Clear Sky Science · es
Mejora de la clasificación por regresión logística: conclusiones de simulaciones y aplicaciones reales mediante muestreo por conjuntos ordenados
Muestreo más inteligente para mejores predicciones de salud
Cuando médicos y hospitales usan datos para prever quién podría desarrollar una enfermedad, a menudo recurren a herramientas de aprendizaje automático como la regresión logística. Pero, en el fondo, estas herramientas solo son tan buenas como los datos que se les proporcionan. Este estudio plantea una pregunta simple pero potente: en lugar de seleccionar pacientes puramente al azar, ¿podemos escogerlos de forma más inteligente—especialmente los casos raros y de alto riesgo—para que nuestros modelos predictivos sean más precisos y eficientes?
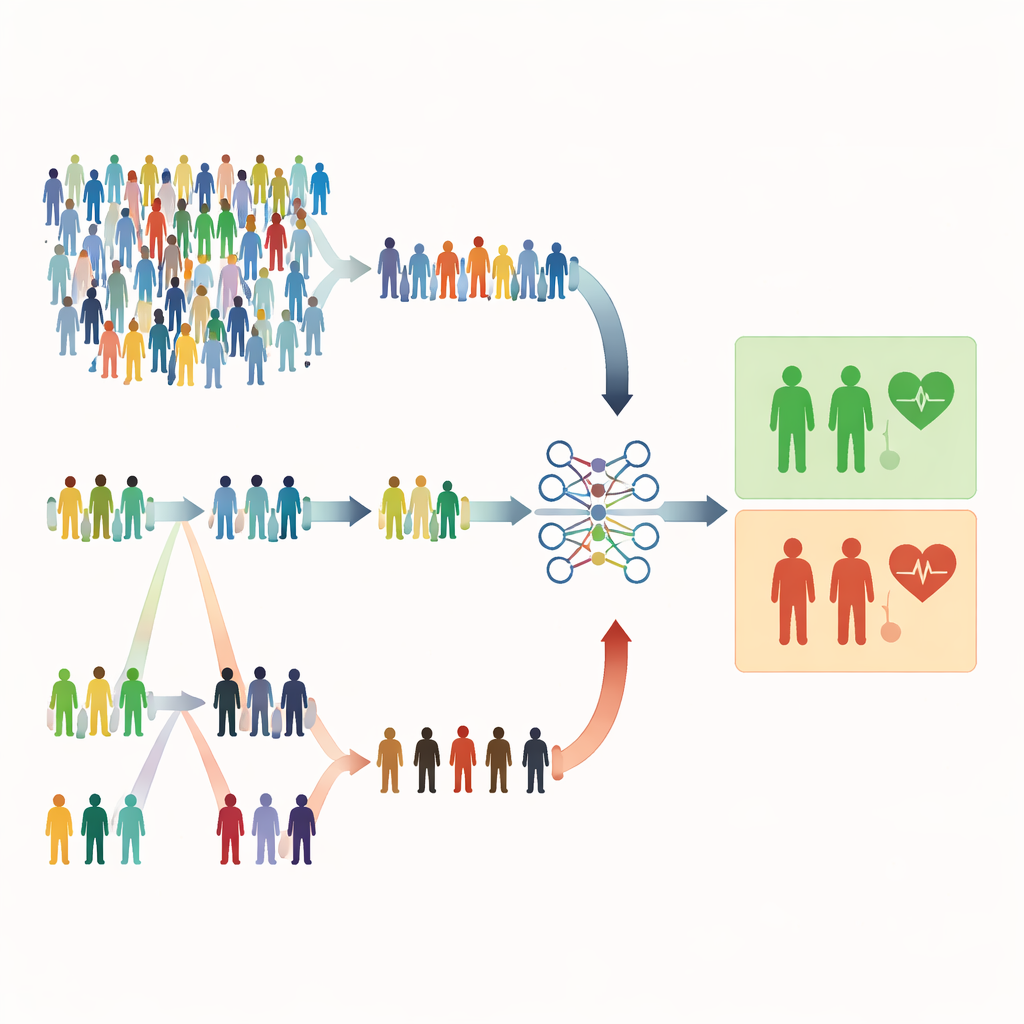
Por qué las elecciones aleatorias ordinarias pueden quedarse cortas
La mayoría de los estudios médicos aún dependen del muestreo aleatorio simple, donde cada persona tiene la misma probabilidad de ser seleccionada. Eso suena justo, pero puede resultar ineficiente. Cuando las condiciones graves son raras, una extracción aleatoria puede incluir mayoritariamente personas sanas y muy pocos pacientes de alto riesgo. Esto debilita la capacidad del modelo para reconocer señales de advertencia y puede obligar a los investigadores a reclutar muestras mucho más grandes, lo que implica más tiempo, coste y esfuerzo. Los autores de este artículo sostienen que en muchos estudios de salud ya disponemos de pistas baratas y fáciles de medir—como la edad, resultados de análisis o puntuaciones de síntomas—que podrían orientar un muestreo más inteligente sin aumentar el número de personas a medir.
Elegir por orden en lugar de por pura casualidad
El estudio se centra en métodos de muestreo basados en el orden que emplean un indicador rápido y económico para ordenar a los individuos antes de realizar las mediciones completas y costosas. En el muestreo por conjuntos ordenados (RSS), las personas se dividen en pequeños grupos y se ordenan según un marcador sencillo, como la gravedad de los síntomas o una puntuación de cribado. De cada grupo se selecciona una persona con un rango determinado (por ejemplo, la segunda más alta) para la medición detallada. El muestreo por conjuntos ordenados extremos (ERSS) va un paso más allá: selecciona deliberadamente a las personas en los extremos de cada grupo—los valores más bajos y más altos, y a veces los intermedios—enriqueciendo la muestra con casos inusuales o en los límites. Estos extremos suelen incluir a los pacientes que verdaderamente están en riesgo pero que serían raros en una muestra puramente aleatoria.
Probar la idea con pacientes virtuales y reales
Para evaluar cómo afectan estas estrategias a la regresión logística, los investigadores realizaron extensas simulaciones por ordenador. Crearon poblaciones artificiales con distintos tamaños, tamaños de muestra y grados de desbalance de clases (desde resultados equilibrados hasta eventos raros), y variaron qué tan fuerte estaba relacionada la variable barata de ordenación con el resultado verdadero. Para cada escenario, construyeron modelos predictivos usando tres diseños: muestreo aleatorio simple, muestreo por conjuntos ordenados clásico y muestreo por conjuntos ordenados extremos. Evaluaron el rendimiento con medidas estándar como la exactitud, el área bajo la curva ROC, la puntuación F1 y el coeficiente de correlación de Matthews. Luego comprobaron si los patrones se mantenían en la práctica usando dos conjuntos de datos reales: uno para predecir osteoporosis y otro para evaluar el riesgo de salud materna, donde variables como la edad o el índice de masa corporal sirvieron como herramientas naturales de ordenación.
Qué ocurrió cuando se enfatizaron los extremos
Los resultados fueron sorprendentemente consistentes. El RSS estándar generalmente se comportó de forma similar al muestreo aleatorio, ofreciendo poca mejora en la clasificación. ERSS, sin embargo, aportó a menudo ganancias claras, especialmente cuando la variable de ordenación estaba moderada o fuertemente relacionada con el resultado y cuando el tamaño del conjunto (el número de personas ordenadas juntas) era mayor. Con tamaños de conjunto de cinco o diez, ERSS frecuentemente produjo mayor exactitud, mejor separación entre casos de alto y bajo riesgo y una detección más sólida de la clase minoritaria, incluso cuando solo se usaban 60 o 120 pacientes para el entrenamiento. En muchos escenarios simulados, las métricas de rendimiento para ERSS se acercaron o superaron 0,95. Es crucial que aumentar el tamaño total de la población tuvo poco efecto; lo que importaba era cómo se elegía la muestra. En los conjuntos de datos de osteoporosis y salud materna, ERSS volvió a mejorar el rendimiento de la regresión logística siempre que existiera una variable de ordenación razonablemente informativa.
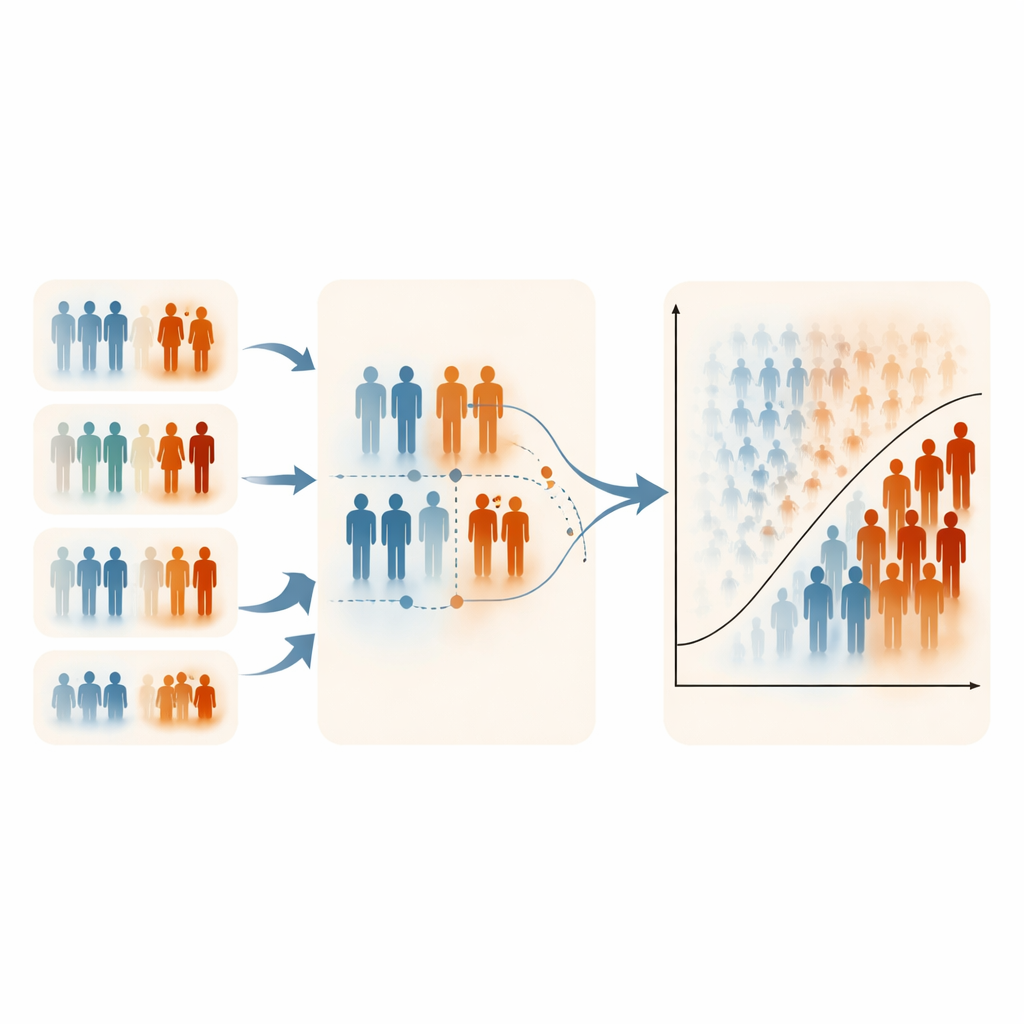
Límites, compensaciones y uso práctico
Los autores señalan que ERSS depende de disponer al menos de una variable práctica e informativa para ordenar; sin ella, el método pierde ventaja. Sus simulaciones también se centraron en niveles moderados de desbalance de clases, porque los resultados extremadamente raros son difíciles de simular controlando cuidadosamente tanto la prevalencia como las estructuras de correlación. En algunos escenarios muy sesgados, ERSS redujo ligeramente la especificidad (clasificar correctamente a los individuos sanos), reflejando su énfasis deliberado en los casos de alto riesgo. No obstante, los tiempos de cálculo fueron similares entre todos los diseños de muestreo, y las estimaciones de los parámetros de la regresión logística se mantuvieron estables y sin sesgo, lo que sugiere que estas muestras más inteligentes no distorsionan las relaciones médicas subyacentes.
Qué significa esto para futuros estudios médicos
En términos sencillos, el estudio muestra que elegir qué pacientes medir puede ser tan importante como elegir qué algoritmo predictivo ejecutar. Al sobresamplar deliberadamente casos extremos o en los límites mediante ERSS, los investigadores pueden ofrecer a los modelos de regresión logística una visión más rica del extremo de riesgo del espectro, mejorando las predicciones tanto para conjuntos de datos equilibrados como desbalanceados sin recopilar más datos en conjunto. Para los investigadores en salud con recursos limitados y resultados raros pero críticos, ERSS ofrece una manera práctica de hacer que cada paciente medido cuente más, lo que podría conducir a detecciones más tempranas, intervenciones mejor dirigidas y herramientas de apoyo a la decisión más fiables.
Cita: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
Palabras clave: regresión logística, muestreo por conjuntos ordenados, datos desbalanceados, predicción de riesgo médico, diseño de muestreo