Clear Sky Science · zh
一种可解释的深度学习框架用于视频暴力检测:基于无监督关键帧选择与注意力卷积神经网络
为什么更智能的视频审查很重要
来自街头摄像头、体育场和社交媒体的视频每天累积数十亿小时。在这股洪流中,隐藏着对警察、安全团队和在线平台极为重要的短暂暴力瞬间。人工值守无法监看所有画面,而现有用于标记危险片段的人工智能系统往往像黑箱:即便准确,它们也很少说明为何判定某段为暴力。本文提出了一种新的人工智能框架,不仅能快速且准确地发现暴力,还能突出每帧中促成决策的区域,帮助人们信任并核验机器所见。
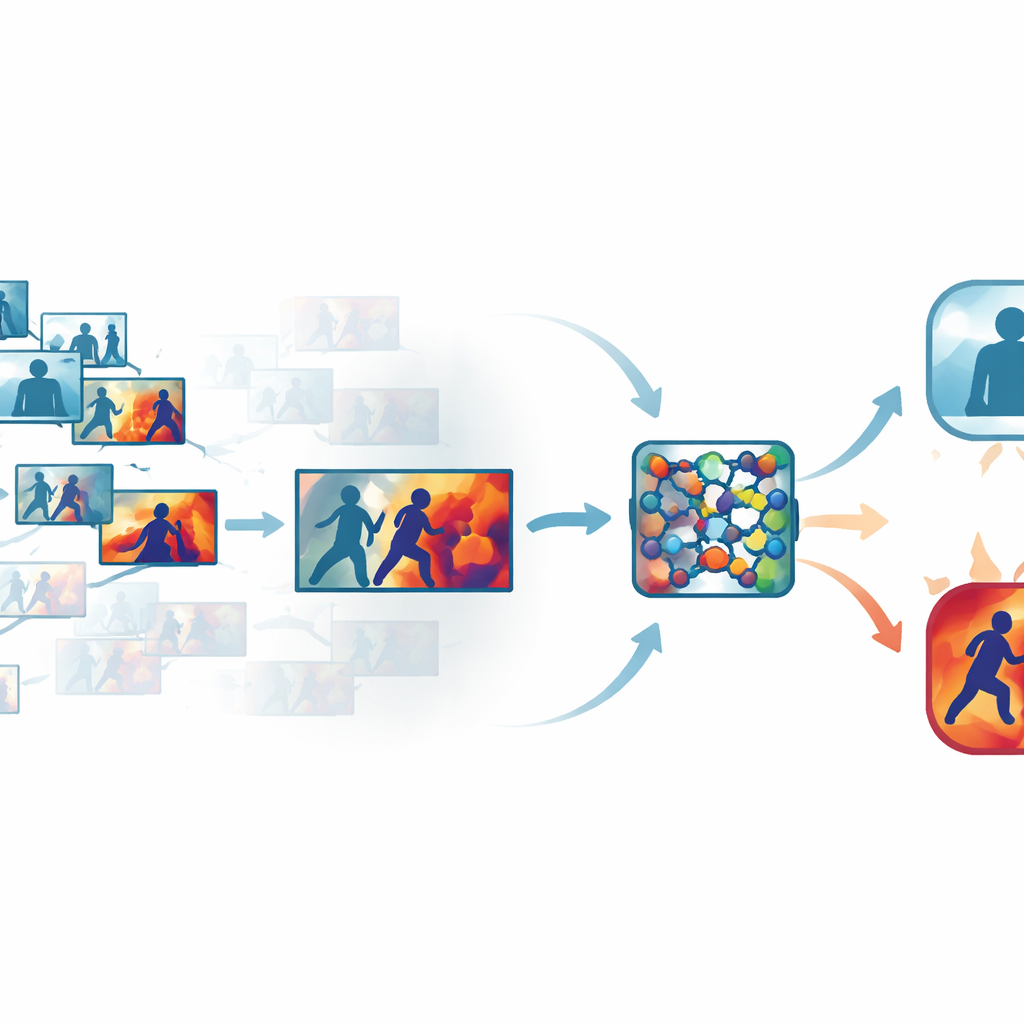
从拥挤视频中去除冗余
标准安防录像包含大量几乎相同的帧,例如长时间的行走或站立画面。处理每一帧既浪费时间又耗费计算资源,但过度跳帧又可能错过挥拳的一瞬。作者通过自动化的“关键帧”步骤来解决这一矛盾,该步骤筛选每个片段,仅保留真正不同的帧。系统不依赖简单的基于时间的采样,而是在一个学习到的视觉空间中比较帧,使运动或姿态上的细微但有意义的变化得以显现。在多个公开数据集上,此方法仅保留了大约三分之一的原始帧,同时保留了表明暴力的短促运动片段。
教网络该看哪里
在选定最有信息量的帧后,这些帧会被送入紧凑的卷积神经网络——一种常用的图像识别工具。在此基础上,作者加入了注意力模块,类似于网络内部的聚光灯。一个模块衡量哪些特征通道承载了重要的运动与形状信息,另一个则强调每帧中发生交互的具体区域。网络不再将所有像素与内部信号视为同等重要,而是学习关注快速移动的手臂、紧密接触的身体以及其它典型模式,同时弱化静态背景、光照变化或摄像机抖动的影响。这使模型在复杂的真实场景中既更准确又更鲁棒。
让机器的推理可见
为避免黑箱设计,该框架内置了一层可解释性机制,即Grad-CAM++。在网络做出决策后,这一工具追溯其内部活动,生成每帧的热图,突出对“暴力”或“非暴力”判定影响最大的区域。在暴力片段中,亮区通常聚集在身体接触点和剧烈运动处;在平静片段中,突出区域则较弱且分散。这些可视化解释帮助操作员确认系统关注的是有意义的行为而非无关线索,也能在司法审查中作为辅助材料——在那种情境下,理解算法如何得出结论与结论本身同样重要。
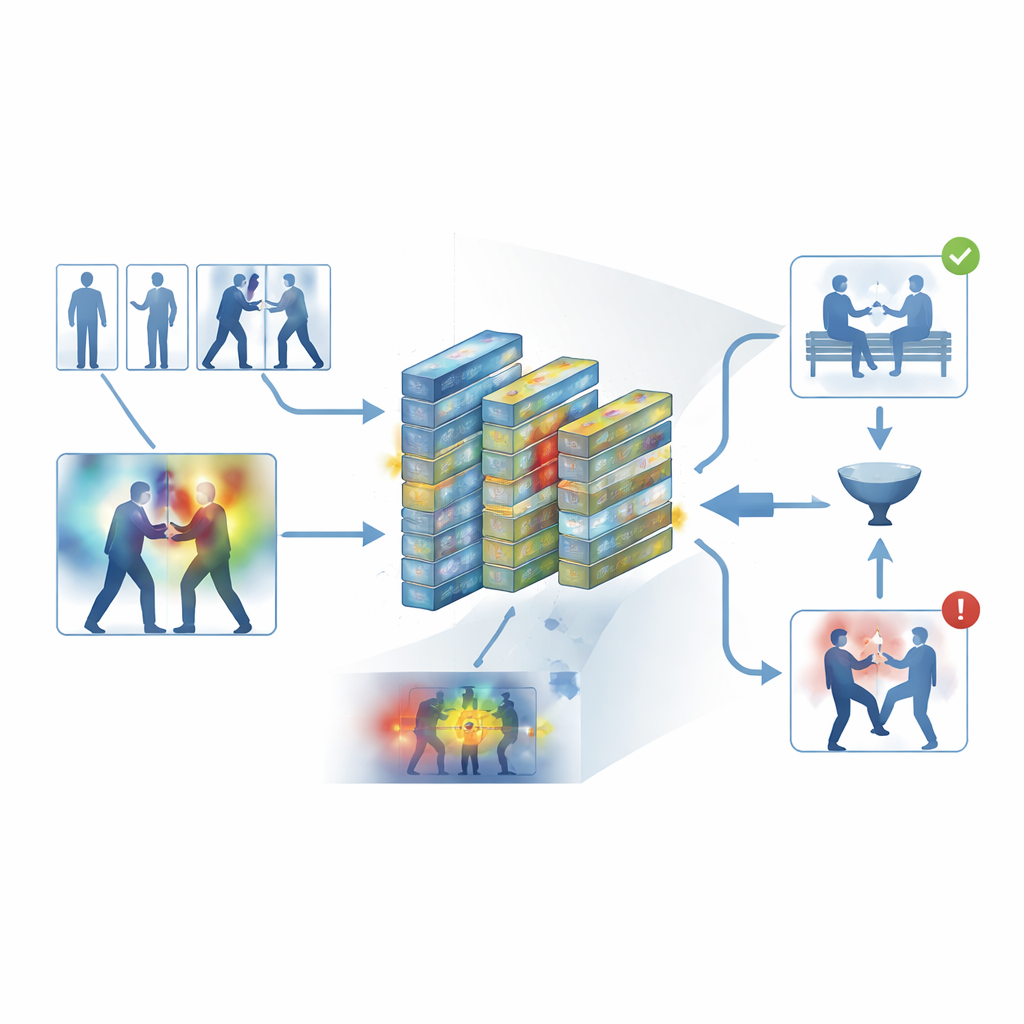
把系统投入测试
作者在五个广泛使用的数据集上训练并评估了他们的框架,这些数据集涵盖日常记录和专用监控录像,包括街头冲突、冰球比赛、拥挤的校园以及长时安防视频。跨越这些不同来源,系统平均准确率约为95%,在现代硬件上处理速度约为每秒62帧——足以用于实时监控。它持续超过了若干强基线方法,如3D卷积网络、CNN–LSTM混合模型和基于Transformer的视频模型,同时占用更少内存。细致的实验表明,关键帧过滤和注意力模块对性能都有统计学上显著的贡献,且模型在一个数据集上训练后迁移到另一个数据集时表现也较为良好。
这对更安全、更透明的监控意味着什么
对非专业读者来说,核心信息是作者构建了一个不仅快速且准确、而且可解释的视频暴力检测器。通过剔除冗余帧、将内部注意力聚焦于最相关的运动,并可视化其“观看”何处以做出判断,系统为人工监督者提供了更透明的辅助工具。在实践中,这可以帮助安防中心和在线平台以更少的误报扫描更多视频流,同时仍允许人们检查和质疑机器的判断。该工作指向未来结合视频、音频与新型时序模型的系统,但其主要贡献是展示了在设计用于维护公共空间和数字平台安全的人工智能工具时,效率与可解释性可以并存。
引用: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
关键词: 视频监控, 暴力检测, 可解释人工智能, 基于注意力的卷积神经网络, 公共安全