Clear Sky Science · ru
Объяснимая система глубокого обучения для обнаружения насилия в видео с использованием ненадзорного отбора ключевых кадров и CNN с вниманием
Почему умная проверка видео важна
Ежедневно снимаются миллиарды часов видеопотока с уличных камер, стадионов и социальных сетей. В этом потоке скрываются краткие эпизоды насилия, которые имеют большое значение для полиции, служб безопасности и онлайн-платформ. Человеческие операторы не способны просматривать всё, а современные системы искусственного интеллекта, помечающие опасные сцены, часто ведут себя как «чёрные ящики»: они могут быть точными, но редко показывают, почему ролик признан насильственным. В этой статье предложена новая рамочная система ИИ, которая не только быстро и точно обнаруживает насилие, но и выделяет части каждого кадра, повлиявшие на решение, что помогает людям доверять и проверять то, что видит машина.
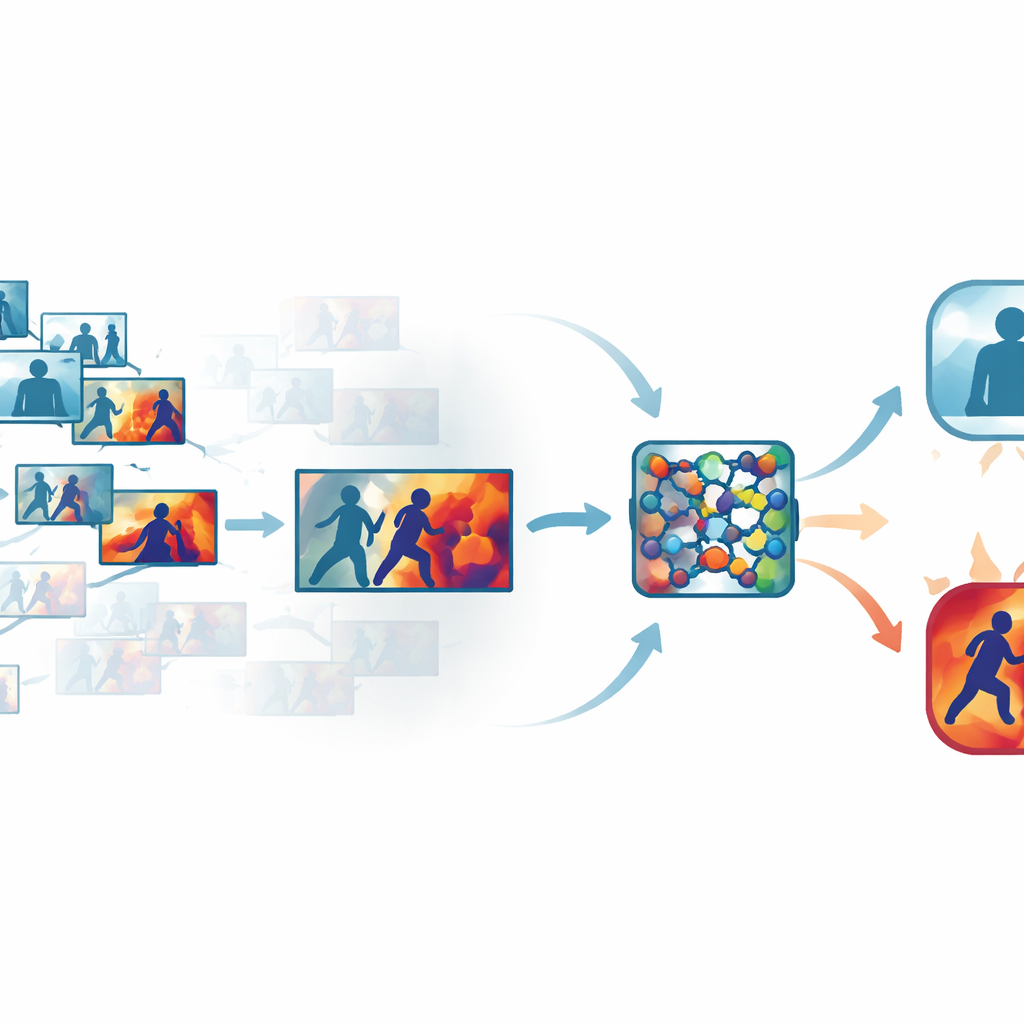
Отсечение шума в загруженном видео
Обычные записи с камер безопасности содержат много почти идентичных кадров, например длительные эпизоды, где люди просто идут или стоят. Обработка каждого кадра тратит время и ресурсы, но чрезмерное пропускание может упустить долю секунды, когда наносится удар. Авторы решают эту проблему с помощью автоматического этапа выбора «ключевых кадров», который просеивает каждый клип и сохраняет только действительно отличающиеся кадры. Вместо простого выборочного сэмплирования по времени система сравнивает кадры в обученном визуальном пространстве, где тонкие, но значимые изменения в движении или позе становятся заметнее. На нескольких общедоступных наборах данных такой подход сохранил примерно треть исходных кадров, при этом сохраняя короткие всплески движения, сигнализирующие о насилии.
Обучение сети тому, куда смотреть
После выбора наиболее информативных кадров они подаются в компактную сверточную нейронную сеть — распространённый инструмент распознавания изображений. Авторы добавляют модули внимания, которые действуют как прожектор внутри сети. Одна часть этого «прожектора» взвешивает, какие каналы признаков содержат важную информацию о движении и форме, а другая подчёркивает конкретные области кадра, где происходят взаимодействия. Вместо того чтобы считать все пиксели и внутренние сигналы одинаково важными, сеть учится фокусироваться на быстро движущихся руках, телах при тесном контакте и других характерных паттернах, одновременно ослабляя влияние статичных фонов, изменений освещения или дрожания камеры. Это делает модель как более точной, так и более устойчивой в шумных, реальных сценах.
Сделать рассуждения машины видимыми
Чтобы избежать конструкции «чёрного ящика», в систему встроен слой интерпретируемости, известный как Grad-CAM++. После того как сеть принимает решение, этот инструмент прослеживает внутреннюю активность и создаёт тепловую карту для каждого кадра, выделяя области, которые наиболее повлияли на вердикт «насильственно» или «не насильственно». В насильственных клипах яркие области обычно сосредоточены вокруг точек физического контакта и интенсивного движения; в спокойных роликах подсветка остаётся слабой и рассеянной. Эти визуальные объяснения помогают операторам убедиться, что система ориентируется на значимое поведение, а не на посторонние признаки, и могут служить вспомогательным материалом при судебной экспертизе, где понимание того, как алгоритм пришёл к выводу, так же важно, как и сам вывод.
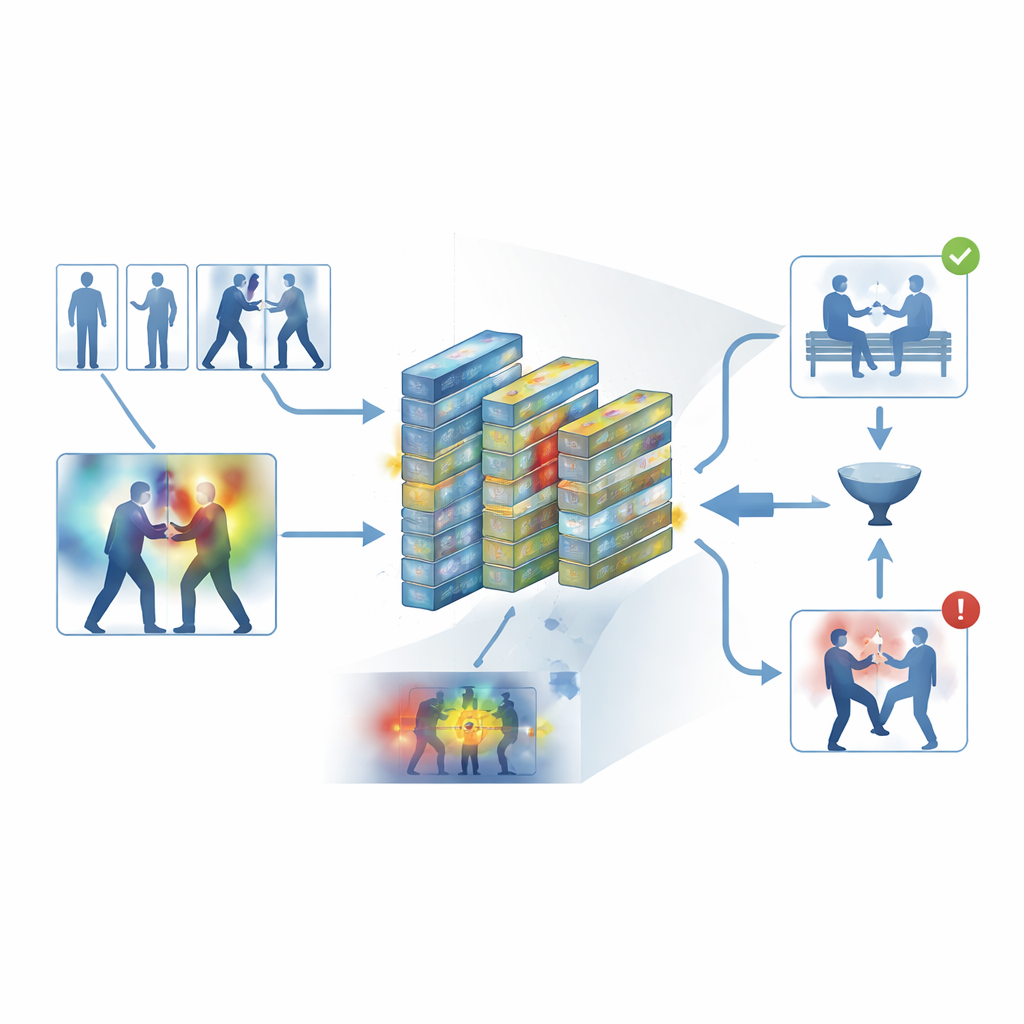
Испытание системы
Авторы обучали и оценивали свою систему на пяти широко используемых наборах данных, охватывающих повседневные записи и специализированные съёмки наблюдения: уличные стычки, хоккейные матчи, переполненные кампусы и длинные записи с охранных видеокамер. По этим разным источникам система показала среднюю точность около 95 процентов и обрабатывала примерно 62 кадра в секунду на современном оборудовании — достаточно быстро для мониторинга в реальном времени. Она последовательно превосходила несколько сильных базовых алгоритмов, таких как 3D-свёрточные сети, гибриды CNN–LSTM и видеотрансформеры, при этом потребляя меньше памяти. Тщательные эксперименты показали, что и фильтр ключевых кадров, и модули внимания вносили статистически значимый вклад в производительность, а модель достаточно хорошо переносилась при обучении на одном наборе данных и тестировании на другом.
Что это значит для более безопасного и прозрачного наблюдения
Для неспециалистов главный вывод заключается в том, что авторы создали детектор насилия в видео, который не только быстрый и точный, но и объяснимый. Устраняя избыточные кадры, фокусируя внутреннее внимание на наиболее релевантном движении и визуализируя то, «на что он смотрел», чтобы вынести каждое решение, система предлагает более прозрачного партнёра для человеческих наблюдателей. На практике это может помочь центрам безопасности и онлайн-платформам просматривать больше потоков с меньшим числом ложных тревог, при этом позволяя людям проверять и оспаривать суждения машины. Работа указывает путь к будущим системам, сочетающим видео, аудио и новые временные модели, но её основной вклад — демонстрация того, что эффективность и ясность могут сосуществовать в инструментах ИИ, предназначенных для обеспечения безопасности общественных пространств и цифровых платформ.
Цитирование: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
Ключевые слова: видеонаблюдение, обнаружение насилия, объяснимый ИИ, CNN с механизмом внимания, общественная безопасность