Clear Sky Science · ja
教師なしキーフレーム選択と注意機構型CNNを用いたビデオ暴力検出の説明可能な深層学習フレームワーク
なぜ賢い映像監視が重要なのか
街頭カメラ、スタジアム、ソーシャルメディアからは毎日何十億時間もの映像が配信されています。この洪水の中には、警察や警備チーム、オンラインプラットフォームにとって極めて重要な短時間の暴力シーンが潜んでいます。人間の監視員がすべてを見続けることは不可能であり、現在の危険な場面を検出するAIシステムはしばしばブラックボックスのように動作します。正確であっても、なぜそのクリップを暴力的だと判断したのかを示すことは稀です。本稿は、暴力を迅速かつ高精度に検出するだけでなく、各フレームのどの部分が判定に影響したかを可視化して示す、新しいAIフレームワークを提案します。これにより、人が機械の判断を信頼し検証しやすくなります。
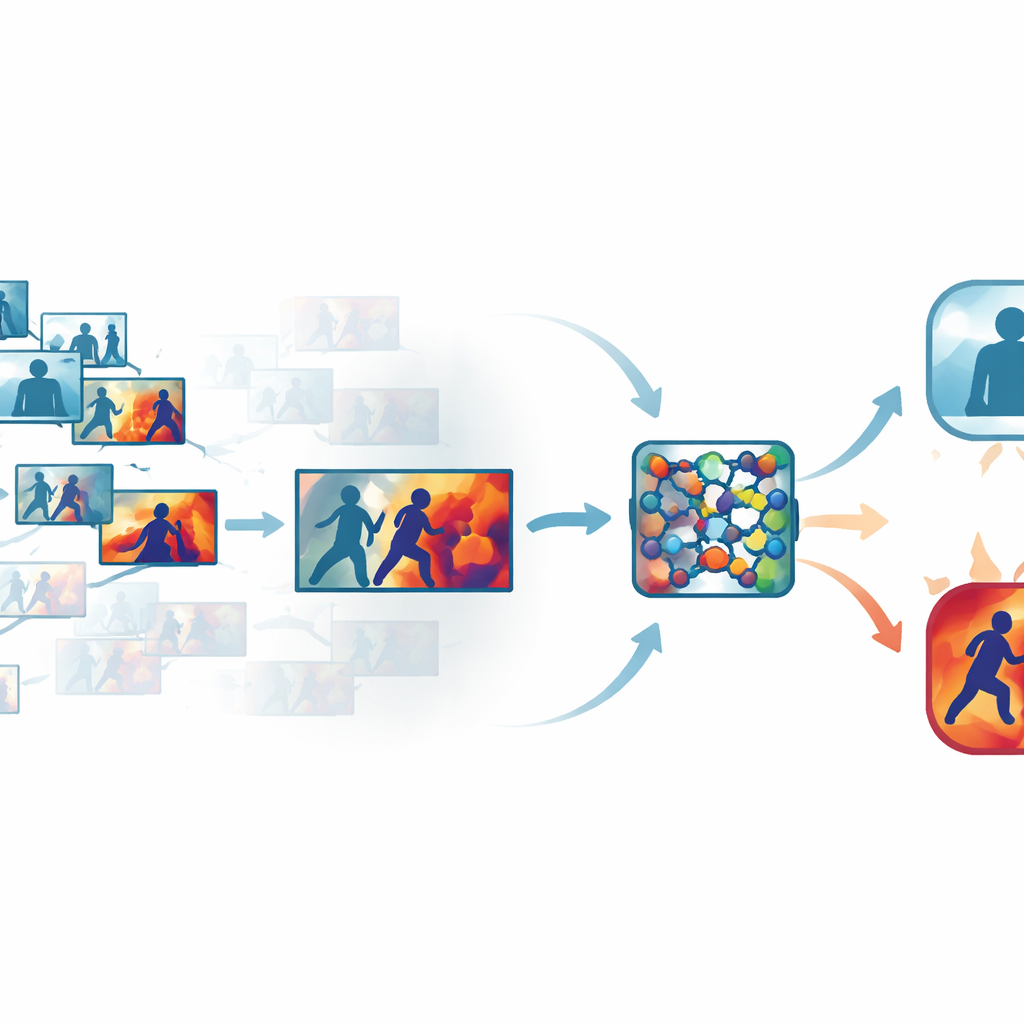
群衆映像からノイズを取り除く
通常の監視映像には、歩行や立ち止まりといったほとんど同一のフレームが長時間続くことが多く、すべてのフレームを処理するのは時間と計算資源の無駄になります。しかし過剰に間引くと、パンチが振るわれる一瞬を見逃す可能性があります。著者らはこれに対処するため、各クリップをふるいにかけて本質的に異なるフレームのみを保持する自動「キーフレーム」処理を導入しました。単純な時間ベースのサンプリングに頼る代わりに、学習された視覚空間でフレーム同士を比較し、動きや姿勢の微妙だが意味ある変化を際立たせます。複数の公開データセットで、この手法は元のフレームの約3分の1のみを保持しつつ、暴力を示す短い動作の急増を保存しました。
ネットワークに注目すべき箇所を教える
最も情報量の多いフレームが選択されると、それらはコンパクトな畳み込みニューラルネットワークに送られます。ここで著者らは、ネットワーク内部にスポットライトのように働く注意モジュールを追加します。このスポットライトの一部は、どの特徴チャネルが重要な動きや形状情報を有しているかを重み付けし、別の部分は各フレームの中で相互作用が起きている具体的な領域を強調します。すべてのピクセルや内部信号を同等に扱う代わりに、ネットワークは素早く動く腕や密接な接触のある身体、その他の決定的パターンに注目し、静的な背景や照明変化、カメラの揺れなどを軽視することを学びます。これにより、雑然とした実世界の映像でもモデルはより高精度かつ堅牢になります。
機械の推論を可視化する
ブラックボックス設計を避けるため、フレームワークにはGrad-CAM++として知られる解釈可能性レイヤーを組み込みます。ネットワークが判定を下した後、このツールは内部の活動を遡って追跡し、各フレーム上にヒートマップを生成して「暴力」「非暴力」の判断に最も影響した領域を強調します。暴力的なクリップでは、明るい領域が身体接触点や激しい動きの周辺に集まる傾向があり、落ち着いたクリップでは強度の弱い拡散したハイライトにとどまります。これらの視覚的説明は、システムが重要な行動に着目していることを確認する助けになるだけでなく、どのようにアルゴリズムが結論に到達したかの理解が結論そのものと同様に重要な法医学的レビューでも補助資料として利用できます。
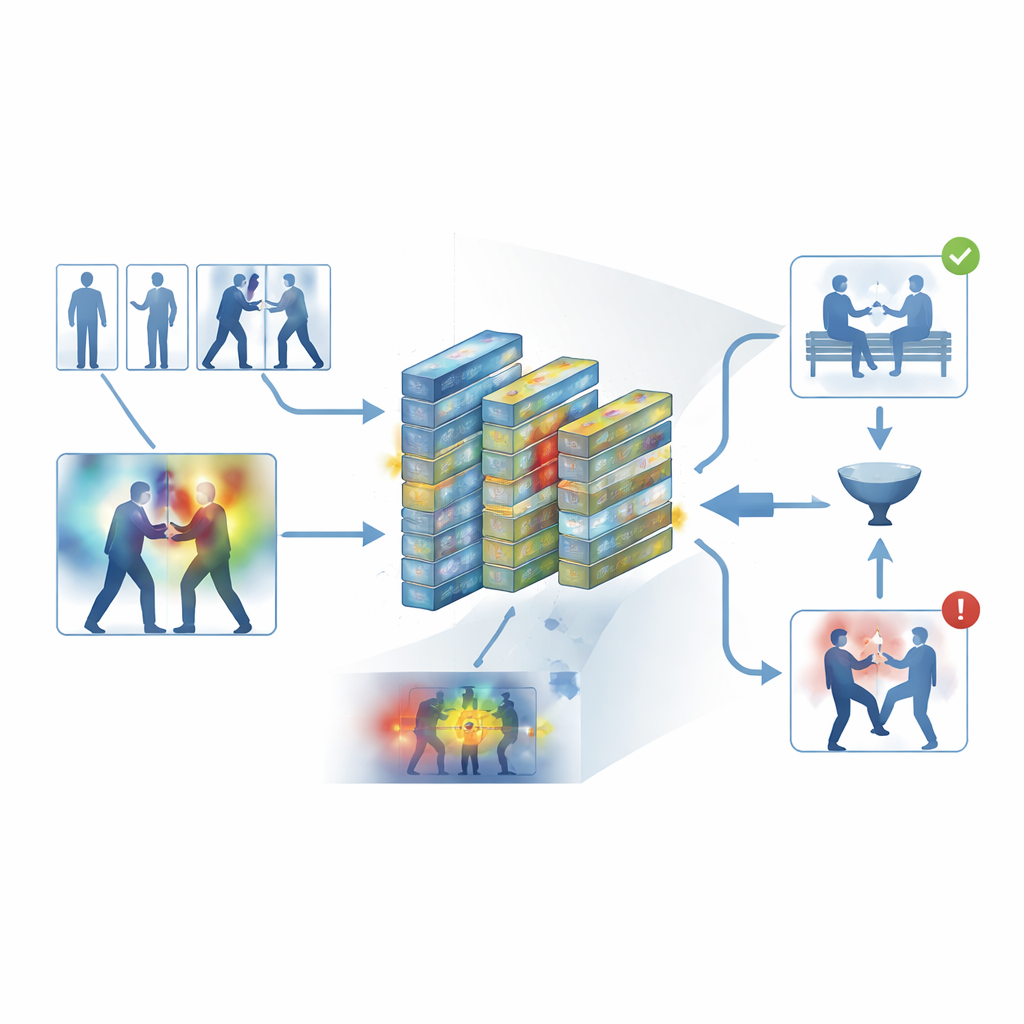
システムの実地評価
著者らは、本フレームワークを日常的な録画と専用監視映像の双方を含む5つの広く使われるデータセットで学習・評価しました。これらは街頭での乱闘、ホッケーの試合、混雑したキャンパス、長時間の監視映像など多様な記録を網羅します。これらの多様なソースにわたり、システムは平均約95パーセントの精度を達成し、最新のハードウェアで秒間約62フレームを処理しました—リアルタイム監視に十分な速度です。3D畳み込みネットワーク、CNN–LSTMのハイブリッド、トランスフォーマーベースの動画モデルなどの強力なベースラインを一貫して上回り、かつメモリ使用量は少なくて済みました。詳細な実験により、キーフレームフィルタと注意モジュールの双方が性能に統計的に有意な寄与をしていること、またあるデータセットで学習したモデルが別のデータセットで比較的よく転移することが示されました。
より安全で明瞭な監視のために意味すること
専門外の読者にとっての要点は、著者らが高速かつ高精度であるだけでなく説明可能なビデオ暴力検出器を構築したという点です。冗長なフレームを取り除き、内部の注意を最も関連性の高い動きへ向け、そのうえで各判定において「どこを見たか」を可視化することで、本システムは人間の監視者にとってより透明なパートナーを提供します。実務的には、セキュリティセンターやオンラインプラットフォームが誤検知を減らしつつより多くのフィードを効率的にスキャンできるようになり、同時に人が機械の判断を点検・問うことも可能になります。本研究は映像と音声や新しい時間的モデルを組み合わせた将来のシステムへの道を示唆しますが、その主な貢献は、公共空間やデジタルプラットフォームの安全性向上を目指すAIツールにおいて、効率と明瞭性が共存し得ることを示した点にあります。
引用: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
キーワード: ビデオ監視, 暴力検出, 説明可能なAI, 注意機構型CNN, 公共の安全