Clear Sky Science · pt
Melhorando a classificação por regressão logística: insights de simulação e aplicações reais por meio de amostragem por conjuntos ranqueados
Amostragem mais inteligente para melhores previsões de saúde
Quando médicos e hospitais usam dados para prever quem pode desenvolver uma doença, costumam recorrer a ferramentas de aprendizado de máquina como a regressão logística. Mas, por trás das cortinas, essas ferramentas são tão boas quanto os dados que lhes damos. Este estudo faz uma pergunta simples, porém poderosa: em vez de selecionar pacientes puramente ao acaso, podemos escolhê-los de forma mais inteligente—especialmente os casos raros e de alto risco—para que nossos modelos de previsão se tornem mais precisos e eficientes?
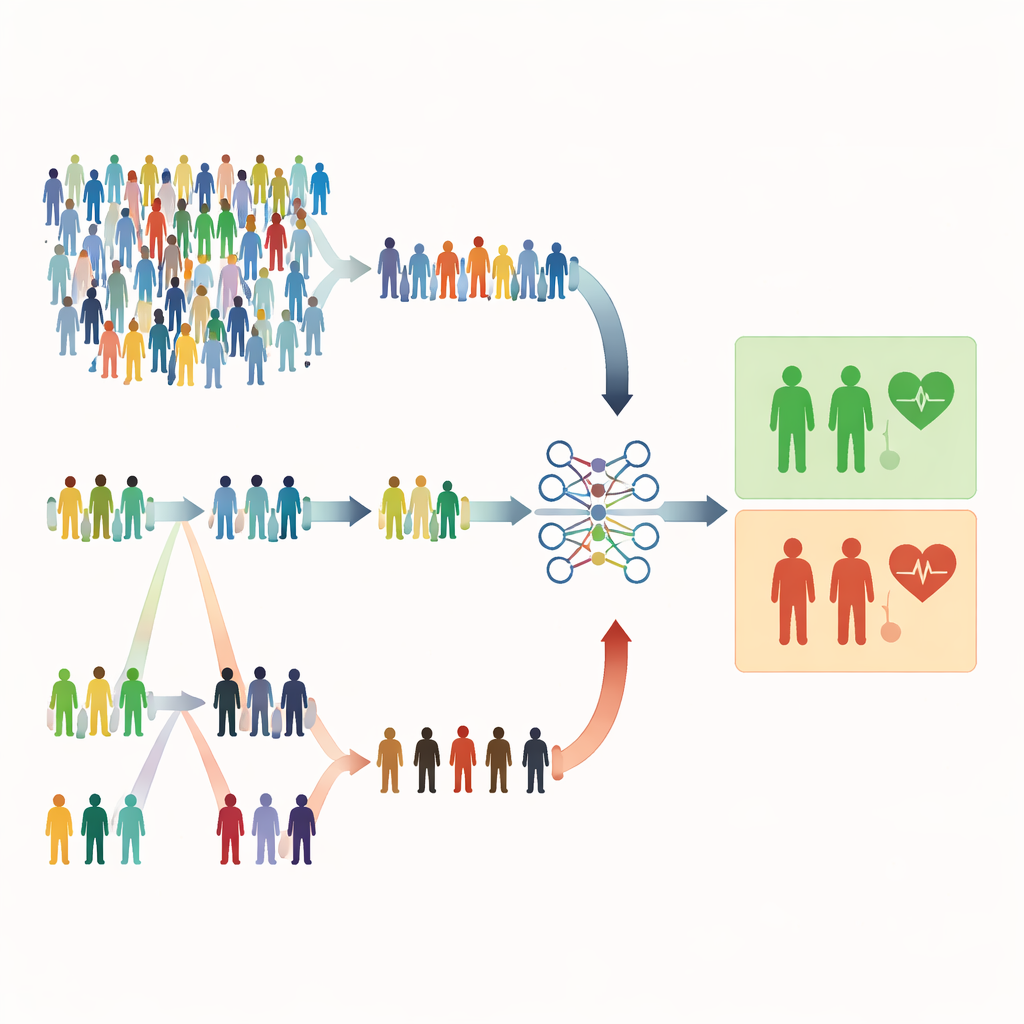
Por que escolhas aleatórias comuns podem ser insuficientes
A maioria dos estudos médicos ainda depende da amostragem aleatória simples, em que toda pessoa tem a mesma chance de ser selecionada. Isso parece justo, mas pode ser desperdiçador. Quando condições graves são raras, uma amostra aleatória pode incluir principalmente pessoas saudáveis e pouquíssimos pacientes de alto risco. Isso enfraquece a capacidade do modelo de reconhecer sinais de alerta e pode forçar os pesquisadores a recrutar amostras muito maiores, o que custa mais tempo, dinheiro e esforço. Os autores deste trabalho argumentam que, em muitos estudos de saúde, já dispomos de pistas baratas e fáceis de medir—como idade, resultados laboratoriais ou escores de sintoma—que poderiam orientar uma amostragem mais inteligente sem aumentar o número total de pessoas avaliadas.
Escolhendo por ordem em vez de puro acaso
O estudo foca em métodos de amostragem baseados em rank que usam um indicador rápido e barato para ordenar os indivíduos antes de realizar as medições completas e custosas. Na amostragem por conjuntos ranqueados (RSS), as pessoas são divididas em pequenos grupos e ordenadas por um marcador simples, como a gravidade dos sintomas ou um escore de triagem. De cada grupo, escolhe‑se uma pessoa com um posto específico (por exemplo, a segunda maior) para medição detalhada. A amostragem por conjuntos extremos (ERSS) vai além: seleciona intencionalmente pessoas nas extremidades de cada grupo—os valores mais baixos e mais altos, e às vezes os intermediários—enriquecendo a amostra com casos incomuns ou limítrofes. Esses extremos frequentemente incluem os pacientes que estão de fato em risco, mas que seriam raros em uma amostra puramente aleatória.
Testando a ideia com pacientes virtuais e reais
Para avaliar como essas estratégias afetam a regressão logística, os pesquisadores realizaram extensas simulações por computador. Criaram populações artificiais com tamanhos variados, diferentes tamanhos de amostra e graus de desequilíbrio de classes (de resultados balanceados a eventos raros), e variaram o quanto a variável de ranking barata estava relacionada ao resultado verdadeiro. Para cada cenário, construíram modelos preditivos usando três desenhos: amostragem aleatória simples, amostragem por conjuntos ranqueados clássica e amostragem por conjuntos extremos. Julgaram o desempenho com medidas padrão, como acurácia, área sob a curva ROC, F1‑score e coeficiente de correlação de Matthews. Em seguida, verificaram se os padrões se mantinham na prática usando dois conjuntos de dados reais: um prevendo osteoporose e outro avaliando risco materno, onde variáveis como idade ou índice de massa corporal serviram como ferramentas naturais de ranqueamento.
O que aconteceu quando as extremidades foram enfatizadas
Os resultados foram notavelmente consistentes. O RSS padrão geralmente teve desempenho semelhante ao da amostragem aleatória, oferecendo pouca melhoria na classificação. O ERSS, no entanto, frequentemente proporcionou ganhos claros, especialmente quando a variável de ranqueamento estava moderada ou fortemente relacionada ao desfecho e quando o tamanho do conjunto (o número de pessoas ranqueadas juntas) era maior. Com tamanhos de conjunto de cinco ou dez, o ERSS frequentemente produziu maior acurácia, melhor separação entre casos de alto e baixo risco e detecção mais forte da classe minoritária, mesmo quando apenas 60 ou 120 pacientes foram usados para treinamento. Em muitos cenários simulados, as métricas de desempenho para o ERSS se aproximaram ou superaram 0,95. Crucialmente, aumentar o tamanho total da população teve pouco efeito; o que importou foi como a amostra foi escolhida. Nos conjuntos de dados de osteoporose e saúde materna, o ERSS novamente melhorou o desempenho da regressão logística sempre que uma variável de ranqueamento razoavelmente informativa estava disponível.
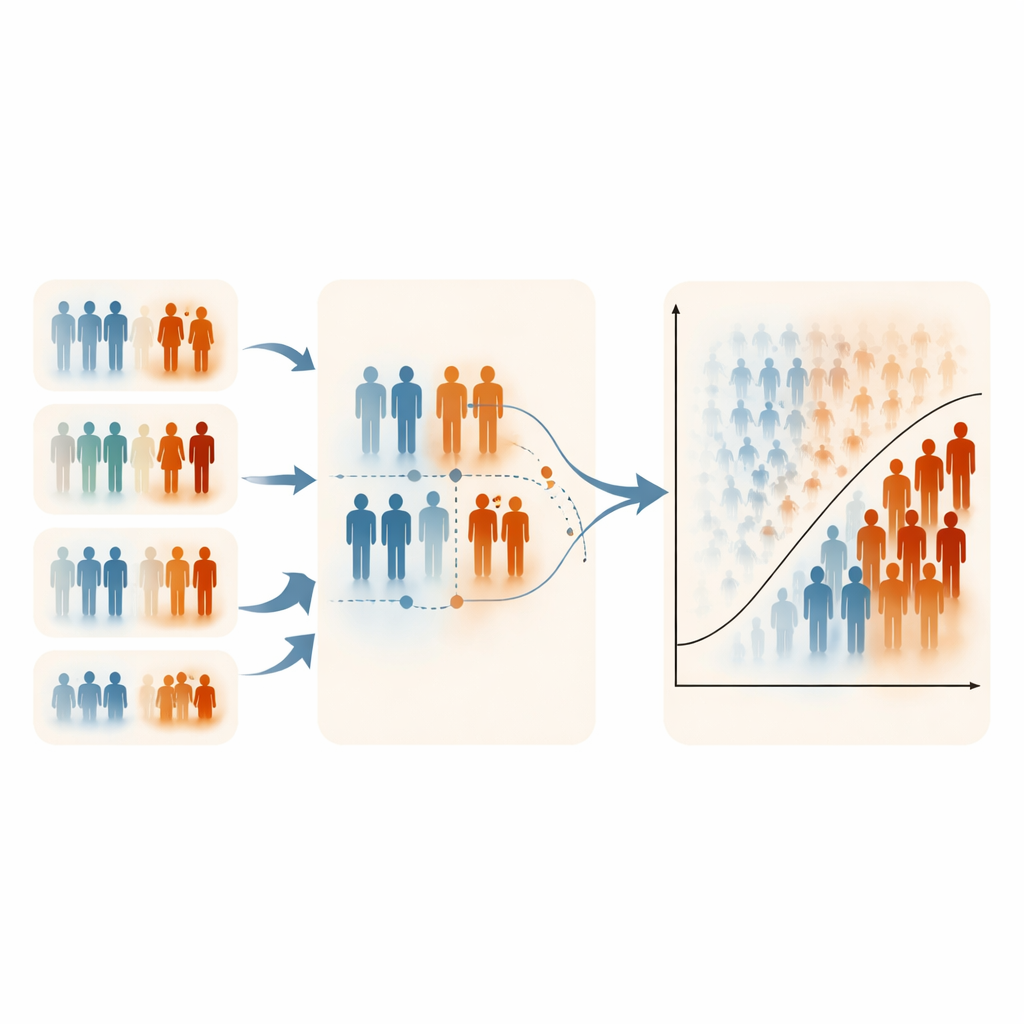
Limites, trade‑offs e uso prático
Os autores observam que o ERSS depende de ter ao menos uma variável prática e informativa para ranqueamento; sem ela, o método perde sua vantagem. Suas simulações também se concentraram em níveis moderados de desequilíbrio de classes, porque desfechos extremamente raros são difíceis de simular enquanto se controla cuidadosamente tanto a prevalência quanto as estruturas de correlação. Em alguns cenários altamente assimétricos, o ERSS reduziu ligeiramente a especificidade (classificar corretamente indivíduos saudáveis), refletindo sua ênfase deliberada em casos de alto risco. Ainda assim, os tempos de computação foram semelhantes entre todos os desenhos amostrais, e as estimativas de parâmetros da regressão logística permaneceram estáveis e não viesadas, sugerindo que essas amostras mais inteligentes não distorcem as relações médicas subjacentes.
O que isso significa para estudos médicos futuros
Em termos simples, o estudo mostra que escolher quais pacientes medir pode ser tão importante quanto escolher qual algoritmo de predição rodar. Ao superamostrar deliberadamente casos extremos ou limítrofes usando o ERSS, os pesquisadores podem oferecer aos modelos de regressão logística uma visão mais rica da extremidade de risco do espectro, melhorando previsões tanto para conjuntos de dados balanceados quanto desequilibrados sem coletar mais dados no total. Para pesquisadores em saúde com recursos limitados e desfechos raros mas críticos, o ERSS oferece uma forma prática de fazer com que cada paciente medido contribua mais, potencialmente levando a detecções mais precoces, intervenções mais bem direcionadas e ferramentas de apoio à decisão mais confiáveis.
Citação: Yousefi, R., Liquet, B., Mahdizadeh, M. et al. Enhancing logistic regression classification: insights from simulation and real-world applications through ranked set sampling. Sci Rep 16, 11938 (2026). https://doi.org/10.1038/s41598-026-41333-5
Palavras-chave: regressão logística, amostragem por conjuntos ranqueados, dados desequilibrados, previsão de risco médico, desenho amostral