Clear Sky Science · pl
Ulepszanie klasyfikacji w regresji logistycznej: wnioski z symulacji i zastosowań w praktyce dzięki próbkowaniu z uporządkowanymi zbiorami
Inteligentniejsze próbkowanie dla lepszych prognoz zdrowotnych
Gdy lekarze i szpitale wykorzystują dane do przewidywania, kto może rozwinąć chorobę, często polegają na narzędziach uczenia maszynowego, takich jak regresja logistyczna. Jednak w praktyce te narzędzia są tak dobre, jak dane, które im dostarczymy. W tym badaniu postawiono proste, lecz istotne pytanie: zamiast wybierać pacjentów wyłącznie losowo, czy można wybrać ich mądrzej — w szczególności rzadkie, wysokiego ryzyka przypadki — tak, aby nasze modele predykcyjne były jednocześnie dokładniejsze i bardziej wydajne?
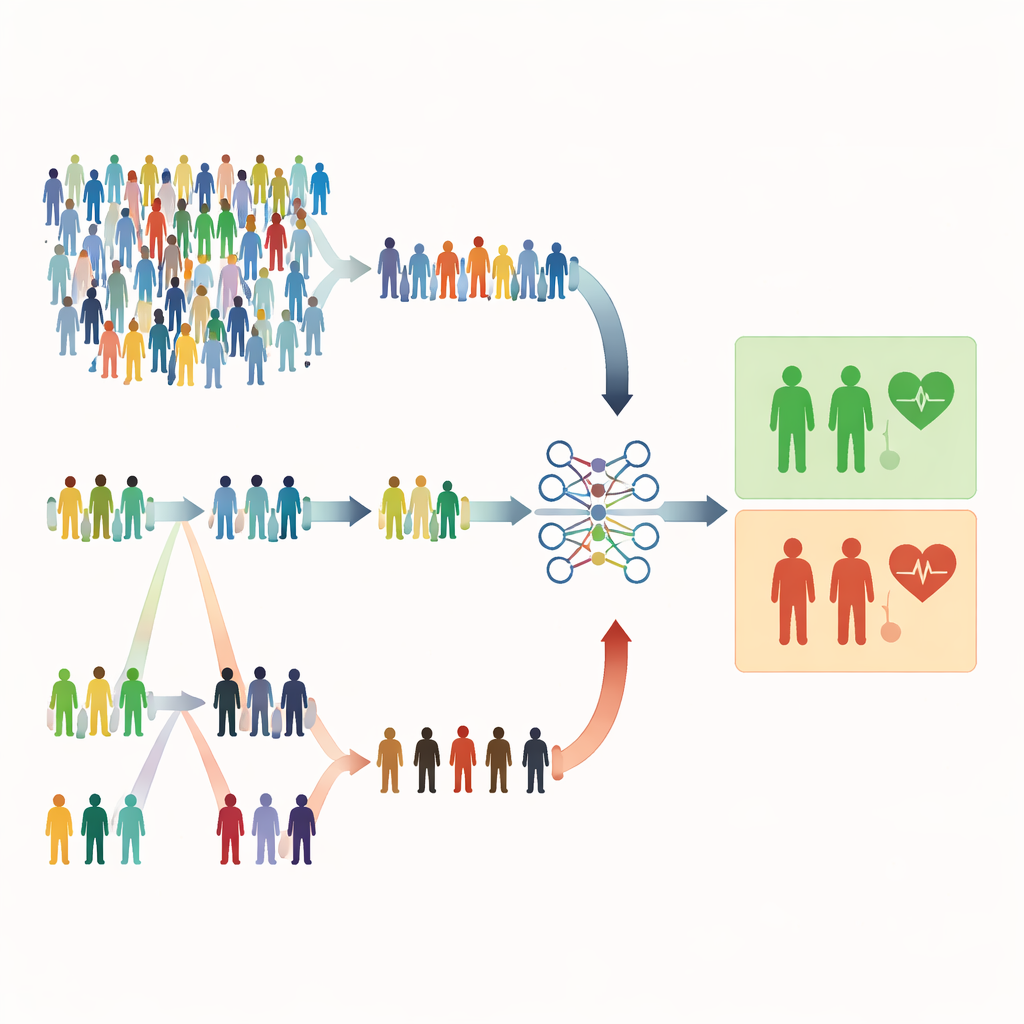
Dlaczego zwykły losowy wybór może zawodzić
Większość badań medycznych dalej opiera się na prostym losowym próbkowaniu, gdzie każda osoba ma taką samą szansę znalezienia się w próbie. Brzmi to uczciwie, ale bywa nieefektywne. Gdy poważne stany są rzadkie, losowy dobór może obejmować głównie zdrowe osoby i zbyt mało pacjentów wysokiego ryzyka. Osłabia to zdolność modelu do rozpoznawania sygnałów alarmowych i może zmuszać badaczy do pozyskania znacznie większych prób, co kosztuje więcej czasu, pieniędzy i wysiłku. Autorzy artykułu argumentują, że w wielu badaniach zdrowotnych mamy już tanie, łatwe do zmierzenia wskazówki — jak wiek, wyniki badań laboratoryjnych czy oceny objawów — które mogłyby kierować inteligentniejszym próbkowaniem bez zwiększania liczby mierzeń.
Wybieranie na podstawie rangi zamiast czystego przypadku
Badanie koncentruje się na metodach próbkowania opartych na porządkowaniu, które wykorzystują szybki, niedrogi wskaźnik do uporządkowania osób przed wykonaniem pełnych, kosztownych pomiarów. W próbkowaniu z uporządkowanymi zbiorami (RSS) osoby dzieli się na małe grupy i porządkuje według prostego markera, takiego jak nasilenie objawów czy wynik przesiewowy. Z każdej grupy wybiera się osobę o określonej randze (na przykład drugą najwyższą) do szczegółowego pomiaru. Ekstremalne próbkowanie z uporządkowanymi zbiorami (ERSS) idzie o krok dalej: celowo selekcjonuje osoby na skrajach każdej grupy — o najniższych i najwyższych wartościach, a czasem także środkowe — wzbogacając próbę o przypadki nietypowe lub brzegowe. Takie skrajne wartości często obejmują pacjentów rzeczywiście będących w ryzyku, którzy w czysto losowej próbie występowaliby rzadko.
Testowanie pomysłu na danych wirtualnych i rzeczywistych
Aby sprawdzić, jak te strategie wpływają na regresję logistyczną, badacze przeprowadzili obszerne symulacje komputerowe. Stworzyli sztuczne populacje o różnych rozmiarach, wielkościach próby i stopniach niezrównoważenia klas (od zrównoważonych wyników po rzadkie zdarzenia) oraz zmieniali siłę powiązania między tanim wskaźnikiem porządkującym a prawdziwym wynikiem. Dla każdego ustawienia budowali modele predykcyjne wykorzystując trzy projekty: proste losowe próbkowanie, klasyczne RSS i ekstremalne ERSS. Oceniali wydajność za pomocą standardowych miar, takich jak trafność, pole pod krzywą ROC, miara F1 oraz współczynnik korelacji Matthewsa. Następnie sprawdzili, czy wzorce utrzymują się w praktyce, używając dwóch rzeczywistych zestawów danych: jednego prognozującego osteoporozę i drugiego oceniającego ryzyko zdrowia matek, gdzie zmienne takie jak wiek czy wskaźnik masy ciała służyły jako naturalne narzędzia porządkowania.
Co się stało, gdy podkreślono skrajne przypadki
Wyniki były niezwykle spójne. Standardowe RSS zazwyczaj wypadało porównywalnie do losowego próbkowania, przynosząc niewielką poprawę w klasyfikacji. ERSS natomiast często dawało widoczne korzyści, szczególnie gdy zmienna porządkująca była umiarkowanie lub silnie powiązana z wynikiem oraz gdy rozmiar zbioru (liczba osób porządkowanych razem) był większy. Przy rozmiarach zbiorów pięć lub dziesięć ERSS często zapewniało wyższą trafność, lepsze rozdzielenie przypadków wysokiego i niskiego ryzyka oraz silniejsze wykrywanie klasy mniejszościowej, nawet gdy do treningu użyto tylko 60 lub 120 pacjentów. W wielu scenariuszach symulacyjnych miary wydajności dla ERSS zbliżały się do 0,95 lub je przekraczały. Kluczowe było to, że zwiększanie ogólnej wielkości populacji miało niewielki wpływ; liczyło się to, jak wybrano próbkę. W zestawach danych dotyczących osteoporozy i zdrowia matek ERSS ponownie poprawiło działanie regresji logistycznej zawsze, gdy dostępna była dostatecznie informatywna zmienna porządkująca.
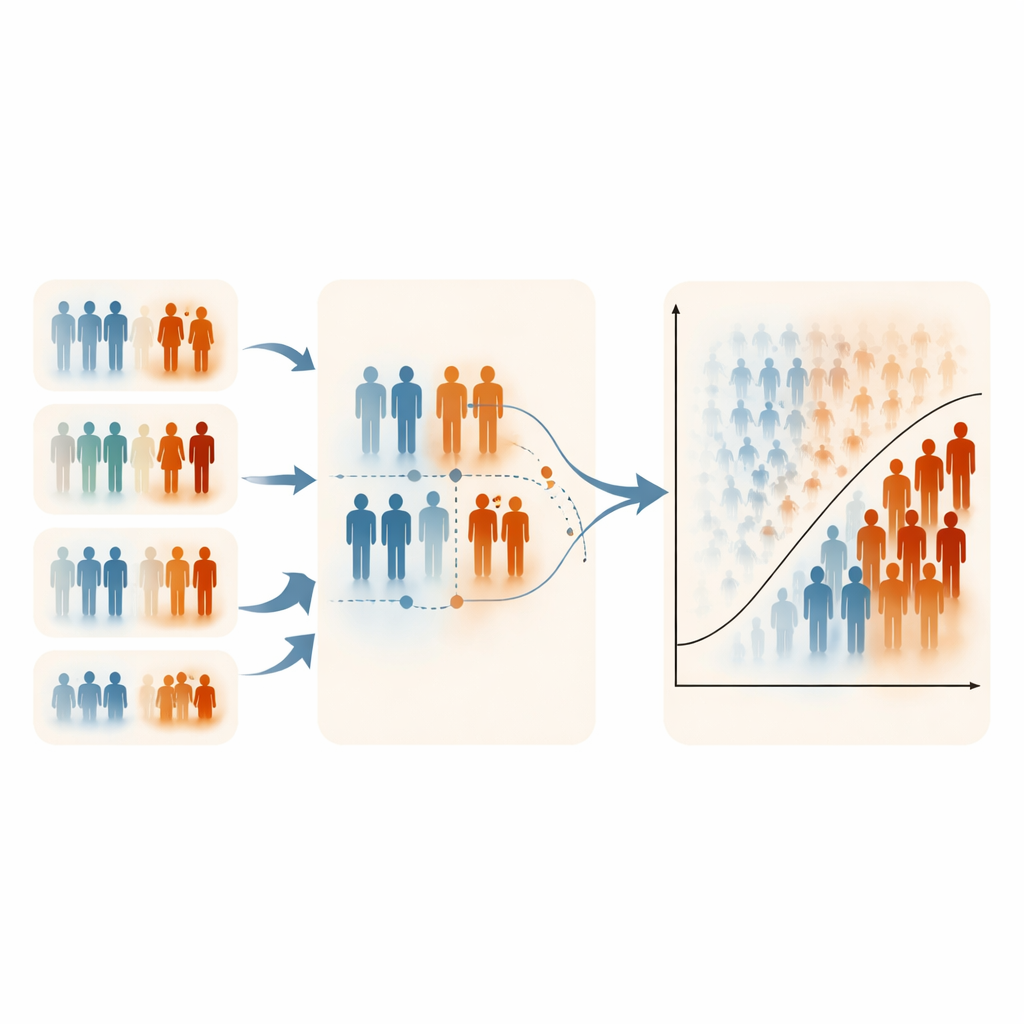
Ograniczenia, kompromisy i praktyczne zastosowanie
Autorzy zauważają, że ERSS zależy od posiadania co najmniej jednej praktycznej, informatywnej zmiennej do porządkowania; bez niej metoda traci przewagę. Ich symulacje skupiły się również na umiarkowanych poziomach niezrównoważenia klas, ponieważ bardzo rzadkie zdarzenia są trudne do zasymulowania przy jednoczesnym kontrolowaniu zarówno częstości występowania, jak i struktur korelacji. W niektórych silnie skośnych ustawieniach ERSS nieco obniżało specyficzność (prawidłową klasyfikację osób zdrowych), co odzwierciedla jego zamierzone skupienie na przypadkach wysokiego ryzyka. Mimo to czasy obliczeń były podobne we wszystkich projektach próbkowania, a estymaty parametrów z regresji logistycznej pozostały stabilne i nieobciążone, co sugeruje, że te inteligentniejsze próbki nie zniekształcają podstawowych zależności medycznych.
Co to oznacza dla przyszłych badań medycznych
Mówiąc prosto, badanie pokazuje, że wybór pacjentów do pomiaru może być równie ważny jak wybór algorytmu predykcyjnego. Poprzez celowe nadreprezentowanie przypadków skrajnych lub brzegowych za pomocą ERSS, badacze mogą dać modelom regresji logistycznej bogatszy wgląd w ryzykowny koniec spektrum, poprawiając prognozy zarówno dla zbiorów zrównoważonych, jak i niezrównoważonych bez konieczności zbierania większej liczby danych. Dla badaczy zdrowia dysponujących ograniczonymi zasobami i mierzących rzadkie, ale krytyczne zdarzenia, ERSS oferuje praktyczny sposób, by każdy mierzony pacjent wnosił więcej wartości, co może prowadzić do wcześniejszego wykrywania, lepiej ukierunkowanych interwencji i bardziej wiarygodnych narzędzi wspomagających decyzje.
Cytowanie: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
Słowa kluczowe: regresja logistyczna, próbkowanie z uporządkowanymi zbiorami, dane niezrównoważone, predykcja ryzyka w medycynie, projekt próbkowania