Clear Sky Science · pt
Uma estrutura de aprendizado profundo explicável para detecção de violência em vídeo usando seleção não supervisionada de quadros-chave e CNN com atenção
Por que verificações de vídeo mais inteligentes importam
Bilhões de horas de vídeo fluem diariamente de câmeras de rua, estádios e das redes sociais. Ocultos nessa enxurrada estão momentos breves de violência que importam profundamente para a polícia, equipes de segurança e plataformas online. Operadores humanos não conseguem assistir a tudo, e os sistemas de inteligência artificial atuais que sinalizam cenas perigosas frequentemente funcionam como caixas-pretas: podem ser precisos, mas raramente mostram por que decidiram que um clipe era violento. Este artigo apresenta uma nova estrutura de IA que não apenas detecta violência de forma rápida e precisa, mas também destaca as partes de cada quadro que motivaram sua decisão, ajudando as pessoas a confiar e verificar o que a máquina vê.
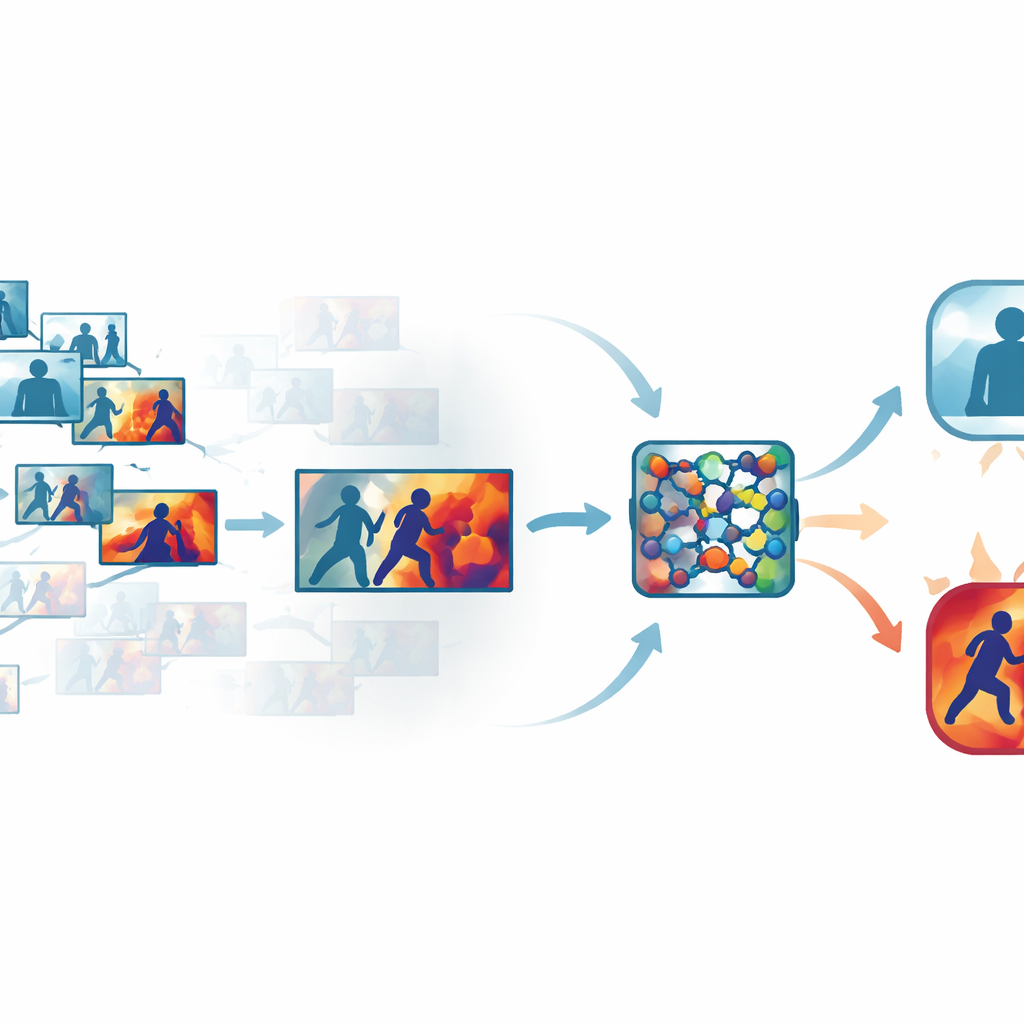
Eliminando ruído em vídeos lotados
Filmagens de segurança padrão contêm muitos quadros praticamente idênticos, como longos trechos de pessoas apenas caminhando ou paradas. Processar todo quadro desperdiça tempo e poder de computação, mas pular demais pode perder o segundo em que um soco é desferido. Os autores enfrentam isso usando uma etapa automatizada de “quadros-chave” que peneira cada clipe e mantém apenas os quadros que realmente diferem uns dos outros. Em vez de depender de amostragem simples baseada em tempo, o sistema compara quadros em um espaço visual aprendido, onde mudanças sutis mas significativas em movimento ou postura se destacam. Em vários conjuntos de dados públicos, essa abordagem manteve apenas cerca de um terço dos quadros originais enquanto preservava os curtos surtos de movimento que sinalizam violência.
Ensinando a rede onde olhar
Uma vez escolhidos os quadros mais informativos, eles são enviados por uma rede neural convolucional compacta, um componente comum em reconhecimento de imagem. Aqui os autores adicionam módulos de atenção que funcionam como um holofote dentro da rede. Uma parte desse holofote pondera quais canais de características carregam informações importantes de movimento e forma, enquanto outra enfatiza as regiões específicas de cada quadro onde ocorrem interações. Em vez de tratar todos os pixels e todos os sinais internos como igualmente importantes, a rede aprende a focar em braços que se movem rapidamente, corpos em contato próximo e outros padrões indicativos, enquanto rebaixa fundos estáticos, variações de iluminação ou tremores de câmera. Isso torna o modelo tanto mais preciso quanto mais robusto em cenas reais e desordenadas.
Tornando o raciocínio da máquina visível
Para evitar um design em caixa-preta, a estrutura incorpora uma camada de interpretabilidade conhecida como Grad-CAM++. Depois que a rede toma uma decisão, essa ferramenta rastreia sua atividade interna para produzir um mapa de calor sobre cada quadro, destacando áreas que mais influenciaram o veredicto “violento” ou “não violento”. Em clipes violentos, as regiões brilhantes tendem a se agrupar em pontos de contato físico e movimentos intensos; em clipes calmos, os destaques permanecem fracos e difusos. Essas explicações visuais ajudam os operadores a confirmar que o sistema está se concentrando em comportamentos significativos em vez de sinais irrelevantes, e também podem servir como material de apoio em análises forenses, nas quais entender como um algoritmo chegou à sua conclusão é tão importante quanto a própria conclusão.
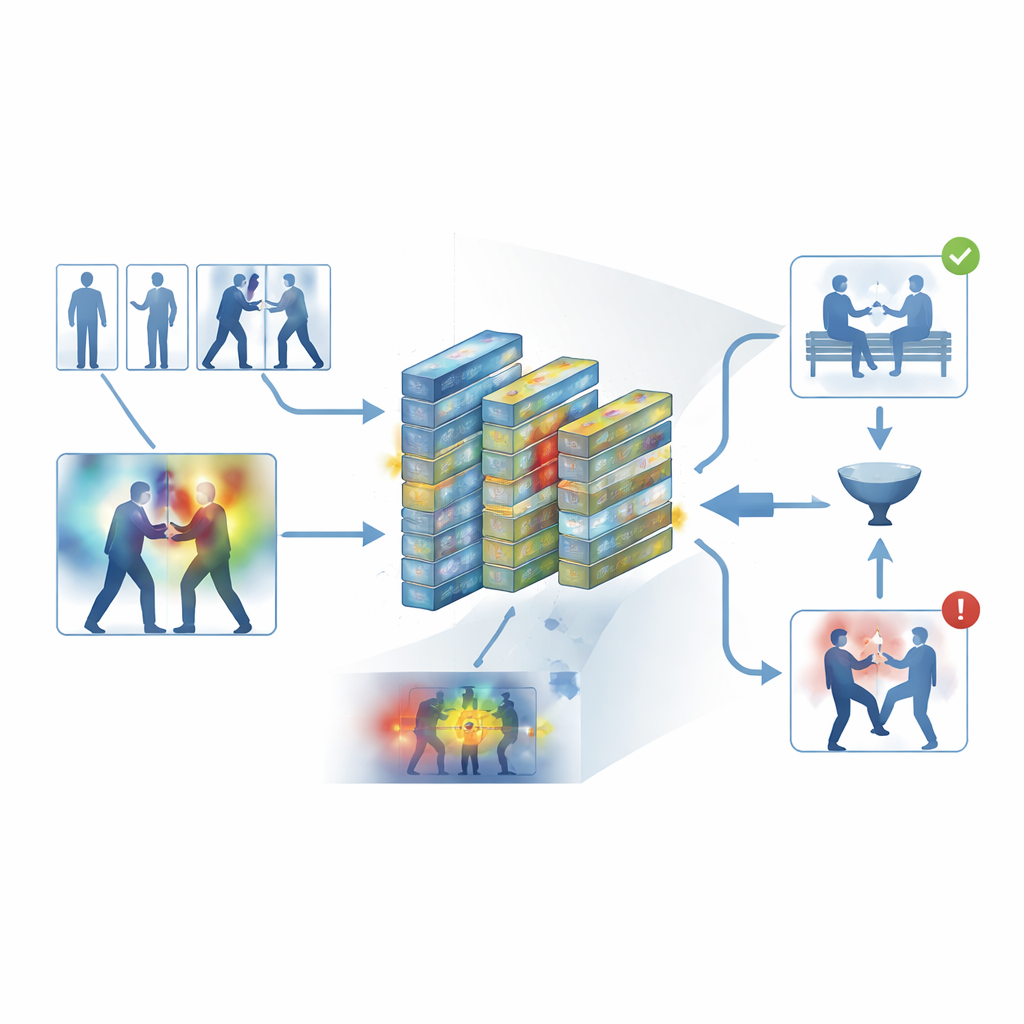
Submetendo o sistema ao teste
Os autores treinaram e avaliaram sua estrutura em cinco conjuntos de dados amplamente utilizados que abrangem tanto gravações do cotidiano quanto filmagens de vigilância dedicadas, incluindo altercações nas ruas, partidas de hóquei, campi lotados e vídeos longos de segurança. Nestas fontes diversas, o sistema alcançou uma precisão média de cerca de 95% e processou aproximadamente 62 quadros por segundo em hardware moderno—rápido o suficiente para monitoramento em tempo real. Ele superou consistentemente várias linhas de base fortes, como redes de convolução 3D, híbridos CNN–LSTM e modelos de vídeo baseados em transformers, enquanto usava menos memória. Experimentos cuidadosos mostraram que tanto o filtro de quadros-chave quanto os módulos de atenção deram contribuições estatisticamente significativas para o desempenho, e que o modelo se transferiu razoavelmente bem quando treinado em um conjunto de dados e testado em outro.
O que isso significa para uma vigilância mais segura e clara
Para não especialistas, a mensagem principal é que os autores construíram um detector de violência em vídeo que não é apenas rápido e preciso, mas também explicável. Ao eliminar quadros redundantes, concentrar sua atenção interna no movimento mais relevante e então visualizar o que “olhou” para tomar cada decisão, o sistema oferece um parceiro mais transparente para supervisores humanos. Em termos práticos, isso pode ajudar centros de segurança e plataformas online a vasculhar mais transmissões com menos falsos alarmes, ao mesmo tempo em que permite que as pessoas inspecionem e questionem os julgamentos da máquina. O trabalho aponta para sistemas futuros que combinem vídeo, áudio e modelos temporais mais recentes, mas sua contribuição principal é mostrar que eficiência e clareza podem coexistir em ferramentas de IA projetadas para tornar espaços públicos e plataformas digitais mais seguros.
Citação: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
Palavras-chave: vigilância por vídeo, detecção de violência, IA explicável, CNN com atenção, segurança pública