Clear Sky Science · nl
Een uitlegbare deep learning-structuur voor geweldsdetectie in video met unsupervised keyframe-selectie en attention-gebaseerde CNN
Waarom slimmer videocontrole ertoe doet
Elke dag stromen miljarden uren video binnen van straatcamera’s, stadions en sociale media. Verborgen in deze vloed bevinden zich korte momenten van geweld die van groot belang zijn voor politie, beveiligingsteams en online platforms. Menselijke operators kunnen niet alles bekijken, en de huidige kunstmatige-intelligentiesystemen die gevaarlijke scènes signaleren werken vaak als zwarte dozen: ze kunnen nauwkeurig zijn, maar tonen zelden waarom ze een clip als gewelddadig bestempelden. Dit artikel introduceert een nieuw AI‑kader dat niet alleen geweld snel en nauwkeurig detecteert, maar ook de delen van elk frame markeert die de beslissing beïnvloedden, zodat mensen beter kunnen vertrouwen op en verifiëren wat de machine ziet.
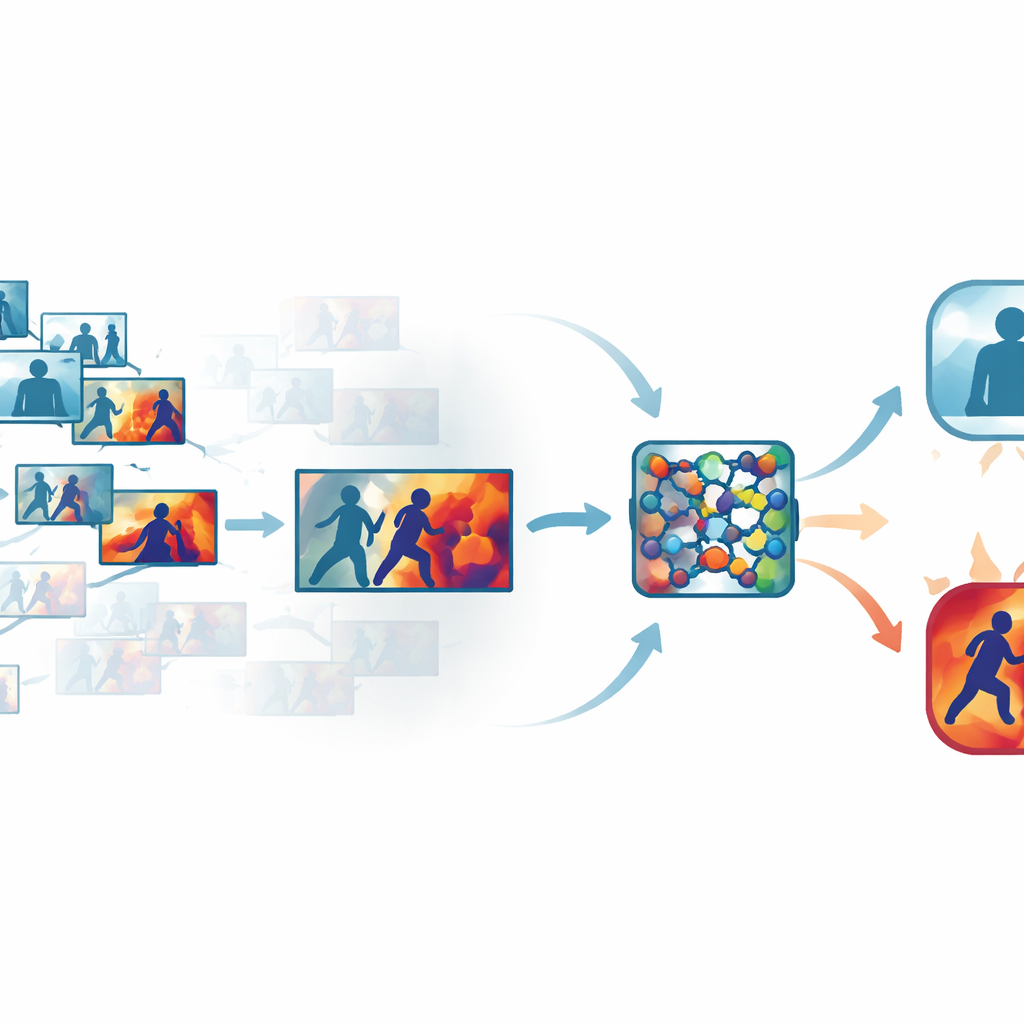
Rommel wegsnijden uit drukke video
Standaard beveiligingsbeelden bevatten veel vrijwel identieke frames, zoals lange periodes waarin mensen gewoon lopen of staan. Elk frame verwerken is tijd- en rekenintensief, maar te veel overslaan kan het splitsecond‑moment missen waarop een klap wordt uitgedeeld. De auteurs pakken dit aan met een geautomatiseerde “keyframe”-stap die elke clip doorzoekt en alleen die frames bewaart die daadwerkelijk van elkaar verschillen. In plaats van te vertrouwen op eenvoudige temporele sampling vergelijkt het systeem frames in een aangeleerde visuele ruimte, waar subtiele maar betekenisvolle veranderingen in beweging of houding beter opvallen. Op meerdere publieke datasets hield deze aanpak slechts ongeveer een derde van de originele frames over, terwijl korte bewegingsuitbarstingen die op geweld wijzen behouden bleven.
Een netwerk leren waar het moet kijken
Wanneer de meest informatieve frames zijn gekozen, worden ze door een compacte convolutionele neurale netwerk gestuurd, een gebruikelijke krachtpatser voor beeldherkenning. Hier voegen de auteurs attention‑modules toe die als een schijnwerper binnen het netwerk fungeren. Eén onderdeel weegt welke feature‑kanalen belangrijke informatie over beweging en vorm dragen, terwijl een ander de specifieke regio’s van elk frame benadrukt waar interacties plaatsvinden. In plaats van alle pixels en interne signalen gelijk te behandelen, leert het netwerk zich te concentreren op snel bewegende armen, lichamen in nauw contact en andere kenmerkende patronen, terwijl statische achtergronden, lichtveranderingen of cameratrillingen minder zwaar meewegen. Dit maakt het model zowel nauwkeuriger als robuuster in rommelige, realistische scènes.
De redenering van de machine zichtbaar maken
Om een black‑box‑ontwerp te vermijden, bouwt het kader een interpreteerbaarheidslaag in die bekendstaat als Grad‑CAM++. Nadat het netwerk een beslissing neemt, volgt dit hulpmiddel de interne activiteitsbrug terug om een heatmap over elk frame te produceren die de gebieden markeert die het meest bijdroegen aan het “gewelddadig” of “niet‑gewelddadig” oordeel. In gewelddadige clips clusteren de felle regio’s vaak rond punten van fysiek contact en intense beweging; in kalme clips blijven de highlights zwak en diffuus. Deze visuele verklaringen helpen operators te bevestigen dat het systeem zich richt op betekenisvol gedrag in plaats van irrelevante aanwijzingen, en kunnen ook dienen als ondersteunend materiaal bij forensische beoordelingen, waarbij het begrijpen van hoe een algoritme tot een conclusie kwam net zo belangrijk is als de conclusie zelf.
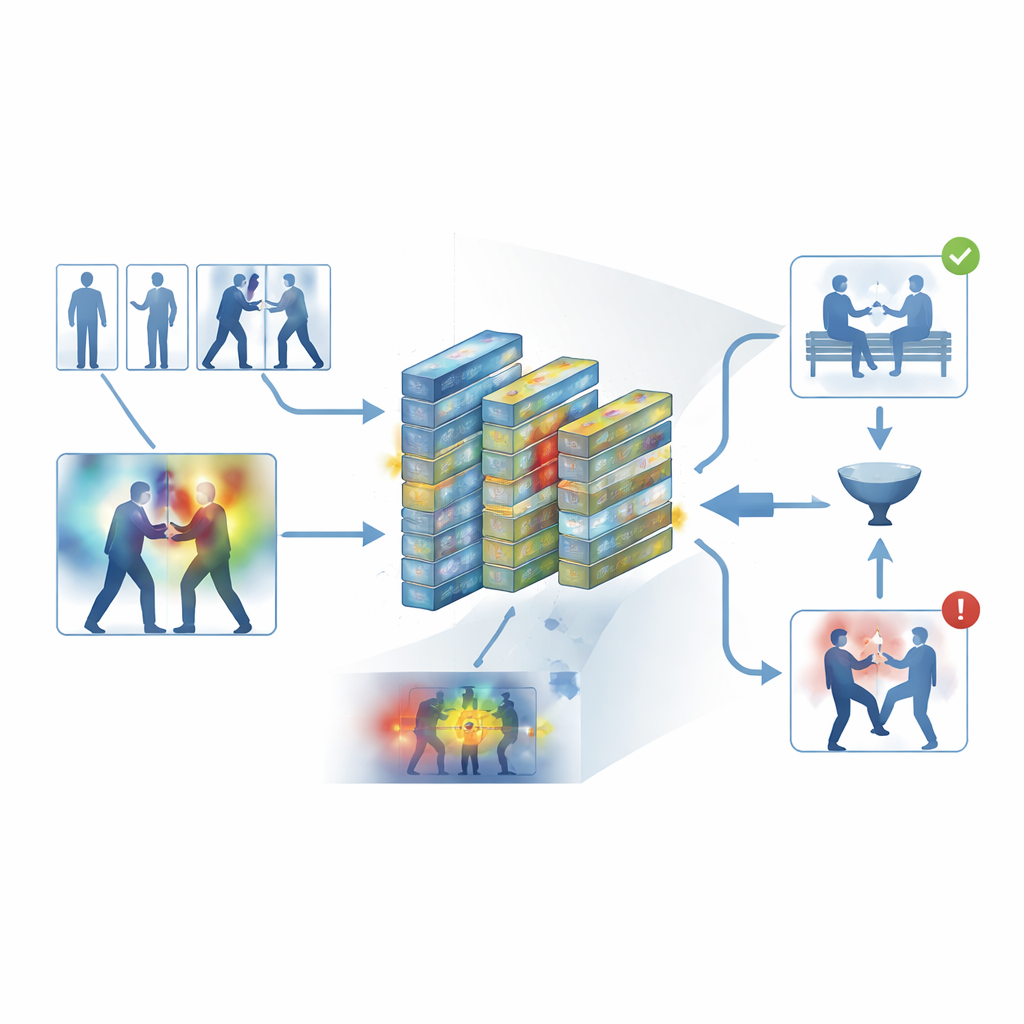
Het systeem op de proef stellen
De auteurs trainden en evalueerden hun kader op vijf veelgebruikte datasets die zowel alledaagse opnamen als gerichte bewakingsbeelden bestrijken, waaronder straatconflicten, hockeywedstrijden, drukke campussen en lange beveiligingsvideo’s. Over deze diverse bronnen behaalde het systeem een gemiddelde nauwkeurigheid van ongeveer 95 procent en verwerkte het circa 62 frames per seconde op moderne hardware — snel genoeg voor realtime bewaking. Het versloeg consequent verschillende sterke baselines, zoals 3D‑convolutionele netwerken, CNN–LSTM‑hybriden en transformer‑gebaseerde videomodellen, terwijl het minder geheugen gebruikte. Zorgvuldig opgezette experimenten toonden aan dat zowel de keyframe‑filter als de attention‑modules statistisch significante bijdragen leverden aan de prestaties, en dat het model redelijk goed overgedragen kon worden wanneer het op de ene dataset werd getraind en op een andere werd getest.
Wat dit betekent voor veiliger, transparanter toezicht
Voor niet‑specialisten is de kernboodschap dat de auteurs een detector voor geweld in video hebben gebouwd die niet alleen snel en nauwkeurig is, maar ook uitlegbaar. Door redundante frames weg te nemen, de interne aandacht te richten op de meest relevante bewegingen en vervolgens te visualiseren waarnaar het systeem “keek” om elke beslissing te nemen, biedt het systeem een transparantere partner voor menselijke toezichthouders. In de praktijk kan dit beveiligingscentra en online platforms helpen meer feeds te scannen met minder valse alarmen, terwijl mensen toch in staat worden gesteld de oordelen van de machine te controleren en aan te vechten. Het werk wijst op toekomstige systemen die video, audio en nieuwere temporele modellen combineren, maar de belangrijkste bijdrage is te laten zien dat efficiëntie en helderheid samen kunnen bestaan in AI‑instrumenten die ontworpen zijn om openbare ruimtes en digitale platforms veiliger te maken.
Bronvermelding: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
Trefwoorden: videosurveillance, geweldsdetectie, uitlegbare AI, attention-gebaseerde CNN, publieke veiligheid