Clear Sky Science · it
Un quadro di deep learning interpretabile per la rilevazione di violenza nei video mediante selezione non supervisionata di keyframe e CNN con attention
Perché controlli video più intelligenti sono importanti
Miliardi di ore di video scorrono ogni giorno da telecamere di strada, stadi e social media. Nella massa si nascondono brevi momenti di violenza che sono cruciali per polizia, team di sicurezza e piattaforme online. Gli operatori umani non possono osservare tutto, e i sistemi di intelligenza artificiale attuali che segnalano scene pericolose spesso funzionano come scatole nere: possono essere precisi, ma raramente spiegano perché hanno giudicato un clip violento. Questo articolo presenta un nuovo framework di IA che non solo individua la violenza in modo rapido e accurato, ma mette anche in evidenza le parti di ogni frame che hanno guidato la decisione, aiutando le persone a fidarsi e verificare ciò che la macchina vede.
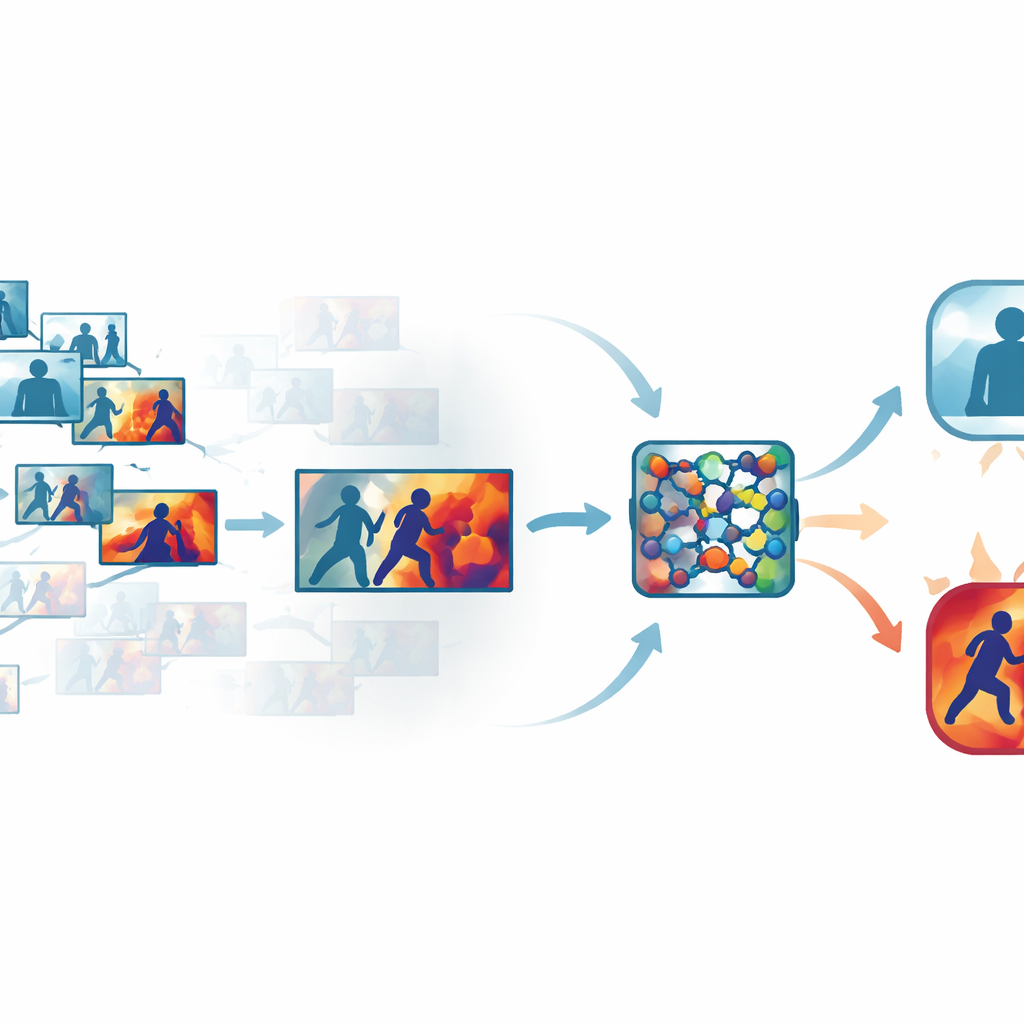
Eliminare il superfluo nei video affollati
I filmati di sicurezza standard contengono molti frame quasi identici, come lunghe sequenze di persone che camminano o stanno in piedi. Elaborare ogni singolo frame spreca tempo e risorse di calcolo, ma saltarne troppi può far perdere il frazione di secondo in cui viene sferrato un pugno. Gli autori affrontano questo problema con una fase automatica di selezione dei “keyframe” che setaccia ogni clip e conserva solo i fotogrammi che differiscono realmente l’uno dall’altro. Invece di affidarsi a un campionamento basato sul tempo, il sistema confronta i frame in uno spazio visivo appreso, dove cambiamenti sottili ma significativi nel movimento o nella postura emergono con maggiore chiarezza. Su diversi dataset pubblici, questo approccio ha mantenuto solo circa un terzo dei frame originali preservando però le brevi esplosioni di movimento che segnalano violenza.
Insegnare alla rete dove guardare
Una volta scelti i frame più informativi, essi vengono elaborati da una compatta rete neurale convoluzionale, un componente comune per il riconoscimento delle immagini. Qui gli autori aggiungono moduli di attention che funzionano come un faro all’interno della rete. Una parte di questo faro pesa quali canali di feature trasportano informazioni importanti su movimento e forma, mentre un’altra enfatizza le regioni specifiche di ciascun frame dove avvengono le interazioni. Invece di trattare tutti i pixel e tutti i segnali interni come ugualmente importanti, la rete impara a concentrarsi su braccia in rapido movimento, corpi in stretto contatto e altri schemi indicativi, attenuando sfondi statici, cambiamenti di illuminazione o vibrazioni della camera. Ciò rende il modello sia più accurato sia più robusto in scene disordinate e del mondo reale.
Rendere visibile il ragionamento della macchina
Per evitare un design a scatola nera, il framework integra uno strato di interpretabilità noto come Grad-CAM++. Dopo che la rete prende una decisione, questo strumento ricostruisce l’attività interna per produrre una heatmap su ogni frame, evidenziando le aree che hanno maggiormente influenzato il verdetto “violento” o “non violento”. Nei clip violenti, le regioni luminose tendono a raggrupparsi attorno ai punti di contatto fisico e al movimento intenso; nei clip tranquilli, gli evidenziatori rimangono deboli e diffusi. Queste spiegazioni visive aiutano gli operatori a confermare che il sistema si sta concentrando su comportamenti significativi piuttosto che su segnali irrilevanti, e possono anche servire come materiale di supporto nelle revisioni forensi, dove capire come un algoritmo è giunto a una conclusione è importante tanto quanto la conclusione stessa.
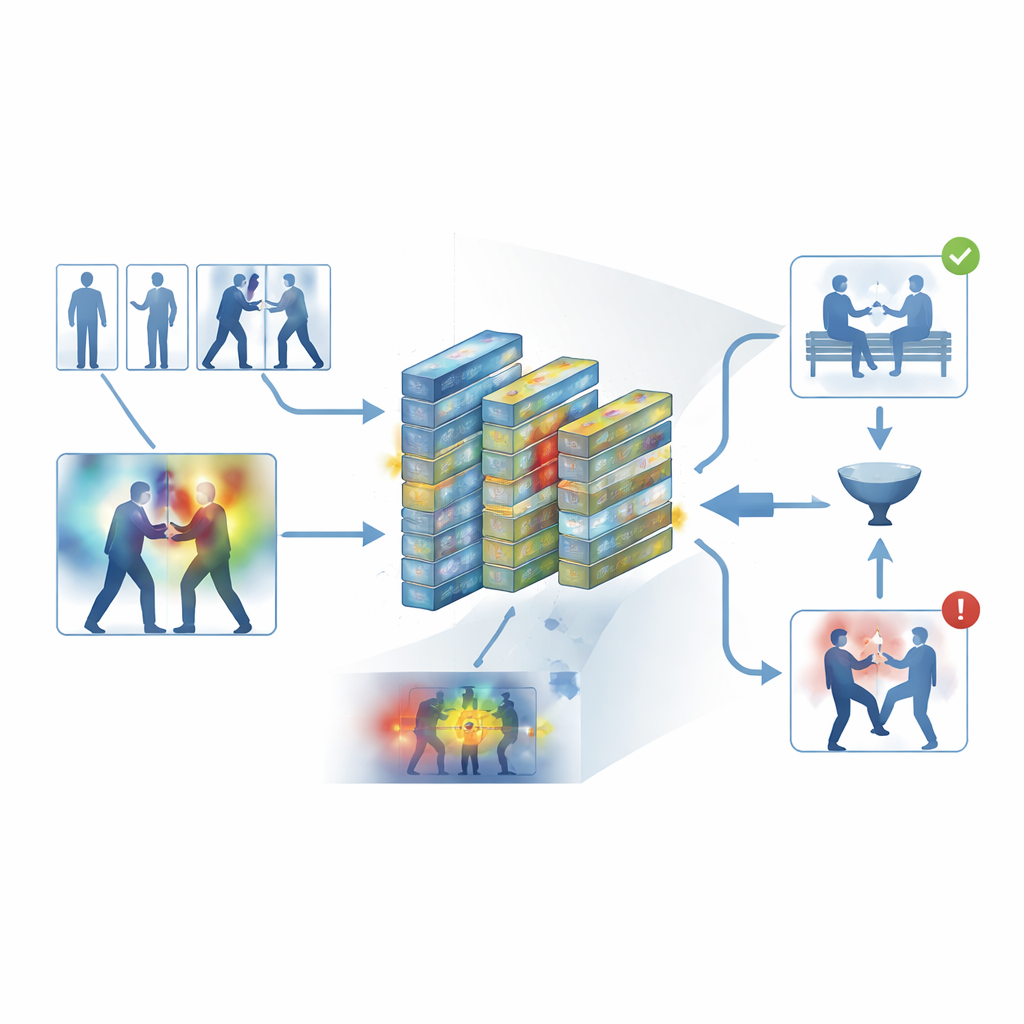
Mettere il sistema alla prova
Gli autori hanno addestrato e valutato il loro framework su cinque dataset ampiamente usati che coprono sia registrazioni quotidiane sia filmati di sorveglianza dedicati, inclusi scontri di strada, partite di hockey, campus affollati e lunghi video di sicurezza. Su queste fonti eterogenee, il sistema ha raggiunto un’accuratezza media di circa il 95 percento e ha elaborato circa 62 frame al secondo su hardware moderno—abbastanza veloce per il monitoraggio in tempo reale. Ha costantemente superato diversi forti baseline, come reti convoluzionali 3D, ibridi CNN–LSTM e modelli video basati su transformer, pur usando meno memoria. Esperimenti accurati hanno mostrato che sia il filtro dei keyframe sia i moduli di attention hanno dato contributi statisticamente significativi alle prestazioni, e che il modello si è trasferito in modo ragionevole quando addestrato su un dataset e testato su un altro.
Cosa significa per un monitoraggio più sicuro e trasparente
Per i non specialisti, il messaggio chiave è che gli autori hanno costruito un rivelatore di violenza nei video che non è solo veloce e accurato, ma anche interpretabile. Eliminando i frame ridondanti, concentrando l’attenzione interna sul movimento più rilevante e poi visualizzando ciò che la rete “ha guardato” per prendere ogni decisione, il sistema offre un partner più trasparente per gli operatori umani. In termini pratici, questo potrebbe aiutare centri di sicurezza e piattaforme online a monitorare più flussi con meno falsi allarmi, permettendo al contempo alle persone di ispezionare e mettere in discussione i giudizi della macchina. Il lavoro apre la strada a sistemi futuri che combinano video, audio e nuovi modelli temporali, ma il contributo principale è dimostrare che efficienza e chiarezza possono coesistere negli strumenti di IA progettati per rendere più sicuri gli spazi pubblici e le piattaforme digitali.
Citazione: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
Parole chiave: videosorveglianza, rilevazione della violenza, IA interpretabile, CNN con attention, sicurezza pubblica