Clear Sky Science · it
Migliorare la classificazione con regressione logistica: intuizioni da simulazioni e applicazioni reali tramite il ranked set sampling
Campionamento più intelligente per previsioni sanitarie migliori
Quando medici e ospedali usano i dati per prevedere chi potrebbe sviluppare una malattia, spesso si affidano a strumenti di machine learning come la regressione logistica. Ma, dietro le quinte, questi strumenti sono efficaci quanto i dati che li alimentano. Questo studio pone una domanda semplice ma incisiva: invece di selezionare i pazienti completamente a caso, possiamo sceglierli in modo più intelligente—soprattutto i casi rari ad alto rischio—così che i nostri modelli di previsione diventino più precisi ed efficienti?
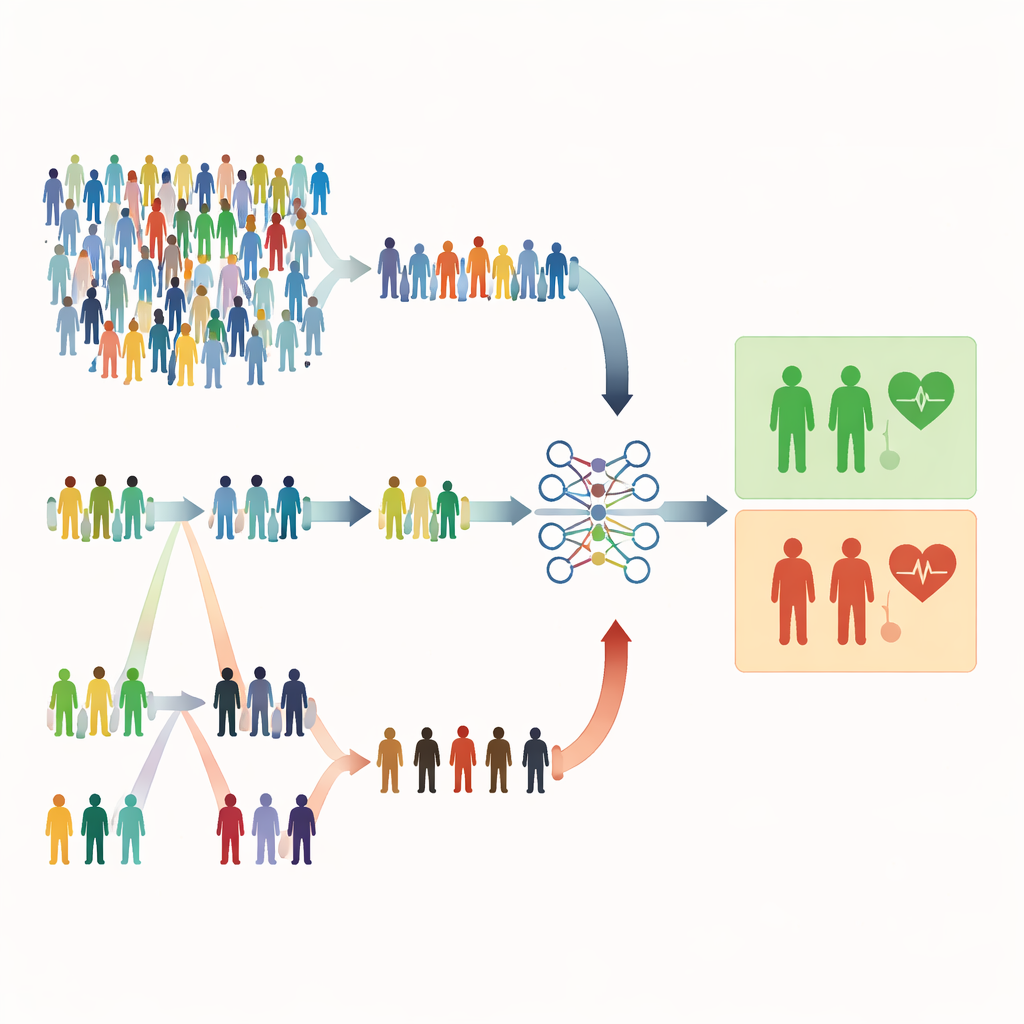
Perché le estrazioni casuali possono essere insufficienti
La maggior parte degli studi medici si basa ancora sul campionamento casuale semplice, in cui ogni persona ha la stessa probabilità di essere selezionata. Questo sembra equo, ma può risultare inefficiente. Quando le condizioni gravi sono rare, un'estrazione casuale può includere per lo più persone sane e troppo pochi pazienti ad alto rischio. Ciò indebolisce la capacità del modello di riconoscere segnali d'allarme e può costringere i ricercatori a reclutare campioni molto più grandi, con maggiori costi di tempo, denaro e sforzo. Gli autori sostengono che in molti studi sanitari disponiamo già di indizi economici e facili da misurare—come età, valori di laboratorio o punteggi di sintomi—che potrebbero guidare un campionamento più intelligente senza aumentare il numero di persone da misurare.
Selezionare per ordine invece che per puro caso
Lo studio si concentra su metodi di campionamento basati sul rango che utilizzano un indicatore rapido ed economico per ordinare gli individui prima di effettuare le misurazioni complete e costose. Nel ranked set sampling (RSS), le persone vengono divise in piccoli gruppi e ordinate tramite un marcatore semplice come la gravità dei sintomi o un punteggio di screening. Da ciascun gruppo si seleziona una persona con un rango particolare (per esempio, la seconda più alta) per la misurazione dettagliata. L’extreme ranked set sampling (ERSS) va oltre: seleziona intenzionalmente individui agli estremi di ciascun gruppo—i valori più bassi e più alti, e talvolta quelli centrali—arricchendo il campione con casi insoliti o ai confini. Questi estremi spesso includono proprio i pazienti veramente a rischio che sarebbero rari in un campione puramente casuale.
Testare l’idea con pazienti virtuali e reali
Per valutare come queste strategie influenzino la regressione logistica, i ricercatori hanno eseguito estese simulazioni al computer. Hanno creato popolazioni artificiali con diverse dimensioni, taglie del campione e gradi di sbilanciamento delle classi (da esiti bilanciati a eventi rari), e hanno variato quanto la variabile economica di rango fosse correlata all’esito reale. Per ogni scenario hanno costruito modelli predittivi usando tre disegni: campionamento casuale semplice, ranked set sampling classico e extreme ranked set sampling. Hanno giudicato le prestazioni usando misure standard come accuratezza, area sotto la curva ROC, F1‑score e coefficiente di correlazione di Matthews. Hanno poi verificato se i risultati si confermassero nella pratica usando due set di dati reali: uno per prevedere l’osteoporosi e un altro per valutare il rischio nella salute materna, dove variabili come età o indice di massa corporea fungevano da strumenti naturali di rango.
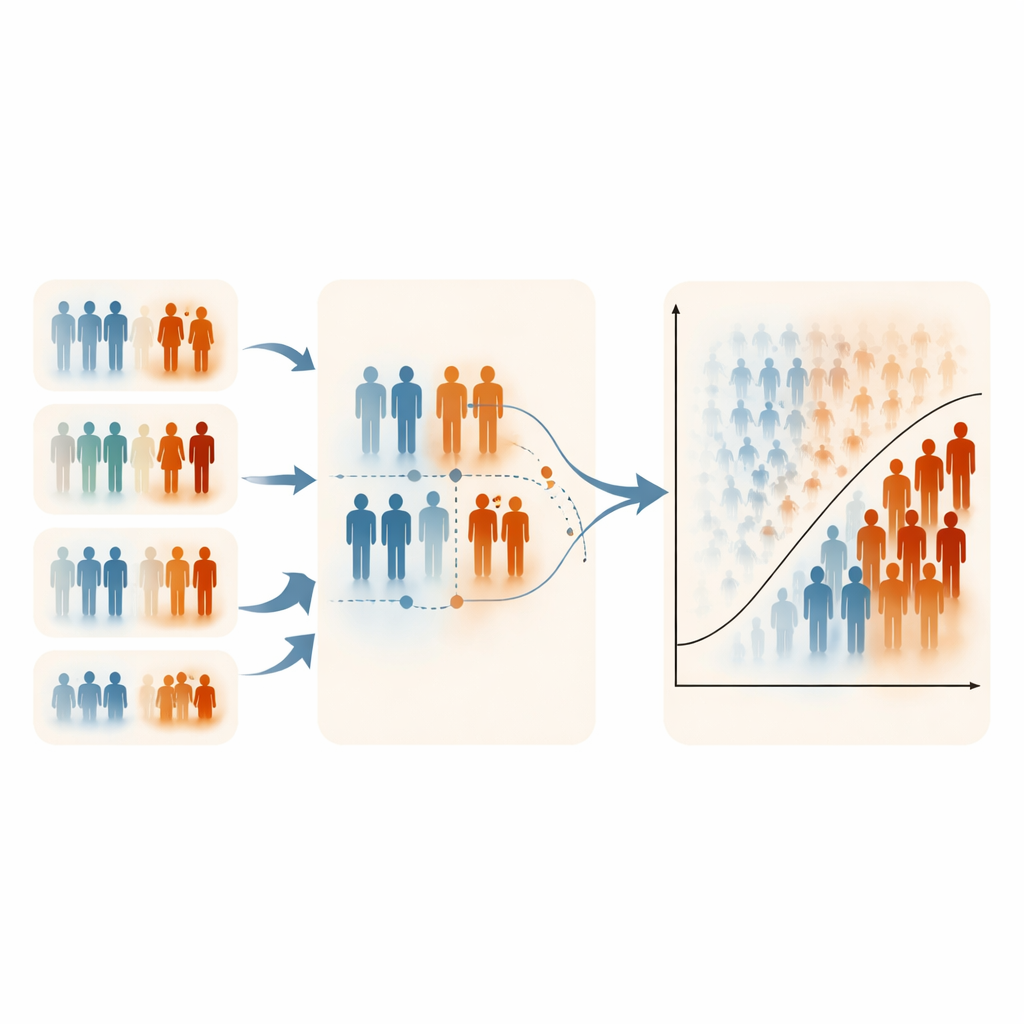
Cosa è successo quando sono stati enfatizzati gli estremi
I risultati sono stati sorprendentemente coerenti. L’RSS standard in genere ha ottenuto prestazioni simili al campionamento casuale, offrendo pochi miglioramenti nella classificazione. L’ERSS, invece, ha spesso fornito vantaggi chiari, specialmente quando la variabile di rango era moderatamente o fortemente correlata con l’esito e quando la dimensione del set (il numero di persone ordinate insieme) era maggiore. Con set di dimensione cinque o dieci, l’ERSS ha frequentemente prodotto maggiore accuratezza, migliore separazione tra casi ad alto e basso rischio e una rilevazione più forte della classe minoritaria, anche quando si usavano solo 60 o 120 pazienti per l’addestramento. In molti scenari simulati, le metriche di prestazione per l’ERSS si avvicinavano o superavano 0,95. È cruciale notare che aumentare la dimensione complessiva della popolazione aveva scarso effetto; ciò che contava era come il campione veniva scelto. Nei dataset su osteoporosi e salute materna, l’ERSS ha nuovamente migliorato le prestazioni della regressione logistica ogniqualvolta fosse disponibile una variabile di rango ragionevolmente informativa.
Limiti, compromessi e uso pratico
Gli autori osservano che l’ERSS dipende dalla presenza di almeno una variabile pratica e informativa per il rango; senza di essa il metodo perde il suo vantaggio. Le loro simulazioni si sono anche concentrate su livelli moderati di sbilanciamento delle classi, perché esiti estremamente rari sono difficili da simulare mantenendo un controllo accurato sia della prevalenza che delle strutture di correlazione. In alcuni contesti fortemente sbilanciati, l’ERSS ha leggermente ridotto la specificità (la corretta classificazione degli individui sani), riflettendo la sua enfasi deliberata sui casi ad alto rischio. Tuttavia, i tempi di calcolo sono risultati simili per tutti i disegni di campionamento e le stime dei parametri dalla regressione logistica sono rimaste stabili e non distorte, suggerendo che questi campioni più intelligenti non alterano le relazioni mediche sottostanti.
Cosa significa questo per i futuri studi medici
In termini pratici, lo studio mostra che scegliere quali pazienti misurare può essere importante quanto scegliere quale algoritmo predittivo usare. Sovracampionando deliberatamente i casi estremi o ai confini tramite ERSS, i ricercatori possono offrire ai modelli di regressione logistica una visione più ricca dell’estremità a rischio dello spettro, migliorando le previsioni sia per dataset bilanciati che sbilanciati senza raccogliere più dati nel complesso. Per i ricercatori in ambito sanitario con risorse limitate e con esiti rari ma critici, l’ERSS offre un modo pratico per far sì che ogni paziente misurato conti di più, portando potenzialmente a una rilevazione precoce, interventi più mirati e strumenti di supporto decisionale più affidabili.
Citazione: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
Parole chiave: regressione logistica, ranked set sampling, dati sbilanciati, predizione del rischio medico, disegno di campionamento