatle kontrol ederken simüle etmek zordur. Bazı güçlü çarpık ayarlarda ERSS özgüllüğü (sağlıklı bireyleri doğru sınıflandırma) biraz düşürebilir; bu, yüksek riskli vakalara kasıtlı vurgu yapmasının bir yansımasıdır. Yine de hesaplama süreleri tüm örnekleme tasarımları arasında benzerdi ve lojistik regresyondan elde edilen parametre tahminleri stabildi ve önyargısız kaldı; bu da bu daha akıllı örneklemlerin altta yatan tıbbi ilişkileri çarpıtmadığını gösteriyor.
Gelecek Tıbbi Çalışmalar İçin Anlamı
Sade bir ifadeyle, çalışma hangi hastaları ölçeceğimizi seçmenin hangi tahmin algoritmasını çalıştıracağımızı seçmek kadar önemli olabileceğini gösteriyor. ERSS kullanarak kasıtlı olarak uç veya sınır vakaları fazladan örnekleyerek araştırmacılar lojistik regresyon modellerine riskli spektrumun daha zengin bir görüntüsünü verebilir; bu, dengeli ve dengesiz veri setlerinde daha iyi tahminler sağlar ve genel olarak daha fazla veri toplamadan elde edilir. Kaynakları sınırlı ve nadir ama kritik sonuçlarla karşılaşan sağlık araştırmacıları için ERSS, ölçülen her hastayı daha değerli kılmanın pratik bir yolunu sunar; bu da daha erken tespit, daha hedeflenmiş müdahaleler ve daha güvenilir karar destek araçlarına yol açabilir.
Atıf: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
Anahtar kelimeler: lojistik regresyon, sıralı küme örneklemesi, dengesiz veriler, tıbbi risk tahmini, örnekleme tasarımı