Clear Sky Science · en
An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN
Why smarter video checks matter
Billions of hours of video stream from street cameras, stadiums, and social media every day. Hidden in this flood are brief moments of violence that matter deeply to police, security teams, and online platforms. Human operators cannot watch everything, and today’s artificial intelligence systems that flag dangerous scenes often work like black boxes: they may be accurate, but they rarely show why they decided a clip was violent. This paper introduces a new AI framework that not only spots violence quickly and accurately, but also highlights the parts of each frame that drove its decision, helping people trust and verify what the machine sees.
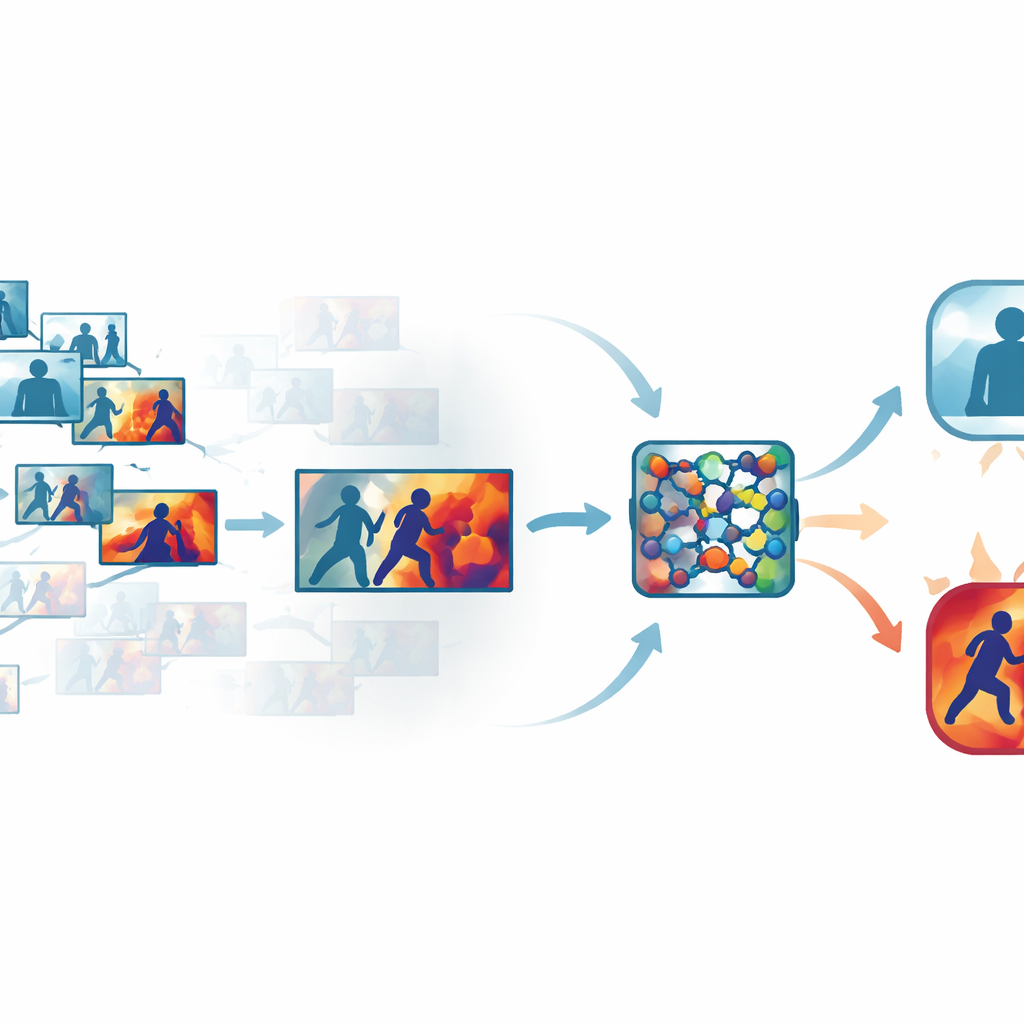
Cutting clutter from crowded video
Standard security footage contains many nearly identical frames, such as long stretches of people just walking or standing. Processing every frame wastes time and computing power, yet skipping too much can miss the split second when a punch is thrown. The authors tackle this by using an automated “keyframe” step that sifts through each clip and keeps only the frames that genuinely differ from one another. Instead of relying on simple time-based sampling, the system compares frames in a learned visual space, where subtle but meaningful changes in movement or posture stand out. On several public datasets, this approach kept only about one-third of the original frames while preserving the short bursts of motion that signal violence.
Teaching a network where to look
Once the most informative frames are chosen, they are sent through a compact convolutional neural network, a common image-recognition workhorse. Here the authors add attention modules that act like a spotlight inside the network. One part of this spotlight weighs which feature channels carry important motion and shape information, while another emphasizes the specific regions of each frame where interactions occur. Instead of treating all pixels and all internal signals as equally important, the network learns to focus on rapidly moving arms, bodies in close contact, and other telltale patterns, while downplaying static backgrounds, lighting changes, or camera shake. This makes the model both more accurate and more robust in messy, real-world scenes.
Making the machine’s reasoning visible
To avoid a black-box design, the framework builds in an interpretability layer known as Grad-CAM++. After the network makes a decision, this tool traces back through its internal activity to produce a heatmap over each frame, highlighting areas that most influenced the “violent” or “non-violent” verdict. In violent clips, the bright regions tend to cluster around physical contact points and intense motion; in calm clips, the highlights remain weak and diffuse. These visual explanations help operators confirm that the system is keying on meaningful behavior rather than irrelevant cues, and can also serve as supportive material in forensic review, where understanding how an algorithm reached its conclusion is as important as the conclusion itself.
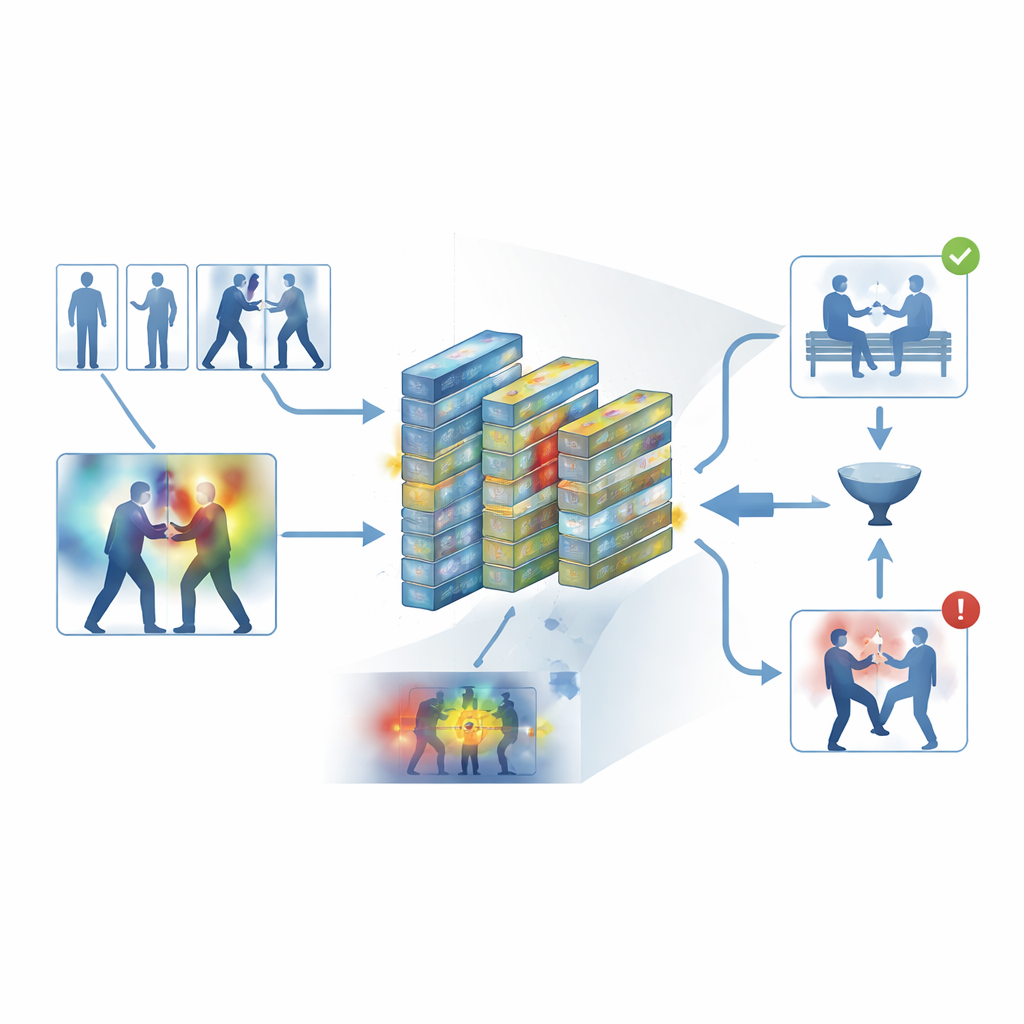
Putting the system to the test
The authors trained and evaluated their framework on five widely used datasets that span both everyday recordings and dedicated surveillance footage, including street altercations, hockey games, crowded campuses, and long security videos. Across these diverse sources, the system achieved an average accuracy of about 95 percent and processed around 62 frames per second on modern hardware—fast enough for real-time monitoring. It consistently beat several strong baselines, such as 3D convolutional networks, CNN–LSTM hybrids, and transformer-based video models, while using less memory. Careful experiments showed that both the keyframe filter and the attention modules made statistically significant contributions to performance, and that the model transferred reasonably well when trained on one dataset and tested on another.
What this means for safer, clearer monitoring
For non-specialists, the key message is that the authors have built a video violence detector that is not only fast and accurate, but also explainable. By stripping away redundant frames, focusing its internal attention on the most relevant motion, and then visualizing what it “looked at” to make each call, the system offers a more transparent partner for human overseers. In practical terms, this could help security centers and online platforms scan more feeds with fewer false alarms, while still allowing people to inspect and question the machine’s judgments. The work points toward future systems that combine video, audio, and newer temporal models, but its main contribution is showing that efficiency and clarity can coexist in AI tools designed to keep public spaces and digital platforms safer.
Citation: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
Keywords: video surveillance, violence detection, explainable AI, attention-based CNN, public safety