Clear Sky Science · sv
En förklarbar djupinlärningsram för våldsdetektion i video med oövervakad nyckelbildsval och uppmärksamhetsbaserad CNN
Varför smartare videokontroller spelar roll
Miljarder timmar med videoströmmar från gatukameror, arenor och sociala medier genereras varje dag. Dold i denna flod finns korta våldsamma ögonblick som är av stor betydelse för polis, säkerhetsteam och onlineplattformar. Mänskliga operatörer kan inte bevaka allt, och dagens artificiella intelligenssystem som markerar farliga scener fungerar ofta som svarta lådor: de kan vara träffsäkra, men sällan visar varför de bedömde ett klipp som våldsamt. Denna artikel presenterar en ny AI-ram som inte bara upptäcker våld snabbt och noggrant, utan också markerar de delar av varje bildruta som låg till grund för beslutet, vilket hjälper människor att lita på och verifiera vad maskinen ser.
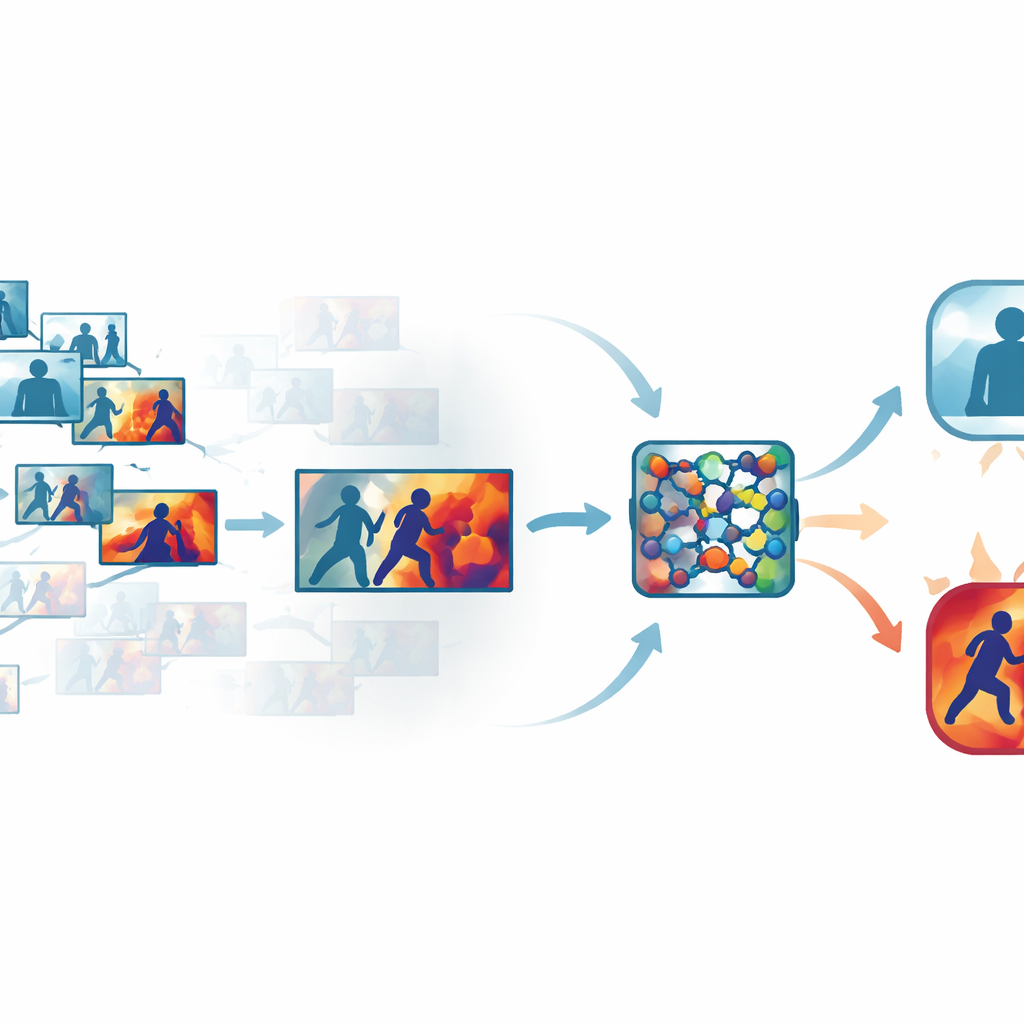
Att minska bruset i trånga videor
Vanlig övervakningsfilm innehåller många nästan identiska bildrutor, till exempel långa sekvenser där människor bara går eller står stilla. Att bearbeta varje ruta slösar tid och beräkningskraft, men att hoppa över för mycket kan missa den bråkdel av en sekund då en knytnäve far iväg. Författarna tacklar detta genom ett automatiserat ”nyckelbilds”-steg som sållar igenom varje klipp och behåller endast de rutor som verkligen skiljer sig åt. Istället för att förlita sig på enkel tidsbaserad sampling jämför systemet rutor i ett inlärt visuellt utrymme, där subtila men betydelsefulla förändringar i rörelse eller kroppsställning träder fram. På flera publika dataset behöll detta tillvägagångssätt bara omkring en tredjedel av de ursprungliga rutorna samtidigt som de korta rörelseutbrott som signalerar våld bevarades.
Att lära nätverket var det ska titta
När de mest informativa rutorna valts skickas de genom ett kompakt konvolutionellt neuralt nätverk, en vanlig motor för bildigenkänning. Här lägger författarna till uppmärksamhetsmoduler som fungerar som en strålkastare inuti nätverket. En del av denna strålkastare väger vilka funktionskanaler som bär viktig rörelse- och forminformation, medan en annan betonar de specifika regionerna i varje ruta där interaktioner sker. Istället för att behandla alla pixlar och interna signaler som lika viktiga lär sig nätverket att fokusera på snabbt rörliga armar, kroppar i nära kontakt och andra karaktäristiska mönster, samtidigt som statiska bakgrunder, ljusförändringar eller kameraskakningar nedtonas. Detta gör modellen både mer precis och mer robust i stökiga, verkliga scener.
Att göra maskinens resonemang synligt
För att undvika en svart-låda-design bygger ramen in ett tolkningsbart lager känt som Grad-CAM++. Efter att nätverket fattat ett beslut spårar detta verktyg tillbaka genom dess interna aktivitet för att producera en värmekarta över varje ruta, som framhäver områden som mest påverkade beslutet "våldsamt" eller "icke-våldsamt". I våldsamma klipp tenderar de ljusa regionerna att samlas kring fysiska kontaktpunkter och intensiv rörelse; i lugna klipp förblir markeringarna svaga och diffusa. Dessa visuella förklaringar hjälper operatörer att bekräfta att systemet fokuserar på meningsfullt beteende snarare än irrelevanta ledtrådar, och kan också fungera som stödmaterial i rättsmedicinsk granskning, där förståelsen för hur en algoritm nådde sin slutsats är lika viktig som slutsatsen i sig.
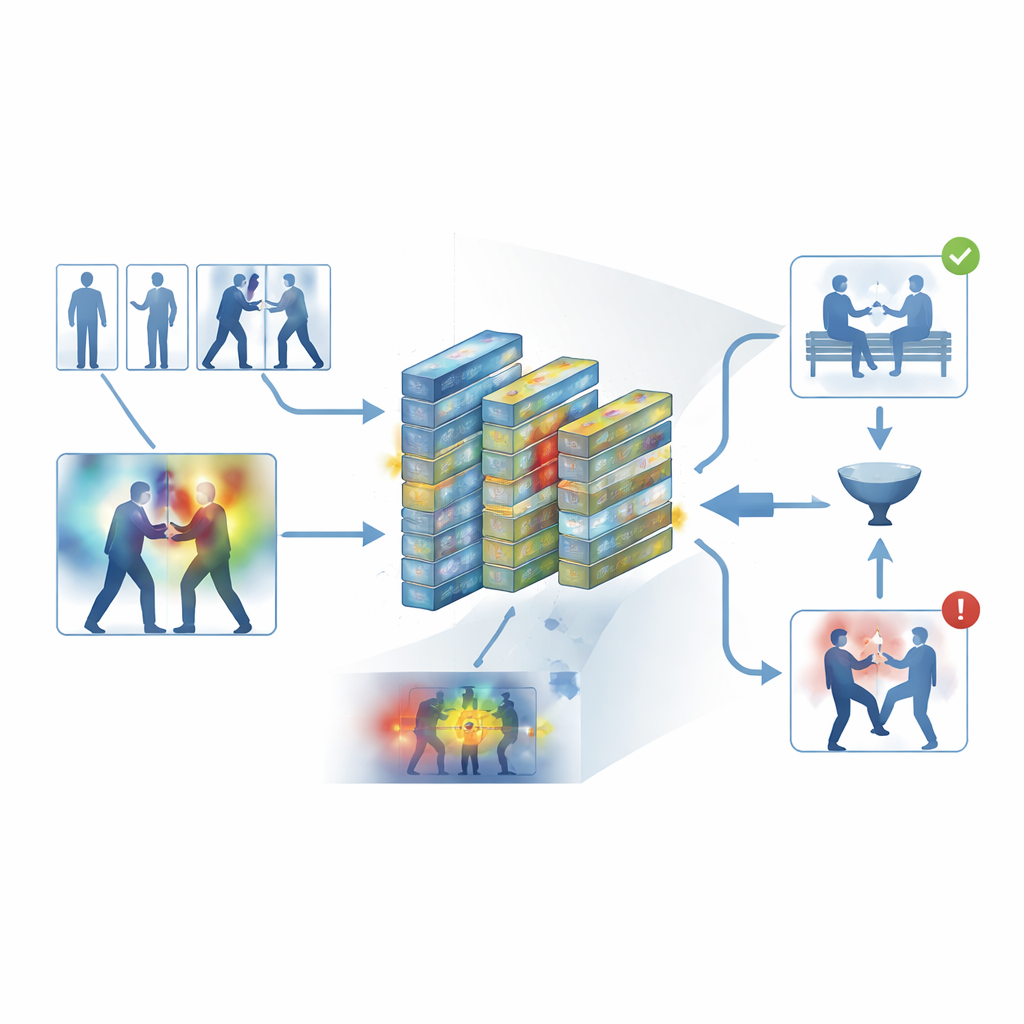
Sätta systemet på prov
Författarna tränade och utvärderade sin ram på fem vida använda dataset som spänner över både vardagliga inspelningar och särskild övervakningsfilm, inklusive gatbråk, hockeymatcher, trånga campus och långa säkerhetsvideor. Över dessa olika källor uppnådde systemet en genomsnittlig noggrannhet på cirka 95 procent och bearbetade runt 62 rutor per sekund på modern hårdvara—tillräckligt snabbt för realtidsövervakning. Det slog konsekvent flera starka baslinjer, såsom 3D-konvolutionella nätverk, CNN–LSTM-hybrider och transformerbaserade videomodeller, samtidigt som det använde mindre minne. Noggrant genomförda experiment visade att både nyckelbildsfiltern och uppmärksamhetsmodulerna gav statistiskt signifikanta bidrag till prestandan, och att modellen överförde sig rimligt väl när den tränades på ett dataset och testades på ett annat.
Vad detta betyder för säkrare, tydligare övervakning
För icke-specialister är huvudbudskapet att författarna har byggt en videovåldsdetektor som inte bara är snabb och exakt utan också förklarbar. Genom att ta bort redundanta rutor, rikta sitt interna fokus mot den mest relevanta rörelsen och sedan visualisera vad den "tittade på" för att fatta varje beslut, erbjuder systemet en mer transparent partner för mänskliga övervakare. I praktiken kan detta hjälpa säkerhetscentraler och onlineplattformar att skanna fler flöden med färre falska larm, samtidigt som människor fortfarande kan granska och ifrågasätta maskinens bedömningar. Arbetet pekar mot framtida system som kombinerar video, ljud och nyare temporala modeller, men dess huvudsakliga bidrag är att visa att effektivitet och tydlighet kan samexistera i AI-verktyg utformade för att göra offentliga platser och digitala plattformar säkrare.
Citering: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
Nyckelord: videoövervakning, våldsdetektering, förklarbar AI, uppmärksamhetsbaserad CNN, allmän säkerhet