Clear Sky Science · es
Un marco de aprendizaje profundo explicable para la detección de violencia en vídeo mediante selección no supervisada de fotogramas clave y CNN basada en atención
Por qué importan comprobaciones de vídeo más inteligentes
Miles de millones de horas de vídeo procedentes de cámaras callejeras, estadios y redes sociales se transmiten cada día. Ocultos en esa avalancha hay breves episodios de violencia que importan mucho a la policía, a los equipos de seguridad y a las plataformas en línea. Los operadores humanos no pueden verlo todo, y los sistemas de inteligencia artificial actuales que señalan escenas peligrosas a menudo funcionan como cajas negras: pueden ser precisos, pero rara vez muestran por qué decidieron que un clip era violento. Este artículo presenta un nuevo marco de IA que no solo detecta la violencia con rapidez y precisión, sino que también resalta las partes de cada fotograma que motivaron su decisión, ayudando a las personas a confiar y verificar lo que la máquina ve.
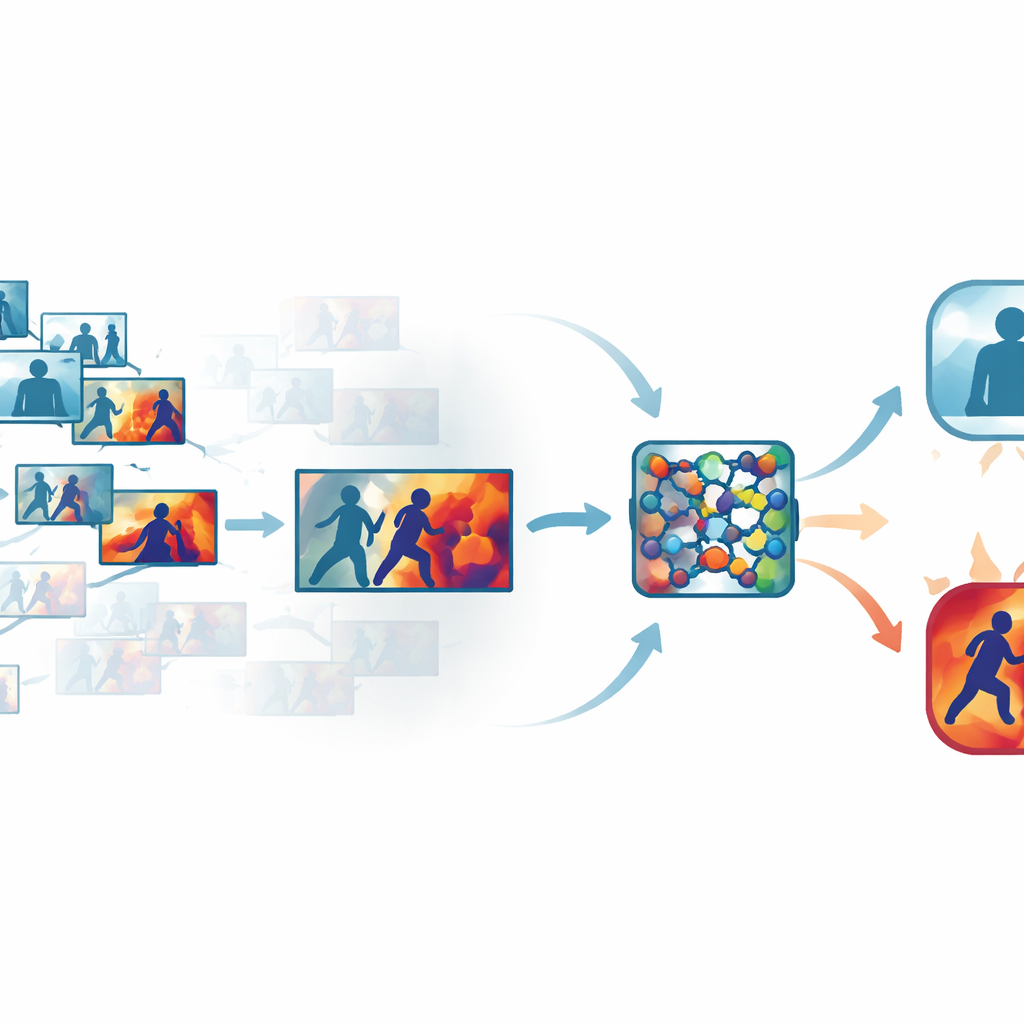
Eliminando el ruido de vídeos concurridos
Las grabaciones de seguridad estándar contienen muchos fotogramas casi idénticos, como largos tramos de personas simplemente caminando o paradas. Procesar cada fotograma desperdicia tiempo y potencia de cálculo, pero saltarse demasiados puede hacer que se pierda la fracción de segundo en que se lanza un puñetazo. Los autores abordan esto mediante un paso automatizado de «fotogramas clave» que tamiza cada clip y conserva solo los fotogramas que realmente difieren entre sí. En lugar de confiar en un muestreo basado en el tiempo, el sistema compara fotogramas en un espacio visual aprendido, donde los cambios sutiles pero significativos en movimiento o postura destacan. En varios conjuntos de datos públicos, este enfoque conservó solo alrededor de un tercio de los fotogramas originales mientras preservaba los ráfagas cortas de movimiento que señalan violencia.
Enseñar a la red dónde mirar
Una vez elegidos los fotogramas más informativos, se envían a través de una red neuronal convolucional compacta, un elemento habitual en el reconocimiento de imágenes. Aquí los autores añaden módulos de atención que actúan como un reflector dentro de la red. Una parte de ese reflector pondera qué canales de características contienen información importante de movimiento y forma, mientras que otra enfatiza las regiones específicas de cada fotograma donde se producen interacciones. En lugar de tratar todos los píxeles y todas las señales internas como igualmente importantes, la red aprende a centrarse en brazos que se mueven rápidamente, cuerpos en contacto cercano y otros patrones reveladores, mientras resta importancia a fondos estáticos, cambios de iluminación o vibraciones de la cámara. Esto hace que el modelo sea tanto más preciso como más robusto en escenas desordenadas y del mundo real.
Haciendo visible el razonamiento de la máquina
Para evitar un diseño de caja negra, el marco incorpora una capa de interpretabilidad conocida como Grad-CAM++. Tras tomar una decisión, esta herramienta rastrea la actividad interna de la red para producir un mapa de calor sobre cada fotograma, destacando las áreas que más influyeron en el veredicto de «violento» o «no violento». En los clips violentos, las regiones brillantes tienden a agruparse alrededor de puntos de contacto físico y movimiento intenso; en los clips tranquilos, los realces permanecen débiles y difusos. Estas explicaciones visuales ayudan a los operadores a confirmar que el sistema se fija en comportamientos significativos en lugar de en indicios irrelevantes, y también pueden servir como material de apoyo en revisiones forenses, donde entender cómo un algoritmo llegó a su conclusión es tan importante como la conclusión misma.
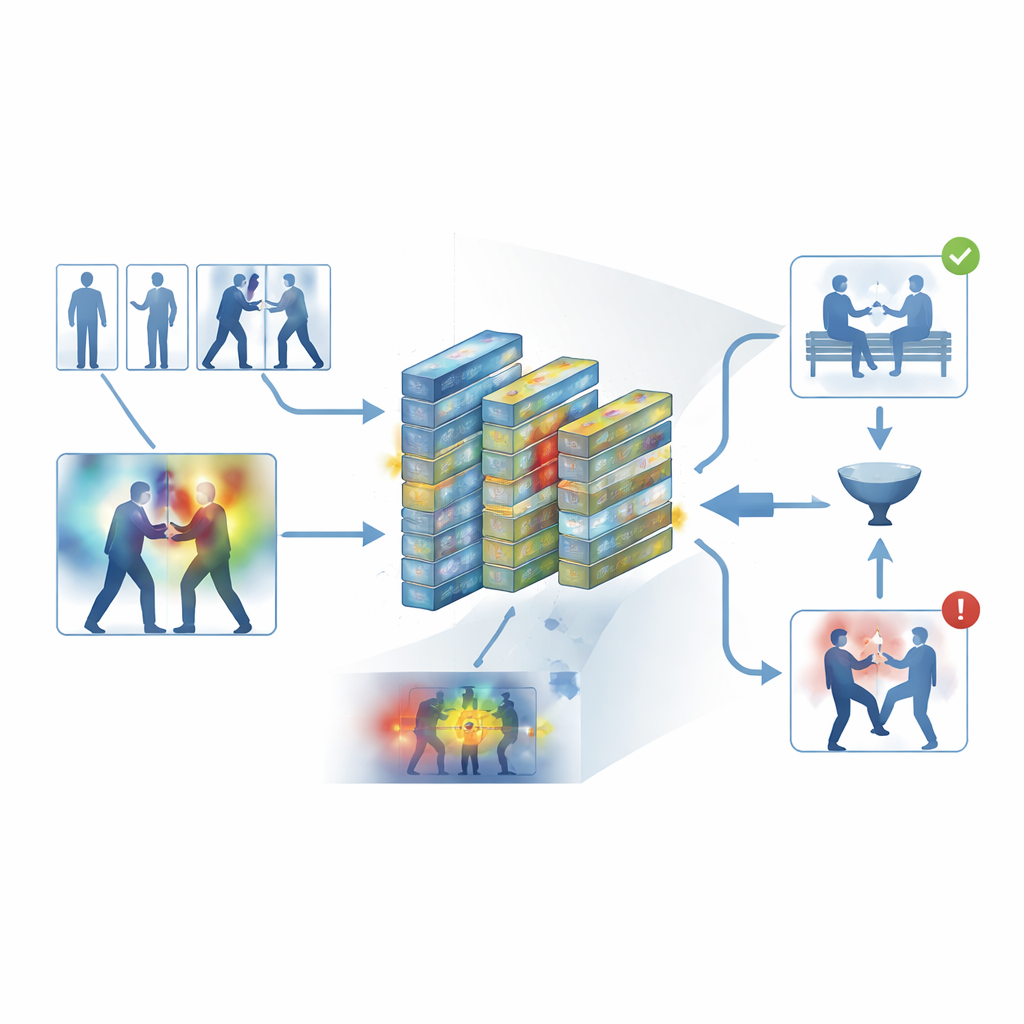
Poniendo el sistema a prueba
Los autores entrenaron y evaluaron su marco en cinco conjuntos de datos ampliamente usados que abarcan tanto grabaciones cotidianas como material de vigilancia dedicado, incluidos altercados callejeros, partidos de hockey, campus concurridos y largos vídeos de seguridad. A través de estas fuentes diversas, el sistema alcanzó una precisión media de aproximadamente el 95 por ciento y procesó alrededor de 62 fotogramas por segundo en hardware moderno, lo bastante rápido para la supervisión en tiempo real. Superó de forma consistente a varias referencias sólidas, como redes de convolución 3D, híbridos CNN–LSTM y modelos de vídeo basados en transformadores, al tiempo que consumía menos memoria. Experimentos cuidadosos mostraron que tanto el filtro de fotogramas clave como los módulos de atención contribuyeron de forma estadísticamente significativa al rendimiento, y que el modelo se trasladó razonablemente bien cuando se entrenó en un conjunto de datos y se probó en otro.
Qué significa esto para una vigilancia más segura y clara
Para el público no especializado, el mensaje clave es que los autores han construido un detector de violencia en vídeo que no solo es rápido y preciso, sino también explicable. Al eliminar fotogramas redundantes, centrar su atención interna en el movimiento más relevante y luego visualizar lo que «miró» para emitir cada veredicto, el sistema ofrece un compañero más transparente para los supervisores humanos. En términos prácticos, esto podría ayudar a centros de seguridad y plataformas en línea a supervisar más fuentes con menos falsas alarmas, permitiendo a la vez que las personas inspeccionen y cuestionen los juicios de la máquina. El trabajo señala hacia futuros sistemas que combinen vídeo, audio y modelos temporales más recientes, pero su contribución principal es mostrar que la eficiencia y la claridad pueden coexistir en herramientas de IA diseñadas para mantener más seguras las espacios públicos y las plataformas digitales.
Cita: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
Palabras clave: vigilancia por vídeo, detección de violencia, IA explicable, CNN basada en atención, seguridad pública