Clear Sky Science · ar
إطار تعلم عميق قابل للتفسير للكشف عن العنف في الفيديو باستخدام اختيار إطارات رئيسية غير خاضع للإشراف وشبكة التلافيف القائمة على الانتباه
لماذا تهم عمليات فحص الفيديو الأكثر ذكاءً
تُبث بلايين الساعات من الفيديو يوميًا من كاميرات الشوارع والملاعب ومواقع التواصل الاجتماعي. تختبئ في هذا الطوفان لحظات قصيرة من العنف تهم الشرطة وفرق الأمن والمنصات الإلكترونية على نحو كبير. لا يمكن للمشغّلين البشريين مشاهدة كل شيء، وأنظمة الذكاء الاصطناعي الحالية التي ترصد المشاهد الخطرة غالبًا ما تعمل كصناديق سوداء: قد تكون دقيقة، لكنها نادرًا ما توضّح سبب اعتبارها مقطعًا عنيفًا. يقدم هذا البحث إطار عمل ذكاء اصطناعي جديدًا لا يقتصر على اكتشاف العنف بسرعة ودقة، بل يبرز أيضًا أجزاء كل إطار التي دفعت القرار، مما يساعد الناس على الوثوق والتحقق من ما تراه الآلة.
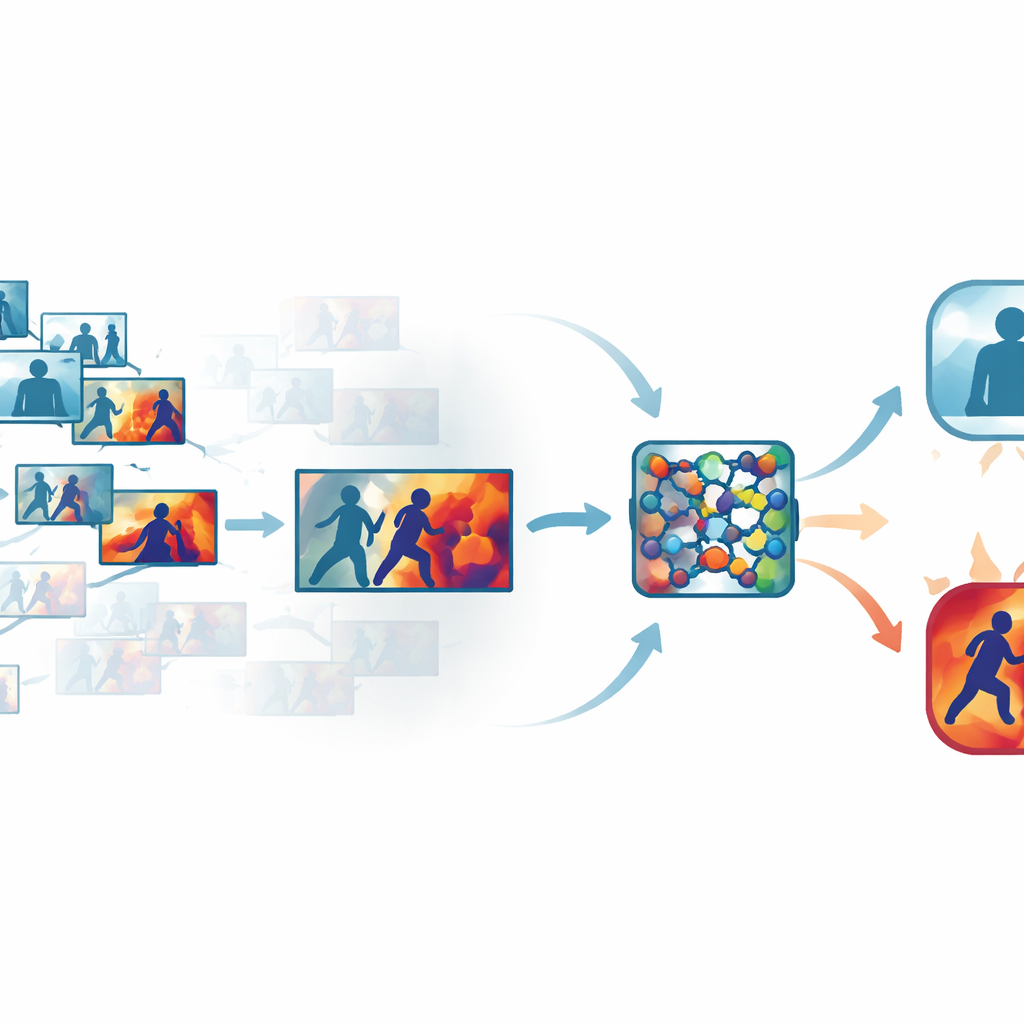
إزالة الفوضى من الفيديو المزدحم
تحتوي لقطات المراقبة الاعتيادية على العديد من الإطارات المتشابهة تقريبًا، مثل فترات طويلة من الأشخاص يمشون أو يقفون فقط. معالجة كل إطار تهدر الوقت وقدرة الحوسبة، ومع ذلك فإن الإفراط في التجاوز قد يفوت اللحظة التي يُوجَّه فيها لكمة. يتعامل المؤلفون مع هذا باستخدام خطوة آلية لاختيار "الإطارات الرئيسية" التي تنخّص كل مقطع وتحتفظ فقط بالإطارات التي تختلف بالفعل عن بعضها البعض. بدلًا من الاعتماد على أخذ عينات بسيط قائم على الزمن، يقارن النظام الإطارات في فضاء بصري متعلم، حيث تبرز التغيرات الطفيفة لكنها ذات دلالة في الحركة أو الوضعيات. على عدة مجموعات بيانات عامة، أبقت هذه الطريقة على نحو ثلث الإطارات الأصلية فقط مع الحفاظ على النبضات القصيرة من الحركة التي تشير إلى العنف.
تعليم الشبكة أين تنظر
بعد اختيار الإطارات الأكثر استنارة بالمعلومات، تُمرّر عبر شبكة عصبية تلافيفية مدمجة، وهي أداة شائعة للتعرف على الصور. هنا يضيف المؤلفون وحدات انتباه تعمل كمنارة داخل الشبكة. جزء من هذه المنارة يثّمن قنوات الميزة التي تحمل معلومات مهمة عن الحركة والشكل، بينما يبرز جزء آخر المناطق المحددة في كل إطار حيث تحدث التفاعلات. بدلًا من معاملة جميع البكسلات وجميع الإشارات الداخلية على أنها متساوية الأهمية، تتعلم الشبكة التركيز على الأذرع سريعة الحركة والأجساد في تلامس وثيق وأنماط أخرى دلّالة، مع تقليل أهمية الخلفيات الثابتة أو تغيّرات الإضاءة أو اهتزاز الكاميرا. هذا يجعل النموذج أكثر دقة ومتانة في المشاهد الفوضوية الواقعية.
إظهار منطق الآلة
لتجنب تصميم صندوق أسود، يبني الإطار طبقة قابلية تفسير تُعرف باسم Grad-CAM++. بعد أن يتخذ النموذج قراره، يتتبع هذا الأداة النشاط الداخلي ليُنتج خريطة حرارة فوق كل إطار، تُبرز المناطق التي أثّرت أكثر على الحكم بـ"عنيف" أو "غير عنيف". في المقاطع العنيفة، تميل المناطق الساطعة إلى التكتل حول نقاط الاتصال الجسدي والحركة المكثفة؛ وفي المقاطع الهادئة، تظل الإبرازات ضعيفة ومبعثرة. تساعد هذه التفسيرات البصرية المشغّلين على التأكد من أن النظام يركّز على سلوك ذي مغزى بدلًا من إشارات غير ذات صلة، ويمكن أن تُستخدم أيضًا كمادة داعمة في المراجعات الجنائية، حيث يكون فهم كيفية وصول الخوارزمية إلى استنتاجها مهمًا بقدر أهمية الاستنتاج نفسه.
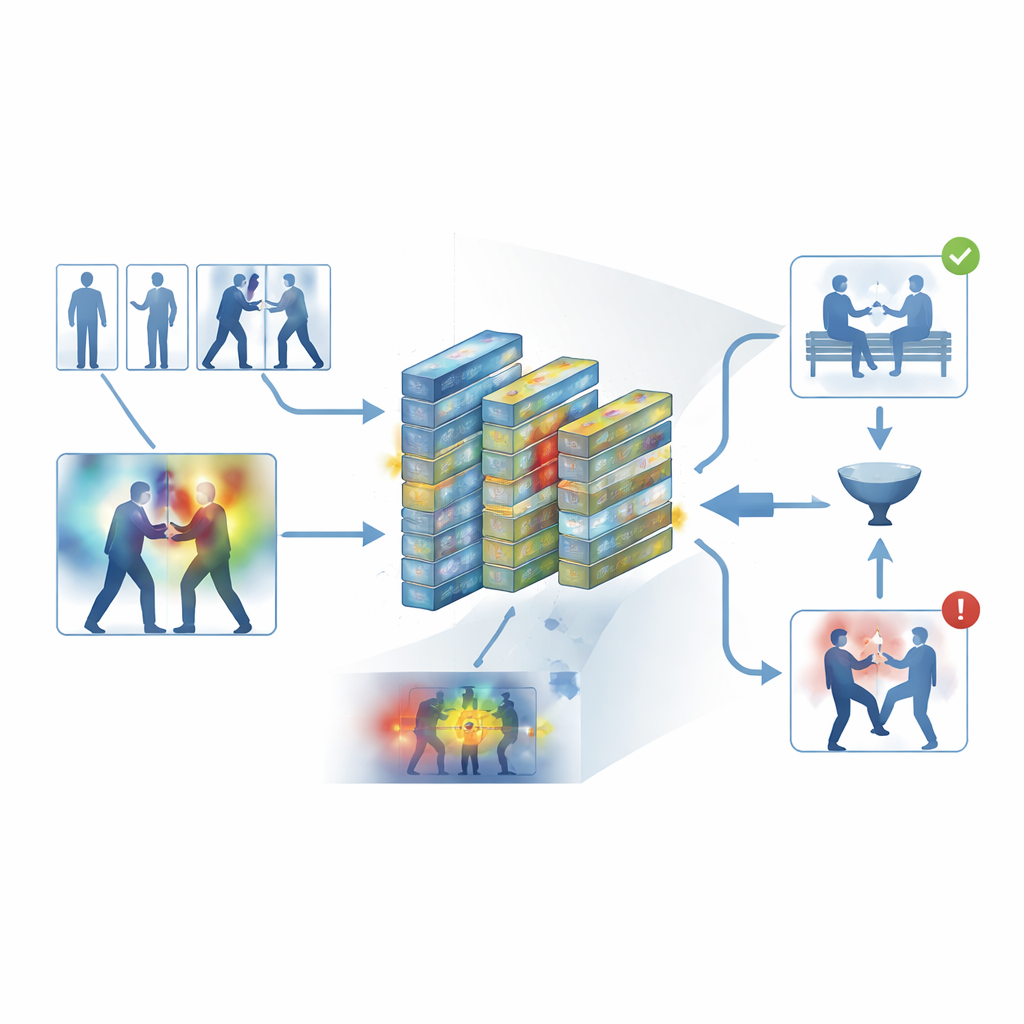
اختبار النظام
درّب المؤلفون وقيّموا إطارهم على خمس مجموعات بيانات مستخدمة على نطاق واسع تغطي كلًا من التسجيلات اليومية ولقطات المراقبة المخصصة، بما في ذلك مشاجرات الشوارع ومباريات الهوكي والحرم الجامعية المزدحمة وفيديوهات أمنية طويلة. عبر هذه المصادر المتنوعة، حقق النظام دقة متوسطة بنحو 95 بالمئة وعالج نحو 62 إطارًا في الثانية على الأجهزة الحديثة—سرعة كافية للمراقبة في الزمن الحقيقي. تفوّق باستمرار على عدة معايير قوية، مثل الشبكات الالتفافية ثلاثية الأبعاد، والهجائن CNN–LSTM، ونماذج الفيديو المبنية على المحولات، مع استخدام ذاكرة أقل. أظهرت التجارب الدقيقة أن كلاً من مرشح الإطارات الرئيسية ووحدات الانتباه قدما مساهمات ذات دلالة إحصائية في الأداء، وأن النموذج انتقل بشكل معقول عند تدريبه على مجموعة بيانات واختباره على أخرى.
ما الذي يعنيه هذا من أجل مراقبة أكثر أمانًا ووضوحًا
بالنسبة لغير المتخصصين، الرسالة الرئيسية هي أن المؤلفين بنوا كاشفًا للعنف في الفيديو غير سريع ودقيق فحسب، بل قابل للتفسير أيضًا. من خلال تجريد الإطارات الزائدة، وتركيز الانتباه الداخلي على الحركة الأكثر صلة، ثم تصور ما "نظرت إليه" الآلة لاتخاذ كل قرار، يقدم النظام شريكًا أكثر شفافية للمشرفين البشريين. عمليًا، قد يساعد هذا مراكز الأمن والمنصات الإلكترونية على فحص المزيد من الأشرطة مع إنذارات كاذبة أقل، مع السماح للأشخاص بمراجعة والتشكيك في أحكام الآلة. تشير هذه العمل إلى أنظمة مستقبلية تجمع بين الفيديو والصوت ونماذج زمنية أحدث، لكن المساهمة الأساسية هي إظهار أن الكفاءة والوضوح يمكن أن يتعايشا في أدوات الذكاء الاصطناعي المصممة لحفظ أماكن عامة ومنصات رقمية أكثر أمانًا.
الاستشهاد: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
الكلمات المفتاحية: مراقبة الفيديو, كشف العنف, الذكاء الاصطناعي القابل للتفسير, شبكة تلافيفية قائمة على الانتباه, السلامة العامة